






论文标题:A Semi-supervised Learning Method for Fake News Detection in Social Media
日期:IEEE2020
#基于新闻文本(+图像多模)、#半监督、#伪标签、#LDA
一、基本内容
利用LDA方法为未标注数据打伪标签,从而更好的训练无标注的CNN模型,取得了不错的效果。
二、主要工作
SLD-CNN
基于半监督学习框架,使用CNN针对标记和未标记数据。
(1)首先使用CNN提取文本和图像数据的各种特征;
(2)使用线性判别分析(LDA)预测未分类数据的类别;
(3)提出一种方法计算适应度函数,以提升每个步骤中预测类别的效果。
三、模型框架
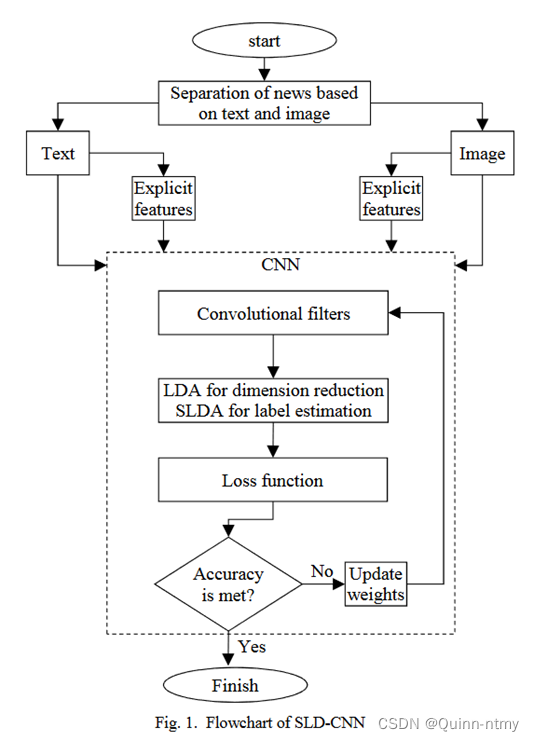
- CNN需要标记数据来优化网络,并且未标记数据不能在CNN中使用。故使用基于LDA的方法预测未标记数据。
- LDA线性判别分析:
一个接近方差分析和回归分析的概念。在每种统计方法中,因变量被建模为其他变量的组合。但在方差分析和回归分析中,因变量是距离类型,而在LDA中,因变量是名义或有序的。
论文中假设每个特征都可以建模为一个随机变量。
协方差矩阵是数值变量在不同方向上方差的一般形式,且由于方差表示随机变量在均值附近的值的分布。因此, n n n个变量的协方差矩阵 表示 在均值向量周围的 n n n维空间中的概率分布。
如果有 n n n个随机变量 { h 1 , … , h n } {\{h_1,…,h_n}\} {h1,…,hn}使得每个变量包含 m m m个实例(并存储在维数为 m × n m×n m×n的矩阵 D D D中,其中第 i i i列第 j j j行的元素表示 x i x_i xi和 y i y_i yi之间的协方差)。
∑ [ i , j ] = C o v ( x i , y i ) ∑[i,j] =Cov(x_i,y_i) ∑[i,j]=Cov(xi,yi)
C o v ( x i , y i ) = 1 m ∑ l = 1 m [ ( D ( l , i ) − μ i ) ( D ( i , j ) − μ j ) ] {Cov(x_i,y_i )} = {1\over m} {∑_{l=1}^m[(D(l,i)-μ_i)(D(i,j)-μ_j)]} Cov(xi,yi)=m1∑l=1m[(D(l,i)−μi)(D(i,j)−μj)]
μ i μ_i μi和 μ j μ_j μj是矩阵的第 i i i行、第 j j j列的变量均值,根据Fisher线性判别理论,当均值之差最大,协方差值之差最小时,判别效果最好:
W = ( ∑ 0 + ∑ 1 ) − 1 ( μ ‾ 1 ) − ( μ ‾ 0 ) W=(∑_0+∑_1 )^{-1} (\overline{μ}_1 ) -(\overline{μ}_0 ) W=(∑0+∑1)−1(μ1)−(μ0)
由于问题有2个类别(真实文章和假文章),因此索引为0和1。
因为对于每个类来说,均值是每个特征的每个均值的向量。这意味着两个类分离级别处于最大值,我们可以降低维度(即特征数量)并保留其中重要的特征。这个过程适用于没有标签的数据。 - 半监督LDA(SLDA)
SLDA是一种迭代算法,获取特征和类数量并迭代最大化判别类(两个类:fake—0、real—1),所以SLDA的输出是一个介于0和1之间的数字。
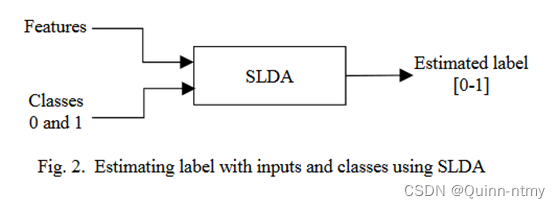
- 结合CNN
估计标签的值可能存在误差,为了控制其对CNN分类过程的影响,引入了影响因子α:
θ ∗ = a r g m i n [ L l a b e l e d ( y ^ , y ) + α L u n l a b e l e d ( y ^ , y ) ] θ^*=argmin[L_{labeled} (\hat{y},y)+αL_{unlabeled} (\hat{y},y)] θ∗=argmin[Llabeled(y^,y)+αLunlabeled(y^,y)]
【第一和第二卷积层的激活函数是ReLU,输出层的激活函数是Softmax,使用Adam优化器】
使用的参数信息:
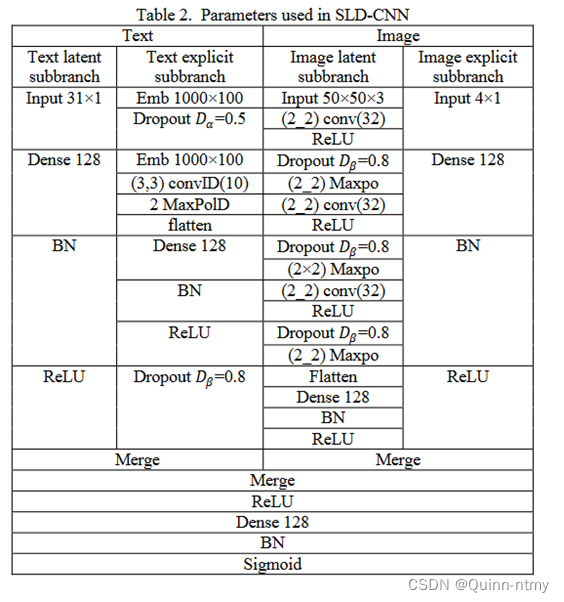
四、数据集
多模式(文本、图像)数据集来自各知名网站:20015篇新闻文章,其中11941篇是假的,8074篇是正确的。

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









