







 本文介绍了机器学习中训练数据和测试数据的作用,强调泛化能力的重要性。通过训练数据调整模型参数,测试数据评估模型性能,避免过拟合。文章探讨了损失函数,特别是均方误差在神经网络学习中的应用,并提供了Python实现示例。
本文介绍了机器学习中训练数据和测试数据的作用,强调泛化能力的重要性。通过训练数据调整模型参数,测试数据评估模型性能,避免过拟合。文章探讨了损失函数,特别是均方误差在神经网络学习中的应用,并提供了Python实现示例。
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。比如,在识别手写数字的问题中,泛化能力可能会被用在自动读取明信片的邮政编码的系统上。此时,手写数字识别就必须具备较高的识别“某个人”写的字的能力。注意这里不是“特定的某个人写的特定的文字”,而是“任意一个人写的任意文字”。如果系统只能正确识别已有的训练数据,那有可能是只学习到了训练数据中的个人的习惯写法。
因此,仅仅用一个数据集去学习和评价参数,是无法进行正确评价的。这样会导致可以顺利地处理某个数据集,但无法处理其他数据集的情况。顺便说一下,只对某个数据集过度拟合的状态称为过拟合(over fitting)。
神经网络以某个指标为线索寻找最优权重参数。神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
可以用作损失函数的函数有很多,其中最有名的是均方误差(mean squared error)。
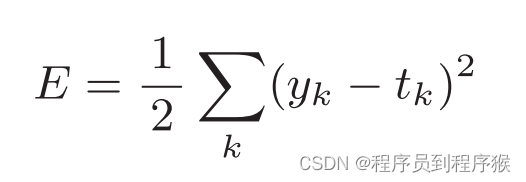
这里,yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。
在手写数字识别的例子中,yk、tk是由如下10个元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









