






- 模型训练过程
- 准备数据集:训练集、测试集
- 预处理数据集(转化为模型可以运行处理的数据)
- 构建神经网络
- 定义损失函数、优化器
- 定义超参数:训练轮数(epochs)
- 编写迭代训练过程(GPU加速:网络模型、数据(输入集与标注集)、损失函数):每轮训练完成后进行测试计算精度:train_loss, train_acc, test_loss, test_acc
- 训练完成,保存训练模型参数数据
- 矩阵相邻元素计算方式

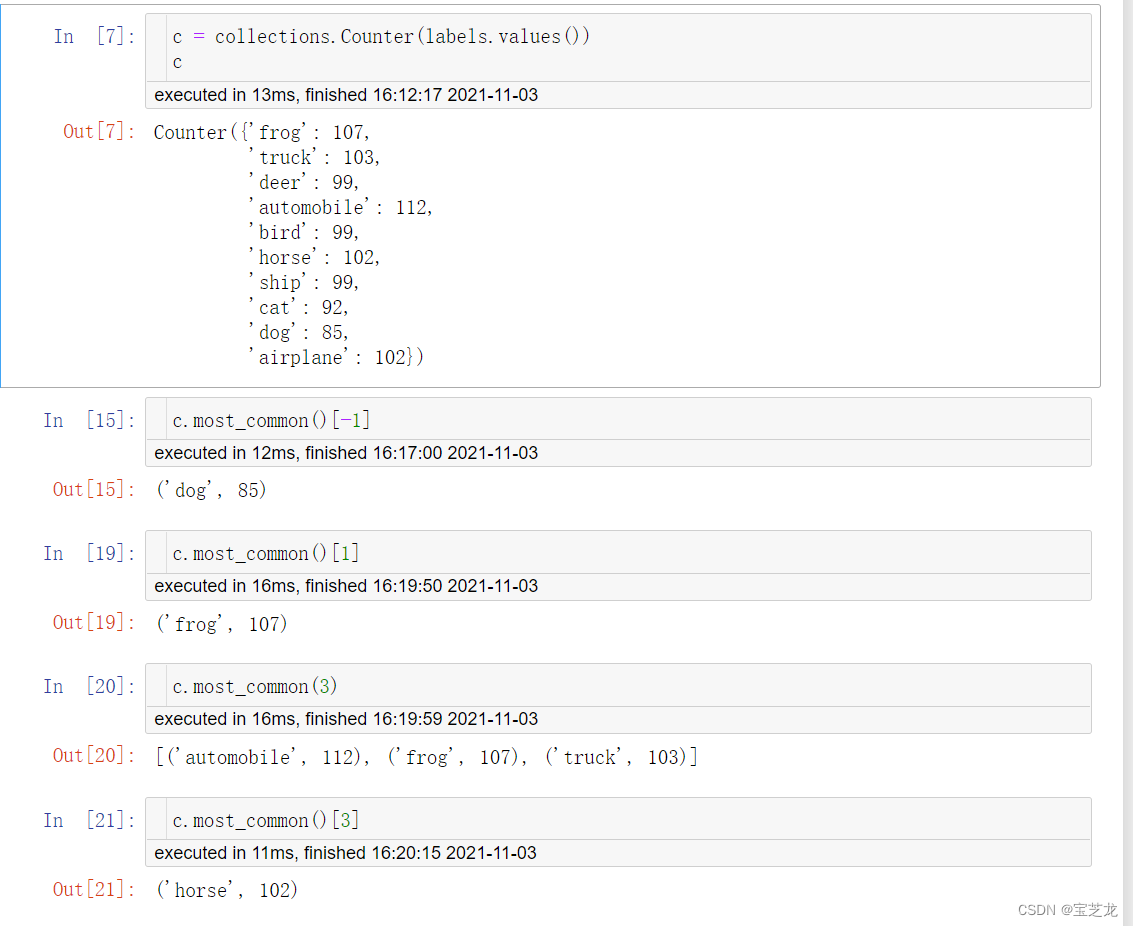
- 从字典中获取种类个数最少/最多/前n个/第k个的种类及个数

From colletions import counter

- Dateset与Dataloader中数据集的迭代过程-Transform运行机制
Transform发生在每一次迭代获取batch_size批量大小的数据集过程中
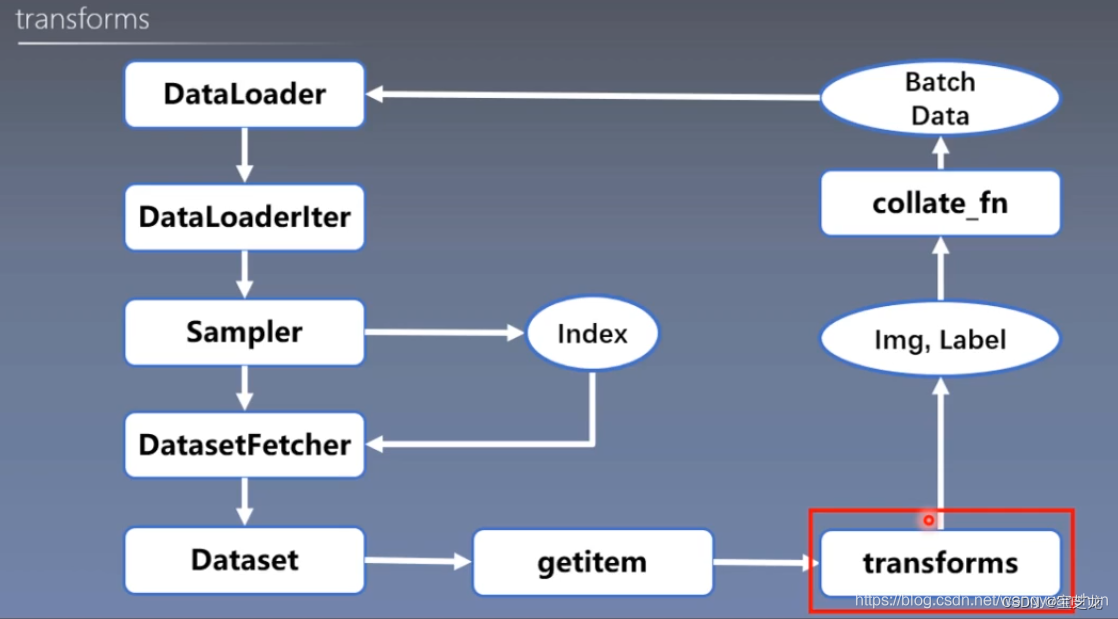
PyTorch的数据读取核心就是DataLoader。它分为两个子模块,Sample和DataSet。
Sample的功能是生成索引——Index即样本的序号;DataSet则是根据索引去读取图片等数据以及所属标签。

功能:构建可迭代的数据读取器。
dataset:Dataset类,决定数据从哪里读取以及如何读取。
batch_size:批大小
num_workers:是否多进程读取数据
shuffle:每个epoch是否乱序
drop_last:当样本数不能被batch_zise整除时,是否舍弃最后一批数据。
torch.utils.data.Dataset(object)
功能:Dataset抽象类,所有定义的Dataset需要继承它,并且复写__getitem__()
getitem: 接受一个索引,返回一个样本
- Epoch、Iteration、Batchsize 之间的关系
Epoch:所有训练样本都已输入到模型中,称为一个Epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
- (Transform发生在每一次迭代获取batch_size批量大小的数据集过程中)
- 训练tips
- 查看GPU使用情况
CMD执行指令:nvidia-smi
LINUX虚拟机执行指令:watch nvidia-smi(实时检测)
- 多输入通道卷积,多输入多输出通道卷积

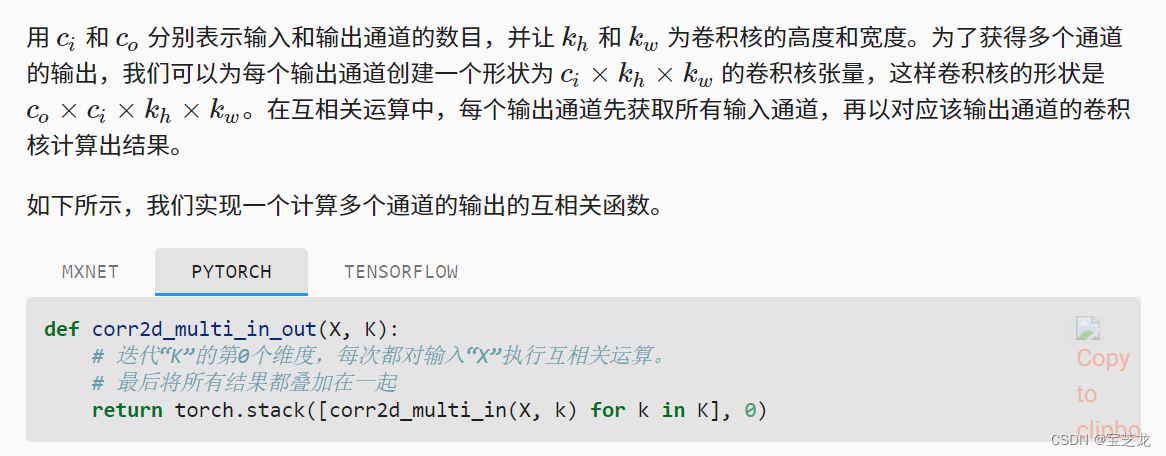
多输入多输出通道:for k in Kernnel: X <corr2(多通道输入互相关)> ki(Ci * kh * kw) =>Yi
Input X: Ci * nh * nw
Kernel k:Co * Ci * kh * kw
Output Y: Co * mh *mw
- 参数初始化可用到函数:
torch.rand(size,device)满足均匀分布
torch.randn(size, device)满足高斯/正态分布
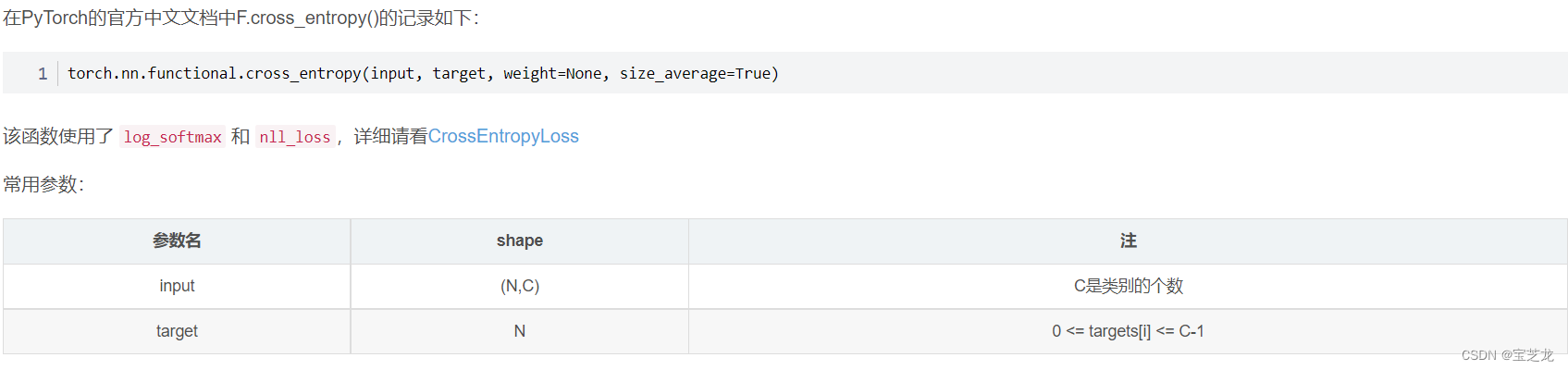
- Torch.nn.functional中cross_entropy 和nll_loss损失函数input 和target维度要求
- python中list.remove()的索引bug:
python中使用list的时候,通常需要用到移除其中某些元素,而remove函数就正好可以移除元素,所以就会想到循环遍历list,利用remove函数移除元素,例如下面一段代码:
| def remove_item(l,n): for item in l: if item==n: l.remove(item) if __name__ == "__main__": l = [1,2,3,3,3] print("before remove l:",l) remove_item(l,3) print("after remove l:",l) |
上面的一段代码期望实现的是删除list中等于3的元素,运行结果为:

删除之后仍然还有元素3,并没有完全删除,所以这种方法是有问题的,那么问题在哪呢?
那是因为list的遍历是基于下标的,当你删除其中的一个元素的时候,列表实际上已经发生了变化,该元素后面的所有元素都往前移动了一个位置,所以下次遍历的时候就会跳过该元素后面的一个元素,例子中的第二个3就被跳过了,这个3去填了移除的那个3的位置,所以第二个3不会被移除。
解决办法:方法很多,比如可以把不删除的元素重新添加到一个新的list中,也可以先拷贝一份列表备份,然后遍历备份列表,删除的时候就删除原列表,再或者基于索引遍历,当需要删除元素的时候,索引值对应减1,这些方法都可以根据自己需求选择。
- Tensor维度转换:
1、2-D Tensor既可以直接用转置.T,也可以用下述高维Tensor的的方法
2、高维Tensor有以下两种方法交换维度:
torch.Tensor.permute()
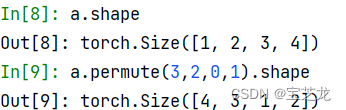
torch.transpose(x,dim1,dim2)指定两个维度
区别:transpose是torch的函数,permute是tensor的内置函数,一次性交换多个维度次序用permute,交换两个维度次序用上述两种方法均可。
- CNN技巧
- 卷积的运算实际就是利用若干大小的卷积核对输入矩阵进行卷积窗口大小的特征提取,从而给出新的特征。单层卷积层容易选入只能提取到边缘、局部和角特征的局面,所以一般会添加多层卷积层来确保学习到更多高维抽象的知识或者特征;
- 线性激活层的作用:1.生物神经元的信息编码通常是分散、稀疏的,使用简单的线性整流对模型的训练速度和效果有不错的改善;2.进行线性整流也是为了防止梯度下降的过程中出现梯度爆炸或者梯度消失的问题。
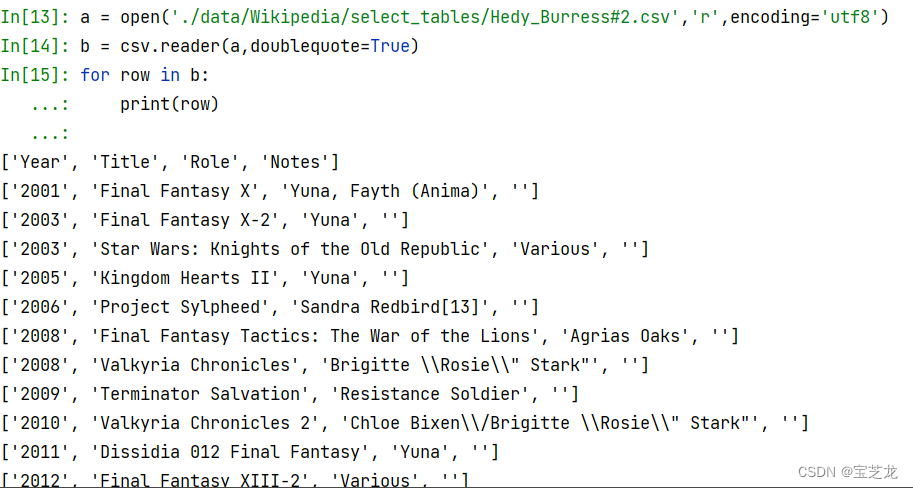
- 读取CSV文件遇到字段内用转义符\转义“双引号和\转义符本身的问题:
csv使用反斜杠(\)字符转义嵌入的双引号。
但是,默认情况下,默认csv模块使用双引号字符转义双引号字符。
您可以在csv.reader函数中设置escapechar参数。
大概是这样的:
csvFile = csv.reader(csv_file, delimiter='\t', escapechar='\\')
csv内容:

默认读取:
Escapechar=”\\”后:

- python for嵌套机制
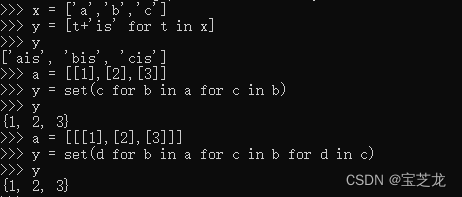
连续嵌套时需先从大往小写,这样要找到b中的c时你才能先知道b是什么,见下图
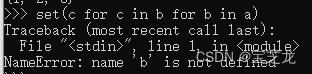
若不先遍历a就不知道b是什么,因此遍历b中的c语句失效。
- Python-pickle模块
pickle模块是Python专用的持久化模块,可以持久化包括自定义类在内的各种数据,比较适合Python本身复杂数据的存贮。但是持久化后的字串是不可认读的,并且只能用于Python环境,不能用作与其它语言进行数据交换。把 Python 对象直接保存到文件里,而不需要先把它们转化为字符串再保存,也不需要用底层的文件访问操作,直接把它们写入到一个二进制文件里。pickle 模块会创建一个 Python 语言专用的二进制格式,不需要使用者考虑任何文件细节,它会帮你完成读写对象操作。用pickle比你打开文件、转换数据格式并写入这样的操作要节省不少代码行。
在pickle中dumps()和loads()操作的是bytes类型,而在使用dump()和load()读写文件时,要使用rb或wb模式,也就是只接收bytes类型的数据。
- pickle.dump(obj, file) 将Python数据转换并保存到pickle格式的文件内。
Eg: withopen('data.pickle', 'wb') as f: pickle.dump(data, f)
- pickle.dumps(obj) 将Python数据转换为pickle格式的bytes字串。
- pickle.load(file) 从pickle格式的文件中读取数据并转换为Python的类型。
Eg: withopen('data.pickle', 'rb') as f:data = pickle.load(f)
- pickle.loads(bytes_object) 将pickle格式的bytes字串转换为Python的类型。

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









