







一:yarn出现损坏的nodemanger
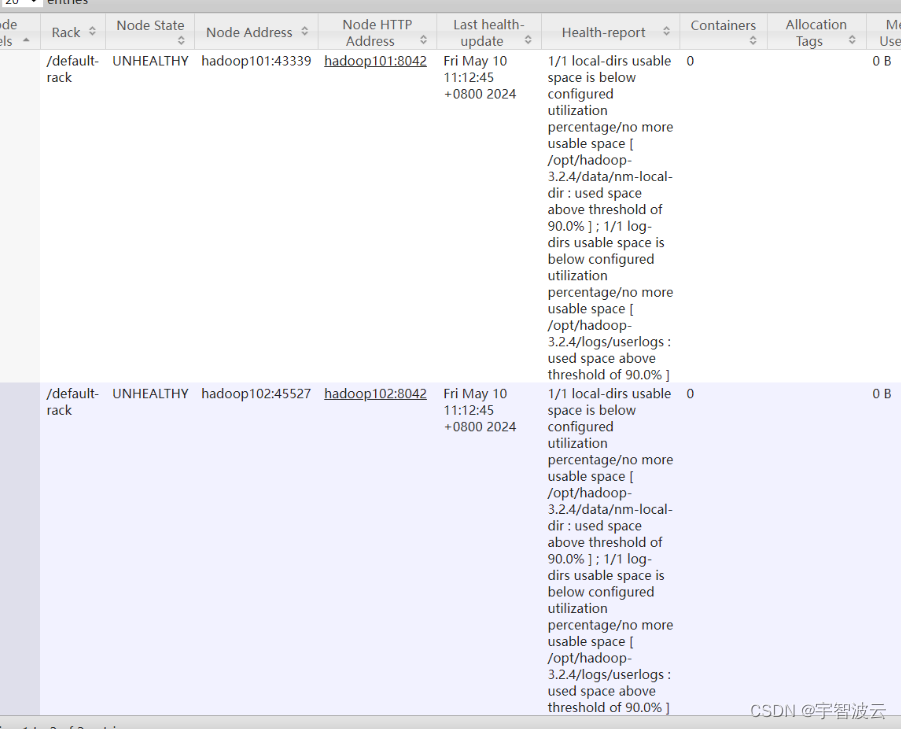
报错现象
日志:1/1 local-dirs usable space is below configured utilization percentage/no more usable space [ /opt/hadoop-3.2.4/data/nm-local-dir : used space above threshold of 90.0% ] ; 1/1 log-dirs usable space is below configured utilization percentage/no more usable space [ /opt/hadoop-3.2.4/logs/userlogs : used space above threshold of 90.0% ]
问题解析
yarn在启动服务的时候,需要加载文件资源到本地目录,目前显示本地目录资源使用百分之九十,没有办法在继续写入。
解决方案
- 在路径下增加磁盘资源
- 重新定位新的目录
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nodemanagerlog</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/log_dirs</value>
</property>
二:yarn资源配置
三个节点
内存 64g,80g,80g
核数 16,20,20
增加yarn资源调整参数
每个节点的参数可以设置不同
<!-- 这台服务器可以提供给yarn的核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>20</value>
</property>
<!-- 这台服务器可以提供给yarn的内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>61440</value>
</property>
<!-- 容器可以配置的最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器可以配置的最大内存 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>60000</value>
</property>
<!-- 容器可以配置的最大核数 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>40</value>
</property>

/opt/flink-1.13.6/bin/flink run -m yarn-cluster -ys 20 -yjm 60000 -ytm 60000 -d -c com.shds.platform.cyberspace.CyberspaceParseJob /root/collection-cyberspace-1.0-SNAPSHOT.jar
三:插入hbase出现反压
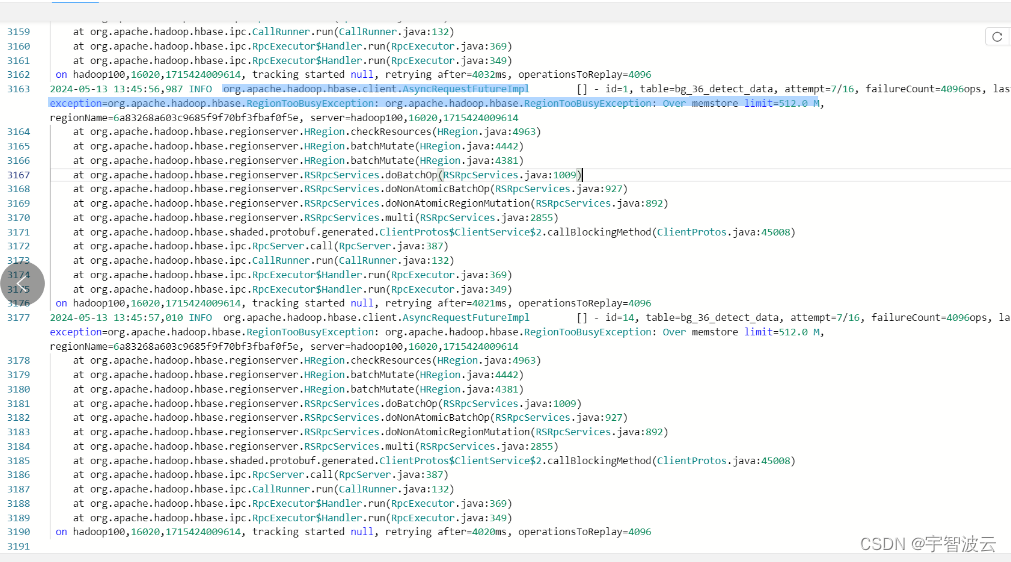
报错信息
org,apache.hadoop.hbase.client,AsyncRequestFutureImplexception=org.apache,hadoop.hbase.RegionTooBusyException: org.apache,hadoop.hbase,RegionTooBusvException: Over memstore limit=512.8 M
报错原因
问题出现在刷盘的时候,当menstore满了的时候,会将数据存储到hfile。当插入的时候是不能写入的。所以导致了这个问题。
解决方案
很多方案,最笼统的直接增加regionserver的资源大小进行重启。
vim hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-Xms4G -Xmx8G"
四:关闭yarn资源检查
<property>
<name>yarn.nodemanager.resource.percentage-physical-cpu-limit</name>
<value>-1</value>
<description>Percentage of physical CPU that can be allocated for containers. -1 means no limit. </description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>

五:搭建hive,在hadoop100上启动命令,报错元数据启动不起来。
报错现象 FAILED:HiveException java.lang.RuntimeException: Unable to instantiate org.apache…

解决方法
在哪台机器上配置了这个参数,就在哪台机器上启动
<!-- 指定 hive.metastore.uris 的 port,为了启动 MetaStore 服务的时候不用指定端口 -->
<!-- hive ==service metastore -p 9083 & | hive ==service metastore -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop101:9083</value>
</property>
这里配置了hadoop101,所以在Hadoop100上启动,就不行。
五:不同网段之间kafka进行相互传输数据
Caused by: org.apache.kafka.common.errors.TimeoutException: Batch containing 1 record(s) expired due to timeout while requesting metadata from brokers for ffff-0
解决方式
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.2.13:9092

六:flink jm报错:scheduler is being stopped
在使用yarn session的时候,指定jm的大小,增加资源就可以。
yarn-session.sh -nm test -jm 2g -tm 10g -s 4 -d
七:flink寻找对应任务的checkpoint
flink list -r
https://blog.youkuaiyun.com/weixin_43446246/article/details/129667021
八:flink yarnsession模式提交,参数没有起作用
yarn session错误的提交命令
yarn-session.sh -nm test -jm 2g -tm 10g -s 4 -d
错误原因 在help中,没有-n 的选项,所以在错误的获取到一个命令的时候,就会自动去配置文件中选取默认参数。导致外部传入的参数没有获取到
九:使用kvm虚拟机,物理主机网卡1000,虚拟机网卡100问题
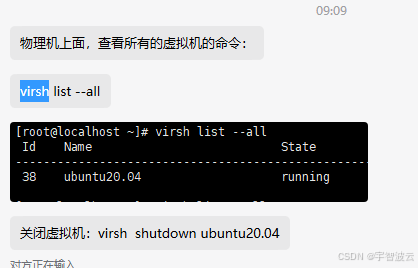
将三个.xml的文件进行修改
把<model type='virtio'/>修改成<model type='e1000'/>
然后 virsh define ****.xml 使这个配置生效,然后重启这个虚拟机就可以了
重启三个虚拟机
启动虚拟机: virsh start xxxx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









