









1、基础概念
在最开始,先梳理一下经常被提到的几个术语的区别和联系,也就是Graph Embedding,Graph Neural Network和Graph Convolutional Network的区别和联系是什么。
Graph Embedding
图嵌入(Graph Embedding/Network Embedding,GE),属于表示学习的范畴,也可以叫做网络嵌入,图表示学习,网络表示学习等等。通常有两个层次的含义:
- 将图中的节点表示成低维、实值、稠密的向量形式,使得得到的向量形式可以在向量空间中具有表示以及推理的能力,这样的向量可以用于下游的具体任务中。例如用户社交网络得到节点表示就是每个用户的表示向量,再用于节点分类等;
- 将整个图表示成低维、实值、稠密的向量形式,用来对整个图结构进行分类;
图嵌入的方式主要有三种:
- 矩阵分解:基于矩阵分解的方法是将节点间的关系用矩阵的形式加以表达,然后分解该矩阵以得到嵌入向量。通常用于表示节点关系的矩阵包括邻接矩阵,拉普拉斯矩阵,节点转移概率矩阵,节点属性矩阵等。根据矩阵性质的不同适用于不同的分解策略。
- DeepWalk:DeepWalk 是基于 word2vec 词向量提出来的。word2vec在训练词向量时,将语料作为输入数据,而图嵌入输入的是整张图,两者看似没有任何关联。但是 DeepWalk的作者发现,预料中词语出现的次数与在图上随机游走节点被访问到底的次数都服从幂律分布。因此 DeepWalk把节点当做单词,把随机游走得到的节点序列当做句子,然后将其直接作为 word2vec的输入可以节点的嵌入表示,同时利用节点的嵌入表示作为下游任务的初始化参数可以很好的优化下游任务的效果,也催生了很多相关的工作;
- Graph Neural Network:图结合deep learning方法搭建的网络统称为图神经网络GNN,也就是下一小节的主要内容,因此图神经网络GNN可以应用于图嵌入来得到图或图节点的向量表示;
Graph Neural Network
图神经网络(Graph Neural Network, GNN)是指神经网络在图上应用的模型的统称,根据采用的技术不同和分类方法的不同,从传播的方式来看,图神经网络可以分为图卷积神经网络(GCN),图注意力网络(GAT,缩写为了跟GAN区分),Graph LSTM等等,本质上还是把文本图像的那一套网络结构技巧借鉴过来做了新的尝试。
Graph Convolutional Network
图卷积神经网络(Graph Convolutional Network, GCN)正如上面被分类的一样,是一类采用图卷积的神经网络,发展到现在已经有基于最简单的图卷积改进的无数版本,在图网络领域的地位正如同卷积操作在图像处理里的地位。
这三个比较绕的概念可以用一句话来概括:图卷积神经网络GCN属于图神经网络GNN的一类,是采用卷积操作的图神经网络,可以应用于图嵌入GE。
2、CNN与GCN
卷积VS图卷积
要理解图卷积网络的核心操作图卷积,可以类比卷积在CNN的地位。
如下图所示,数字图像是一个二维的离散信号,对数字图像做卷积操作其实就是利用卷积核(卷积模板)在图像上滑动,将图像点上的像素灰度值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素的灰度值,并最终滑动完所有图像的过程。
用随机的共享的卷积核得到像素点的加权和从而提取到某种特定的特征,然后用反向传播来优化卷积核参数就可以自动的提取特征,是CNN特征提取的基石。
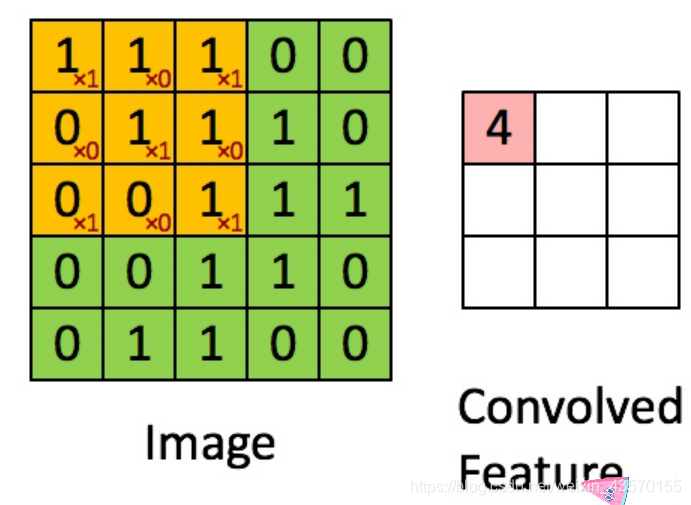
然而,现实中更多重要的数据集都是用图的形式存储的,例如社交网络信息,知识图谱,蛋白质网络,万维网等等。这些图网络的形式并不像图像,是排列整齐的矩阵形式,而是非结构化的信息,那有没有类似图像领域的卷积一样,有一个通用的范式来进行图特征的抽取呢?这就是图卷积在图卷积网络中的意义。
对于大多数图模型,有一种类似通式的存在,这些模型统称GCNs。因此可以说,图卷积是处理非结构化数据的大利器,随着这方面研究的逐步深入,人类对知识领域的处理必将不再局限于结构化数据( CV,NLP),会有更多的目光转向这一存在范围更加广泛,涵盖意义更为丰富的知识领域。
如图:

3、GCN
GCN也是一个神经网络层,它的层与层之间的传播方式是:
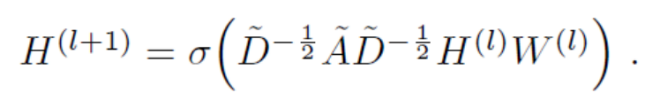
这个公式中:
- A波浪=A+I,I是单位矩阵
- D波浪是A波浪的度矩阵(degree matrix),公式为
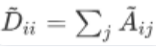
- H是每一层的特征,对于输入层的话,H就是X
- σ是非线性激活函数
简单解释下,GCN的每一层通过邻接矩阵A和特征矩阵H(l)相乘得到每个顶点邻居特征的汇总,然后再乘上一个参数矩阵 W(l)加上激活函数 σ做一次非线性变换得到聚合邻接顶点特征的矩阵 H(l+1)。
之所以邻接矩阵A要加上一个单位矩阵I,是因为我们希望在进行信息传播的时候顶点自身的特征信息也得到保留。
而对邻居矩阵 A波浪 进行归一化操作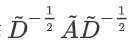
是为了信息传递的过程中保持特征矩阵H的原有分布,防止一些度数高的顶点和度数低的顶点在特征分布上产生较大的差异。
4、实现代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import networkx as nx
def normalize(A , symmetric=True):
# A = A+I
A = A + torch.eye(A.size(0)) #torch.eye这个函数主要是为了生成对角线全1,其余部分全0的二维数组
# 所有节点的度
#print(A)
d = A.sum(1)
#print(d)
#print("-----------------------------")
if symmetric:
#D = D^-1/2
D = torch.diag(torch.pow(d , -0.5))
return D.mm(A).mm(D) ##--------------------------------------------------------------
else :
# D=D^-1
D =torch.diag(torch.pow(d,-1))
return D.mm(A)
class GCN(nn.Module): # 用Module构造出来的对象,会根据里面的计算图自动的实现backward过程,也可以自己构建
'''
Z = AXW
'''
def __init__(self , A, dim_in , dim_out): #构造函数
super(GCN,self).__init__() #调用副类的init
self.A = A
self.fc1 = nn.Linear(dim_in ,dim_in,bias=False) #Linear自动完成权重乘以输入加上偏置
self.fc2 = nn.Linear(dim_in,dim_in//2,bias=False)
self.fc3 = nn.Linear(dim_in//2,dim_out,bias=False)
def forward(self,X): #前馈过程中进行的计算计算
X = F.relu(self.fc1(self.A.mm(X)))
X = F.relu(self.fc2(self.A.mm(X)))
return self.fc3(self.A.mm(X))
#获得空手道俱乐部数据
G = nx.karate_club_graph()
A = nx.adjacency_matrix(G).todense()
#A需要正规化
A_normed = normalize(torch.FloatTensor(A),True)
N = len(A)
X_dim = N # ------>34
# 没有节点的特征,简单用一个单位矩阵表示所有节点
X = torch.eye(N,X_dim)
# 正确结果
Y = torch.zeros(N,1).long()
# 计算loss的时候要去掉没有标记的样本
Y_mask = torch.zeros(N,1,dtype=torch.uint8)
# 一个分类给一个样本
Y[0][0]=0
Y[N-1][0]=1
#有样本的地方设置为1
Y_mask[0][0]=1
Y_mask[N-1][0]=1
#真实的空手道俱乐部的分类数据
Real = torch.zeros(34 , dtype=torch.long)
for i in [1,2,3,4,5,6,7,8,11,12,13,14,17,18,20,22] :
Real[i-1] = 0
for i in [9,10,15,16,19,21,23,24,25,26,27,28,29,30,31,32,33,34] :
Real[i-1] = 1
# 我们的GCN模型
gcn = GCN(A_normed ,X_dim,2)
#选择adam优化器
gd = torch.optim.Adam(gcn.parameters())
for i in range(300):
#转换到概率空间
y_pred =F.softmax(gcn(X),dim=1)
#下面两行计算cross entropy
loss = (-y_pred.log().gather(1,Y.view(-1,1)))
#仅保留有标记的样本
loss = loss.masked_select(Y_mask).mean()
#梯度下降
#清空前面的导数缓存
gd.zero_grad()
#求导
loss.backward()
#一步更新
gd.step()
if i%20==0 :
_,mi = y_pred.max(1)
print(mi)
#计算精确度
print((mi == Real).float().mean())

















 8863
8863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









