







一:原理讲解
架构图
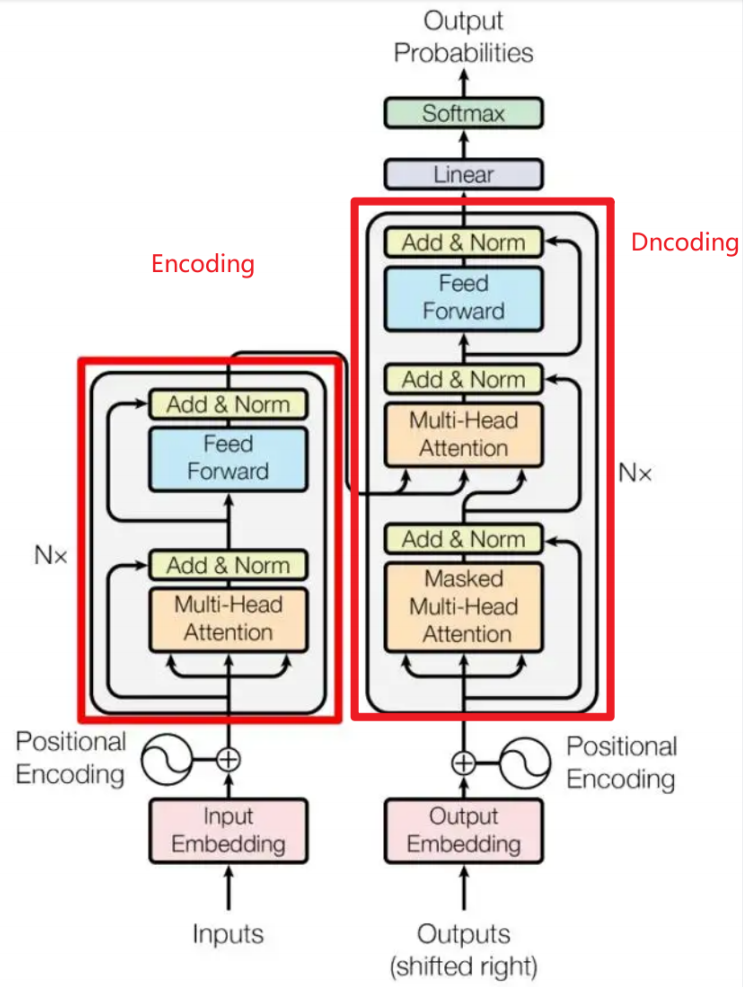
添加图片注释,不超过 140 字(可选)
Input Embedding

仅包含三个句子

N 表示总数,最后的结果是去重之后的词汇量
1.1 Tokenization
- Token 是指文本中的一个基本单元,通常是词或短语。这个切分 token 的过程,称为分词(Tokenization)。 Tokenization 的本质其实就是一个字符到数字的映射,其维护的是一个字典,而不是权重,也就是说每一个字符/词/短语都有一个唯一确定的数字与其对应。
- 词粒度
- 词粒度基本是最直观的分词手段了,也是最符合我们平时认知的方式。每一个 token 是词典中的一个词。 - 优点: - 符合人类的直觉,词的含义完备。 - 对于拉丁语系很简单,按照空格和标点符号分割即可。 - 缺点: - 对于中文日文,需要专门进行分词,比如中文分词一般都用 jieba(结巴分词),哈工大的 LTP 等。 - 如何构造一份好的词典,以及词典过大的问题。 - OOV (Out of Vocabulary)问题,对于词典中没有词一般会分配一个统一来处理,信息丢失。 - 同义词和误拼会被认为是不同的词。比如 do not 和 don’t 虽然含义一样,但是最终的 id 不一样。类似的还有词的不同形态,比如 have, has, had, having 等。 - 词典中的词没有任何关联,低频词不会得到充分的训练。比如 oarfish,这个词虽然第一眼可能不知道什么意思,但是能猜出是一种鱼(皇带鱼)。
- 子粒度
- 把文本按照最小粒度来拆分,对于英文来说就是 26 个字母加上一些标点符号。中文来说就是字。 - 优点: - 实现简单。 - 词典很小。 - 几乎没有 OOV (Out of Vocabulary)问题 - 缺点: - 对于英文来说,单个字母几乎没有含义。 - 难以学习到词汇的真正含义。由于中文的一个字还是有一定的含义,所以在中文勉强可以使用,但是英文几乎没法使用。 - 会让输入变得很长,训练和推理更慢。
- Embedding
- 核心是为了向量化
- 假设我们现在有一个词库(词汇表),里面有五个词[ I , love , programming , in, Python ],我们通过索引下标将其标识出来分别对应[1, 2, 3, 4 , 5],但是这样的表示方法,基本很难帮助我们去发现他们之间的关系,比如相似性、多义性,所以我们引入向量空间,帮助我们更好表示不同词token,one-hot就是其中一种:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









