










 本文详细介绍如何使用Caffe框架的convert_imageset工具,将ImageNet数据集转换为LMDB格式,适用于训练和验证阶段。文章包括设置环境变量、检查数据路径及执行转换命令等关键步骤。
本文详细介绍如何使用Caffe框架的convert_imageset工具,将ImageNet数据集转换为LMDB格式,适用于训练和验证阶段。文章包括设置环境变量、检查数据路径及执行转换命令等关键步骤。
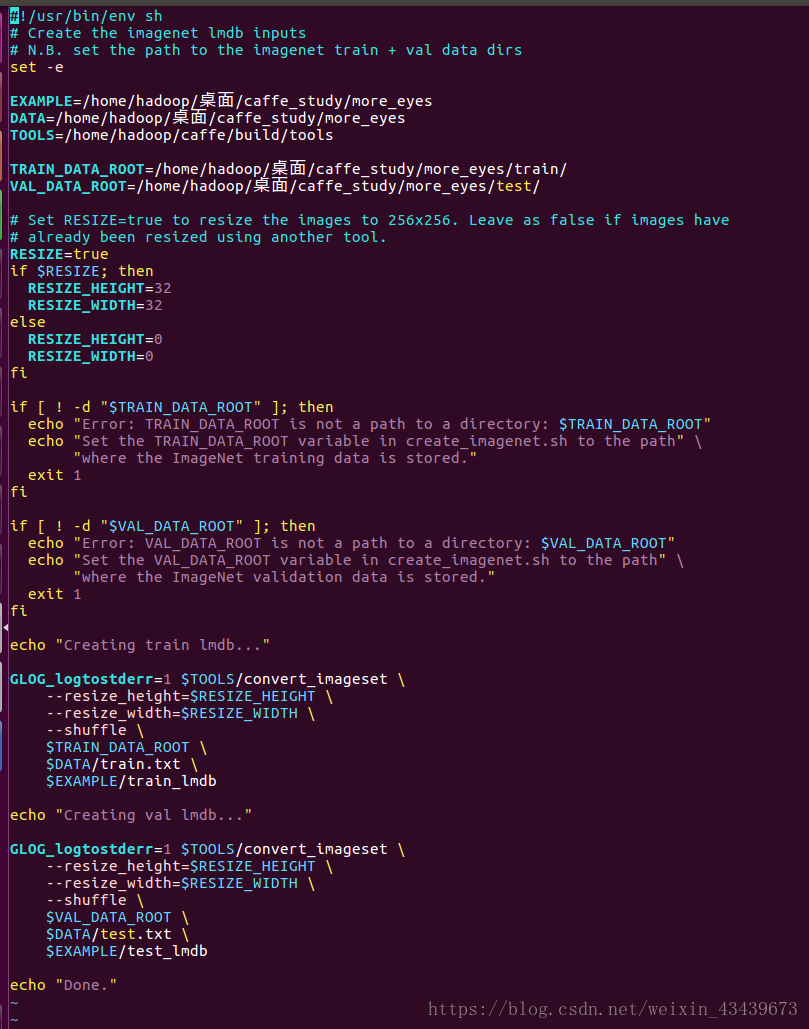
#!/usr/bin/env sh
set -e
EXAMPLE=/home/hadoop/桌面/caffe_study/more_eyes
DATA=/home/hadoop/桌面/caffe_study/more_eyes
TOOLS=/home/hadoop/caffe/build/tools
TRAIN_DATA_ROOT=/home/hadoop/桌面/caffe_study/more_eyes/train/
VAL_DATA_ROOT=/home/hadoop/桌面/caffe_study/more_eyes/test/
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=32
RESIZE_WIDTH=32
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/test.txt \
$EXAMPLE/test_lmdb
echo "Done."
有问题欢迎评论,我们共同解决
喜欢请关注,转载请注明出处,谢谢配合

















 3043
3043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









