







 本文解析了如何利用one-hot标签计算分类概率,并通过实例讲解了y_hat.argmax()和交叉熵损失函数在预测准确率计算中的作用。重点介绍了torch.view()和flatten方法的区别,以及如何在PyTorch中使用CrossEntropyLoss。
本文解析了如何利用one-hot标签计算分类概率,并通过实例讲解了y_hat.argmax()和交叉熵损失函数在预测准确率计算中的作用。重点介绍了torch.view()和flatten方法的区别,以及如何在PyTorch中使用CrossEntropyLoss。
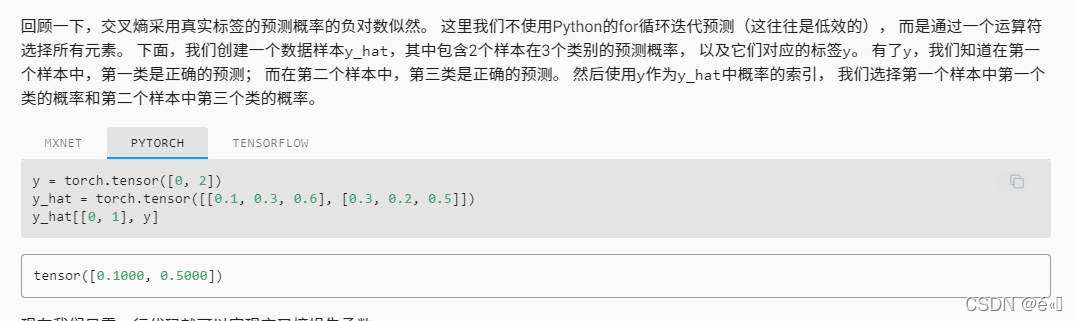
对于一个样本使用它的one-hot标签能获得它的正确分类的概率,方便后面使用交叉熵:
cmp = y_hat.type(y.dtype) == y
对于yhat中的每一行,也就是每一张图片,找到它的最大值,并且用它的Index来表示。所以y_hat就可以表示为tensor([2,2])
y_hat.argmax(axis=1)解释没有参数时,是默认将数组展平,当axis=1,是在行中比较,选出最大的 列 索引
这也就是代码中y_hat = y_hat.argmax(axis=1)的意义。
对于接下来的一行,
cmp = y_hat.type(y.dtype) == y其实就是先把y_hat换成和y一样的数据类型,然后比较y_hat和y是否在每一个位置上的值相等。y之前的类型是troch.in64
y与y_hat进行比较
第一个位置不等,第二个位置相等,也就是说第一张图片预测错误,第二章图片预测正确。所以我们得到[False, True],代码中用了cmp来表示。而在Python里,False是0,True是1,所以可以用[0,1]表示,所以最后的求和
float(cmp.type(y.dtype).sum())的结果就是看有多少个1,也就是有多少张图片预测正确。所以这个结果除以预测的总图片数y,就是预测的准确率。
对于这里的2张图片,预测对了1张,所以准确率是50%


isinstance(net,nn.Module)
函数isinstance()可以判断一个变量的类型,既可以用在Python内置的数据类型如str、list、dict,也可以用在我们自定义的类,它们本质上都是数据类型。
pytorch中view()和flatten和reshape()
view()和flatten都是和输入共享内存的,flatten的好处是不用输入形状参数,直接指定维度,在这之后的都被拉平。view则是更加灵活
torch.reshape(input, shape) → Tensor
flatten()直接展开为一行
loss = nn.CrossEntropyLoss() #调用CrossE时自动调用softmax



















 6405
6405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









