



一:为什么学习spark?
相比较map-reduce框架,spark的框架执行效率更加高效。
mapreduce的执行框架示意图。
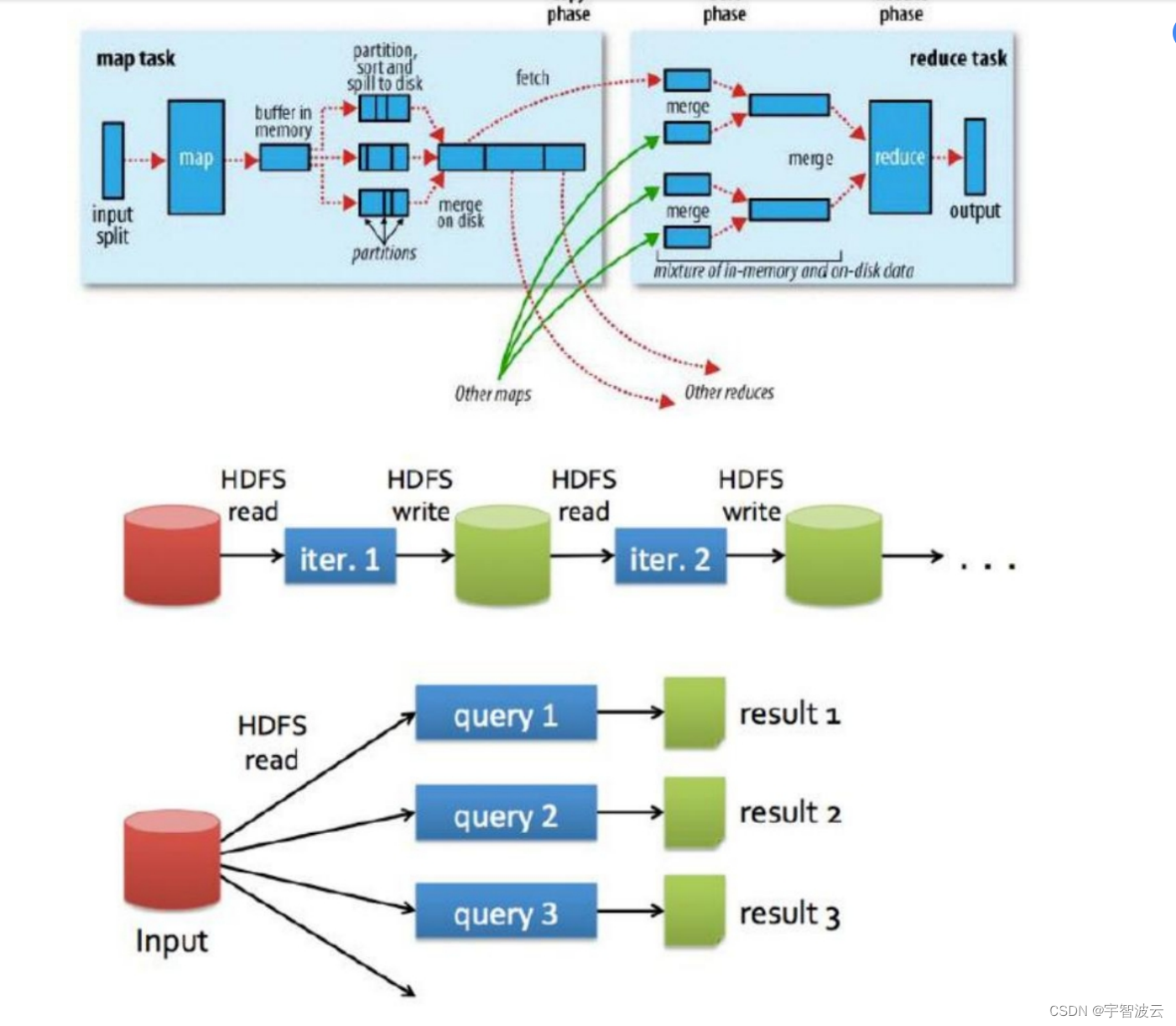
spark执行框架示意图
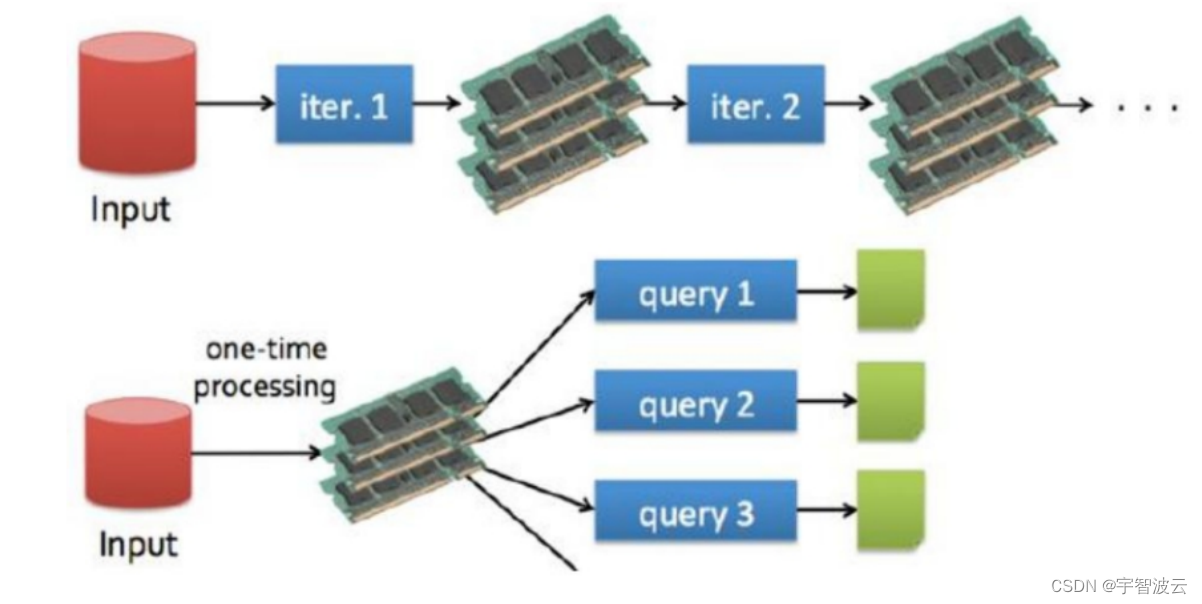
spark的执行中间结果是存储在内存当中的,而hdfs的执行中间结果是存储在hdfs中的。所以在运算的时候,spark的执行效率是reduce的3-5倍。
二:spark是什么?
spark是一个执行引擎。
三:spark包含哪些内容?
1. spark core。
spark RDD五大特性。
1. RDD是由一系列partition组成的。
每个rdd中,partition的个数和由hdfs中的map的个数决定的。和map的个数保持一致。
2. 每个RDD会提供最佳的计算位置。
3. 每个函数会作用在每个partition上。
算子
- 转换算子
常见 Transformation 类算子
filter :过滤符合条件的记录数, true 保留, false 过滤掉。
map :将一个 RDD 中的每个数据项,通过 map 中的函数映射变为一个新的元素。特点:输入
一条,输出一条数据。
flatMap :先 map 后 flat 。与 map 类似,每个输入项可以映射为0到多个输出项。
sample 随机抽样算子,根据传进去的小数按比例进行有放回或者无放回的抽样。
reduceByKey 将相同的 Key 根据相应的逻辑进行处理。
sortByKey / sortBy 作用在 K,V格式的RDD 上,对 key 进行升序或者降序排序。 - 行动算子
count :返回数据集中的元素数。会在结果计算完成后回收到 Driver 端。
take(n) :返回一个包含数据集前 n 个元素的集合。
first :效果等同于 take(1) ,返回数据集中的第一个元素。
foreach :循环遍历数据集中的每个元素,运行相应的逻辑。
collect :将计算结果回收到 Driver 端 - 持久化算子
cache:默认将 RDD 的数据持久化到内存中。 cache 是懒执行。
checkpoint:checkpoint 将 RDD 持久化到磁盘,还可以切断 RDD 之间的依赖关系,也是懒执行。
4. RDD之间相互依赖。
RDD的宽窄依赖。
一对一的就是窄依赖。
一对多的就是宽依赖。
在计算进行切割的时候,会将所有的窄依赖放在一起,成为一个stage。放在一个TaskScheduler中进行计算。
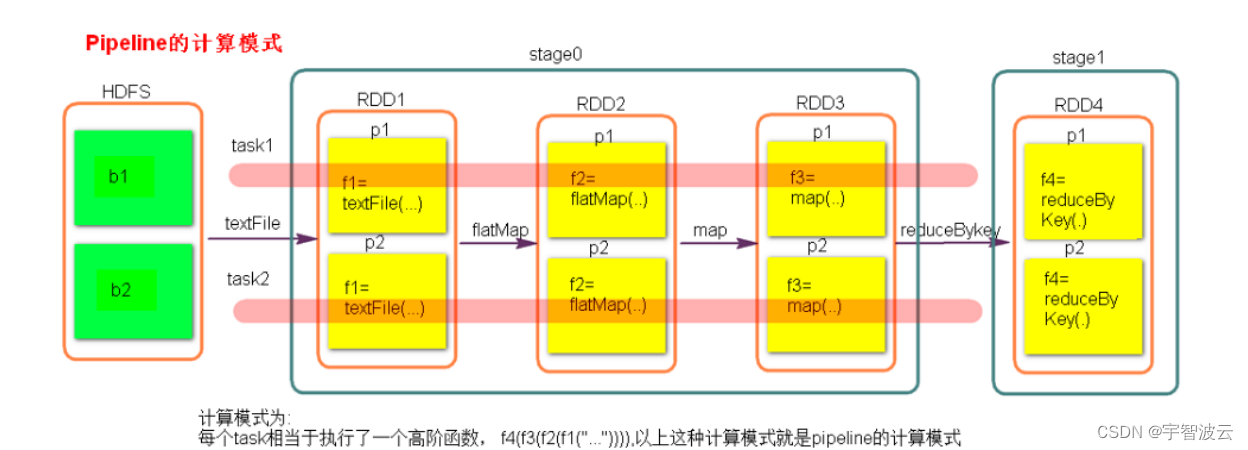
5. 分区器是作用在 (K,V) 格式的 RDD 上。
shuffle
HashShuffle
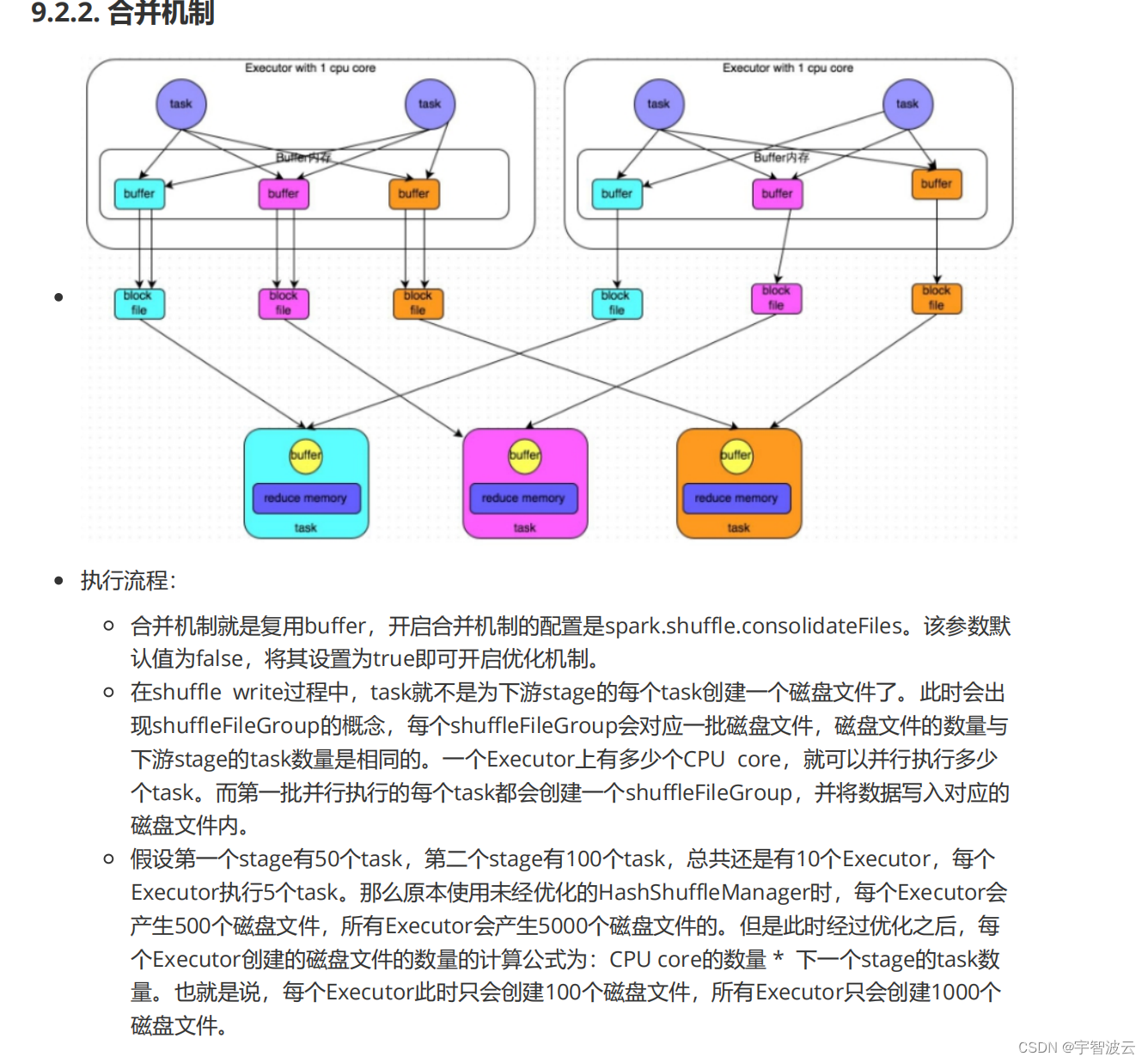
SortShuffle
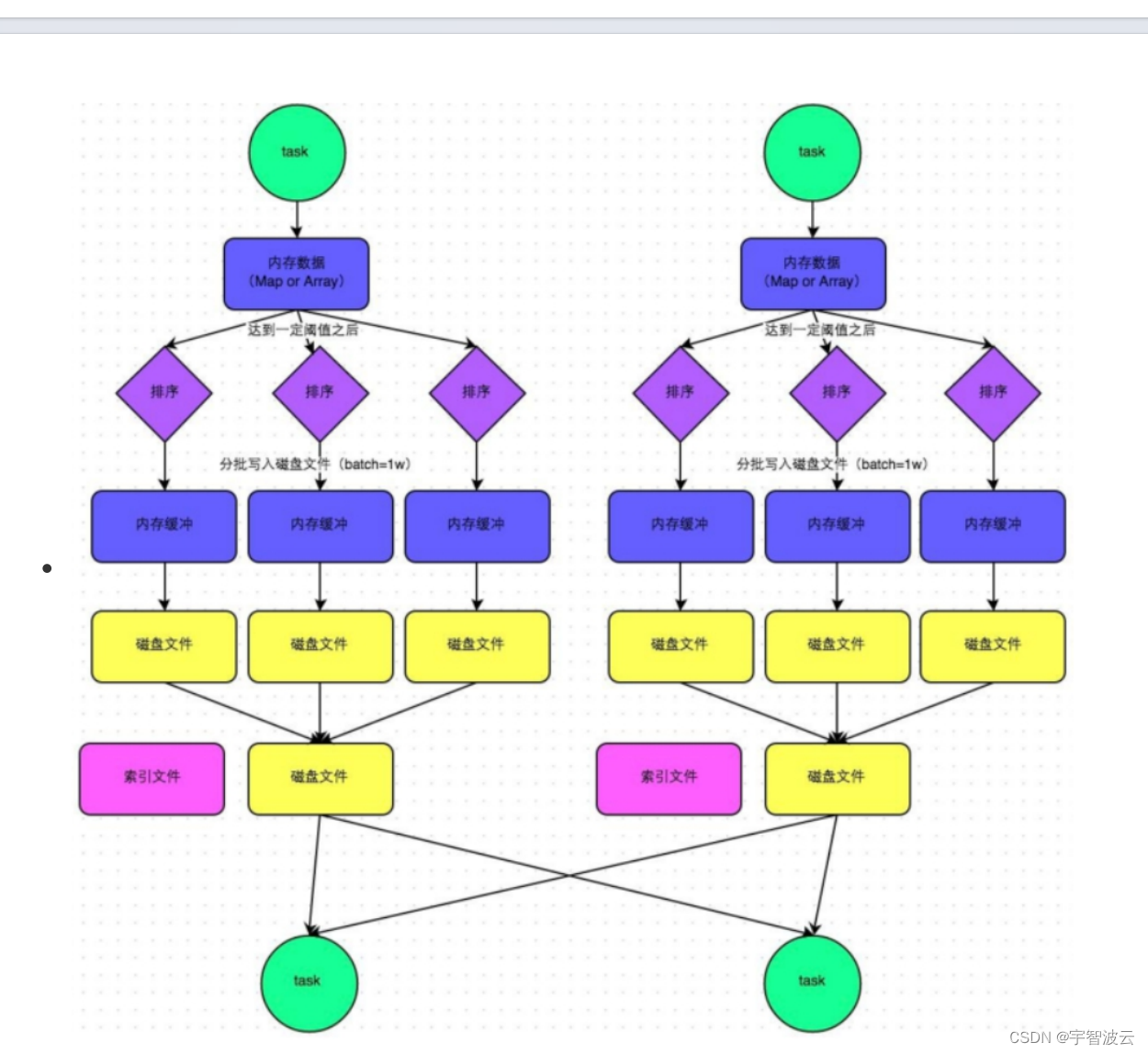

bypass机制
shuffle map task的数量小于spark.shuffle.sort.bypassMergeThreshold参数的值(默认200)或者不是聚合类的shuffle算子(比如groupByKey)

Shuffle文件寻址

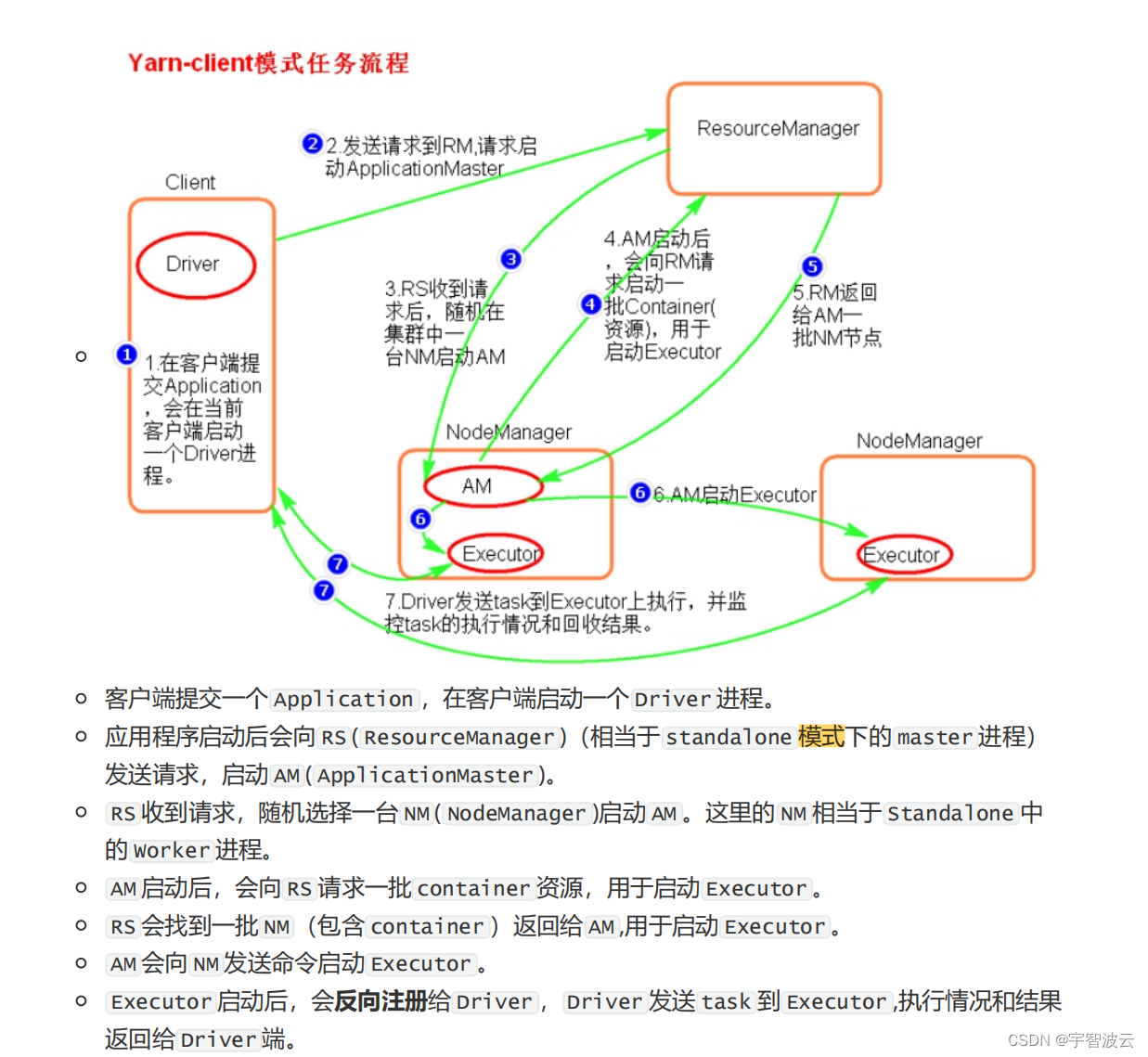
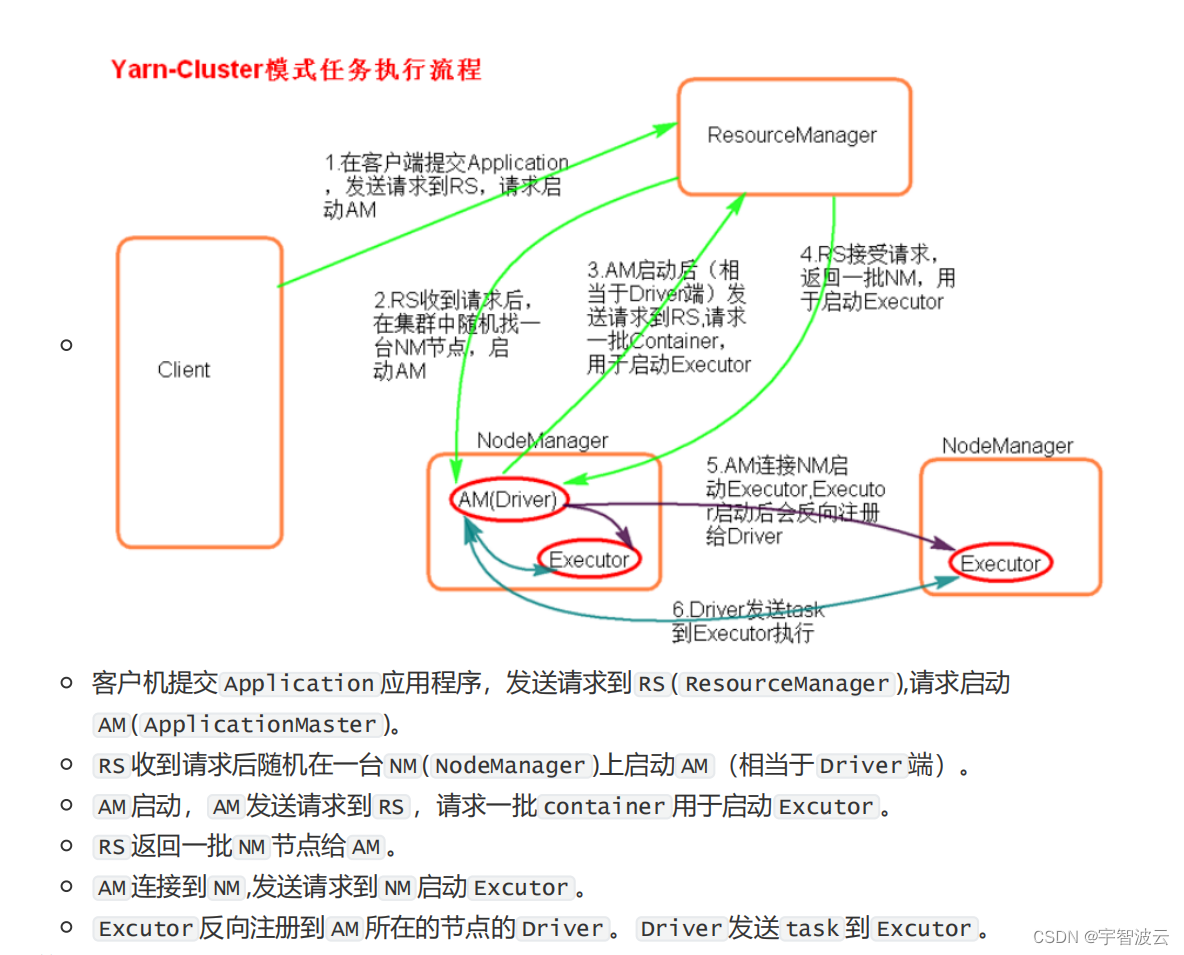
2. spark的俩种提交模式。
用于测试
用于生产

2. spark sql。
- RDD和dataFromes和dataset。
dataset包含dataFormes,dataFormes包含RDD。 - Spark on hive 和hive on spark
Spark on hive 中,hive是存储,spark负责sql的优化和解析。
hive on Spark中,Hive即作为存储又负责sql的解析优化,Spark负责执行。

















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









