







 本文是Spark初学者指南,详细介绍了Spark的定义、速度优势及内存占用,重点讲解了弹性分布式数据集(RDD)的特性、Transformation算子如map、filter、sample等以及Action算子,还探讨了SparkSQL的基础概念和编程入门。
本文是Spark初学者指南,详细介绍了Spark的定义、速度优势及内存占用,重点讲解了弹性分布式数据集(RDD)的特性、Transformation算子如map、filter、sample等以及Action算子,还探讨了SparkSQL的基础概念和编程入门。
目录
1.6 SparkCount的典型案例(真我瞎写的,非官方)
2.3.8 saveAsTextFile和saveAsHadoopFile和saveAsObjectFile和saveAsSequenceFile
3.3 RDD Dataframe DataSet之间的转换
1 Spark的介绍
1.1 Spark的定义
它是一个集成了离线计算、实时计算、SQL查询、机器学习、图计算为一体的一站式框架 。
一站式的体现:既可以做离线计算(批处理),也可以做其他的(SQL查询、机器学习、图计算)
flink对于机器学习、图计算支持真的的不太友好哈。
1.2 Spark为什么比MapReduce快?
因为Spark是基于内存计算,Spark运行起来只有一次Suffle,但是MapReduce存在两次Suffle。
1.3 RDD 弹性式分布式数据集
- 弹性式:Spark运行时导致内存溢出,会把数据落地到磁盘上,并不会导致数据丢失。
- 数据集:其实就是一个存放数据的地方,可以认为是一个不可变的Scala集合。
- RDD的特点: 只读、可分区、分布式的数据集。这个数据集全部或者一部分可以缓存在内存中(这里有个小Tips:就是缓存内存就是对RDD做了持久化操作哦),在多次计算时被重用。
- RDD的存在:RDD的计算和数据保存都在Worker上(Spark的集群模式是主从架构,一个Master调度N个Worker)。RDD是分区的,每个分区分布在集群中的不同Worker节点上面,这样的好处就是RDD可以并行式计算。
- RDD的来源:可以读取HDFS或者hive中的数据,也可以自己创建(makeRDD)。
- 有关MapReduce:
- 好处:自动容错、负载均衡、高扩展
- 坏处:采用非循环的数据列模型,进行计算的时候数据迭代进行大量的磁盘IO流。
- 但是Spark避免了MapReduce的坏处,采用血缘追溯,通过执行时产生的有向无环图,找到数据故障的partition,提高容错性。
- 有关RDD的封装:spark2.X版本RDD已经被封装了,我们做开发的时候不会使用rdd,而是直接使用DataSet或者DataFrame进行计算。
1.4 MasterURL
spark编程是通过SparkConf.setMaster传递线程运行的参数,以及是线程采用什么模式
| master | 含义 | |
|---|---|---|
| local | 程序在本地运行,同时为本地程序提供一个线程来处理spark程序 | |
| local[M] | 程序在本地运行,同时为本地程序提供M个线程来处理spark程序 | |
| local[*] | 程序在本地运行,同时为本地程序提供当前计算机CPU Core数个线程来处理spark程序 | |
| local[M,N] |
|
|
| spark://ip:port |
|
|
| spark://ip1:port1,ip2:port2 | 基于Standalone ha模式运行,spark程序提交到ip和port对应的master上运行 | |
| yarn [deploy-mode=cluster] | yarn的集群模式(一般是生产环境中使用)。 基于yarn模式运行,基于yarn的cluster模式,这个程序会被提交给yarn集群中的resourceManager,然后有RM分配给对应NodeMananger执行 |
|
| yarn [deploy-mode=client] | yarn的客户端模式(一般是生产环境中做测试时使用) 基于yarn模式运行,基于yarn的client模式,只会在提交spark程序的机器上运行 |
|
1.5 Spark为什么很占内存?
因为Spark运行的时候,每个job的运行阶段都会存在副本,即使运行完了也依然存在内存中,所以很占用内存。
1.6 SparkCount的典型案例(真我瞎写的,非官方)
idea中的pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark_sz2102</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 声明公有的属性 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.7.6</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<!-- 声明并引入公有的依赖 -->
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<!-- 配置构建信息 -->
<build>
<!-- 资源文件夹 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<!-- 声明并引入构建的插件 -->
<plugins>
<!-- 用于编译Scala代码到class -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<!-- 程序打包 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<!-- 过滤掉以下文件,不打包 :解决包重复引用导致的打包错误-->
<filters>
<filter><artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<!-- 打成可执行的jar包 的主方法入口-->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
在resource中放一个log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
自己创建了一个文档
a.txt的内容
hello word
hello hadoop
hello jdk
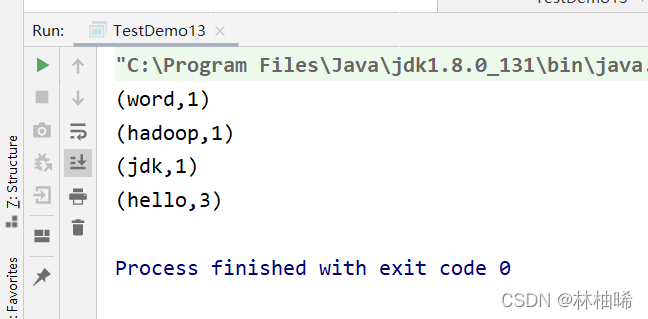
统计的代码
package com.qf.bigdata
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TestDemo13 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
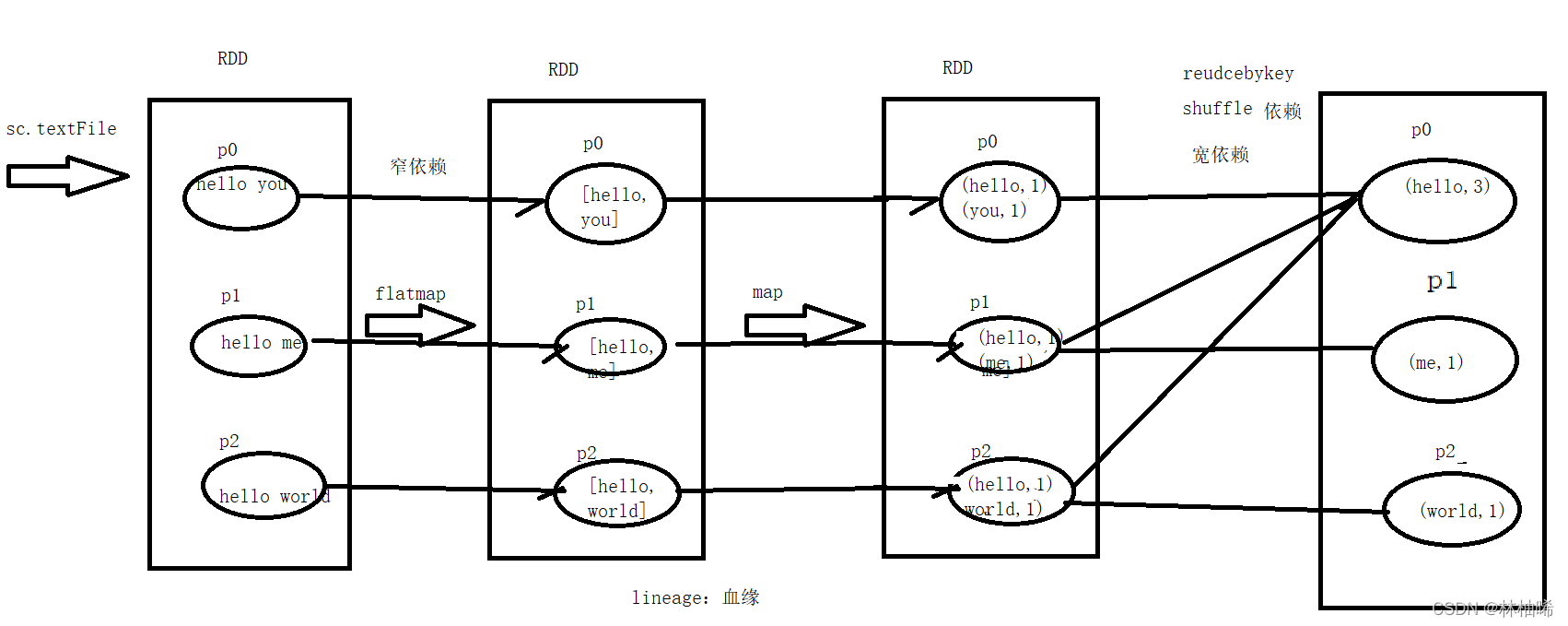
val lines:RDD[String] = sc.textFile("D:/data/a.txt")
val words:RDD[(String,Int)]=lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
words.foreach(println)
sc.stop()
}
}
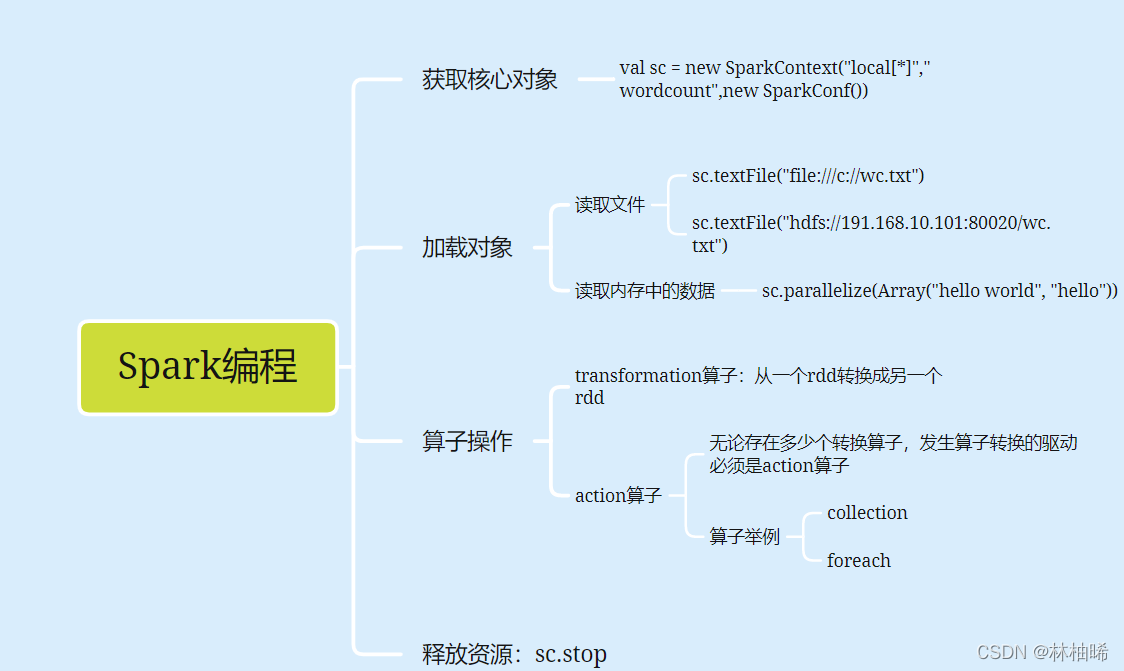
1.7 spark代码的核心框架(指的是main方法里的)
对于countword程序的画图理解
2 RDD的那些事
2.1 介绍RDD
- 每个spark应用程序都包含了一个驱动程序,该程序驱动了功能在集群上执行各种操作。
- RDD只是一个抽象的逻辑定义,不是真实存在的。
- RDD是一个跨集群节点的集合,处理数据可以并行操作。
- RDD可以实现现有的scala集合进行转换创建RDD。
- Spark可以把RDD持久化,并行操作中可以高效复用。
- RDD快速恢复数据是通过血缘追溯,找到分区中的数据故障,快速恢复数据,提高容错性。
- RDD的共享变量:主要是广播变量和累加器。对于不同节点并行运行同一个算子,会把算子中使用的每个变量的副本传送给每个任务,任务之间需要共享变量。
2.2 Transformation算子
2.2.1 map算子
def map[U: ClassTag](f: T => U): RDD[U]
U : 表示f函数的返回值类型
T : 表示RDD中的元素类型的返回值
RDD[U] :通过map算子处理之后的返回类型,返回的RDD[U],这里说明map处理之后返回的是一个新的RDD的副本,RDD的副本中的元素类型是由我们的U类型决定
f : 函数
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
val arrRDD:RDD[Array[String]] = txtRDD.map(_.split("\\s+"))
arrRDD.foreach(println)
}
}
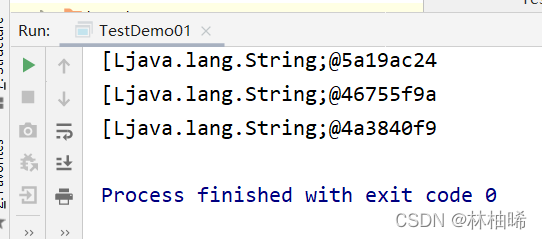
2.2.2 flatmap算子
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
TraversableOnce[U]: 表示f函数的返回值类型,TraversableOnce就把它看作为一个集合即可
U : 表示f函数返回值类型的一个元素的类型
T : 表示RDD中的元素类型的返回值
RDD[U] :通过map算子处理之后的返回类型,返回的RDD[U],这里说明map处理之后返回的是一个新的RDD的副本,RDD的副本中的元素类型是由我们的U类型决定
f:函数
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
val flatMapRDD:RDD[String] = txtRDD.flatMap(_.split("\\s+"))
flatMapRDD.foreach(println)
}
}
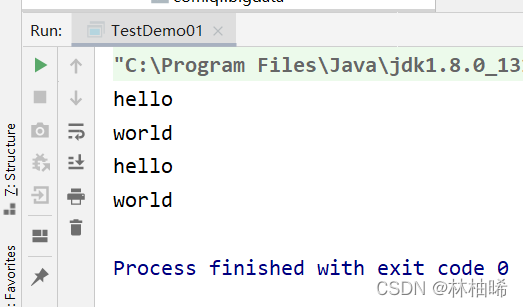
2.2.3 filter算子
def filter(f: T => Boolean): RDD[T]
T : 表示RDD中的元素类型的返回值
f:函数
Boolean:f函数的返回类型
作用:将RDD中的元素过滤,把f函数返回为true的保留。产生一个新的RDD副本
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
val filterRDD:RDD[String] = txtRDD.filter(_.contains("hello"))
filterRDD.foreach(println)
}
}
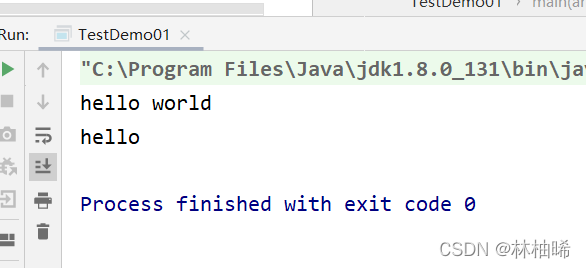
2.2.4 sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]withReplacement:抽样方式,true有返回抽样,false无返回抽样
fraction:抽样因子/比例,取值范围介于0~1之间
seed:随机数种子
作用:抽样的查询
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())val listRDD:RDD[Int] = sc.parallelize(1 to 1000)
var res: RDD[Int] = listRDD.sample(true,0.01)
println(res.count())
println("_"*10)
res = listRDD.sample(true,0.01)
println(res.count())
println("_"*10)}
}
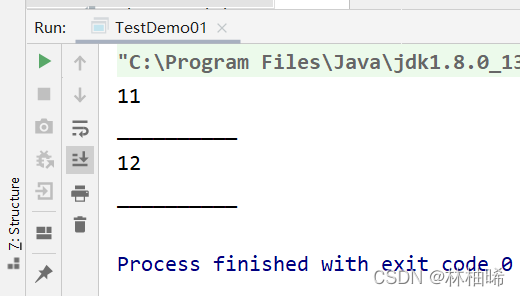
2.2.5 union
def union(other: RDD[T]): RDD[T]
other : 需要进行合并的RDD
返回值:合并之后的RDD
作用:将两个RDD进行合并形成一个新的RDD。类似于SQL中的union all
就是两个rdd元素有一样的也都会出现,不会去重。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
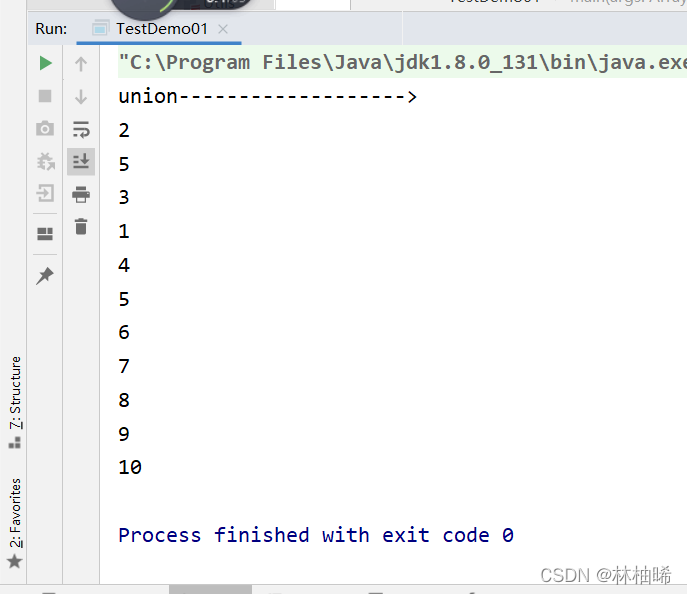
println("union------------------->")
val listRDD1:RDD[Int] = sc.parallelize(List(1,2,3,4,5))
val listRDD2:RDD[Int] = sc.parallelize(List(5,6,7,8,9,10))
listRDD1.union(listRDD2).foreach(println)
sc.stop()}
}
2.2.6 distinct
def distinct(): RDD[T]
作用:将一个RDD中相同的元素剔除,然会一个新的RDD
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
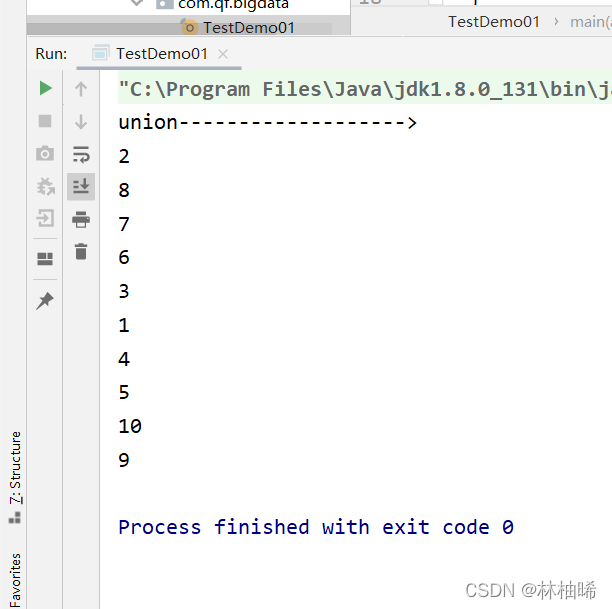
println("union------------------->")
val listRDD1:RDD[Int] = sc.parallelize(List(1,2,3,4,5))
val listRDD2:RDD[Int] = sc.parallelize(List(5,6,7,8,9,10))
listRDD1.union(listRDD2).distinct().foreach(println)
sc.stop()}
}
2.2.7 join
一 sql的join
1. 交叉查实训
select * from A a accross join B b; 这种方式会产生笛卡尔积,在工作中一定要避免2. 内连接
select * from A a [inner] join B b [where|on a.id = b.id];3. 外连接
3.1 左外 : 查询到所有的左表数据,右边要符合条件
select * from A a left [outer] join B b on a.id = b.id];3.2 右外 : 查询到所有的右表数据,左边要符合条件
select * from A a right [outer] join B b on a.id = b.id];3.3 全外 : 两边表都能查询
select * from A a full [outer] join B b on a.id = b.id];3.4 左半连接 :一般在工作中不用
二 spark的join
e.g. 假设RDD1[K,V], RDD2[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3074
3074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









