







论文标题:A novel self-learning semi-supervised deep learning network to detect fake news on social media
日期:2021
#基于新闻文本、#半监督、#自学习、#伪标签
一、基本内容
利用有标注数据训练好的模型为无标注数据打伪标签,该工作创新点即使用一个confidence function的方式为伪标签进行评定,选取质量较高的伪标签样本放入到标注数据中,这样提升了伪标签的质量,从而更好的进行半监督的虚假新闻检测。
二、文章动机
(1)实际中,带注释的数据集很难获得(因为假新闻通过网站传播);
(2)监督学习模型无法实现自学,因为它忽略了真实和虚假数据之间的相关性。
三、主要工作
研究一个自学习的半监督深度学习网络,增加了一个置信网络层,它可以自动返回并添加正确的结果,帮助神经网络积累正样本案例,从而提高神经网络的准确性。
该网络同时训练监督和无监督任务来检测假新闻,具体:
(1)设计一个半监督深度学习网络,使用修改后的深度学习机器同时训练有监督和无监督的任务;
(2)可以自动将非常准确的未标记数据添加到训练集中,并在多次迭代训练过程逐渐扩展训练集以实现自学习(self-learning)。
四、模型框架
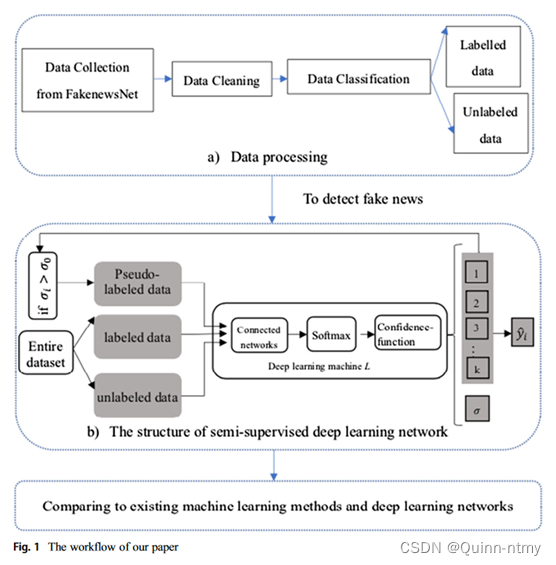
-
数据处理阶段:数据清洗、将数据分为标记数据和未标记数据。
-
半监督自学习阶段:
该模型使用改进的深度学习机器 L L L同时训练 有监督 和 无监督 任务。有监督任务 中只需要一小部分标记数据,而 无监督任务 预测剩余的未标记数据,并返回未标记数据的高度可靠的伪标签来丰富标记的数据集,从而达到自学习的效果。
1、模型训练过程
D
l
D_l
Dl——训练数据集中的标记示例,大小为
∣
L
∣
|L|
∣L∣,
D
l
0
=
(
X
1
,
y
1
)
,
(
X
2
,
y
2
)
,
…
,
(
X
l
,
y
l
)
D_l^0={(X1,y1),(X2,y2),…,(Xl,yl)}
Dl0=(X1,y1),(X2,y2),…,(Xl,yl);
D
u
D_u
Du——测试训练集中的未标记示例,大小为
∣
U
∣
|U|
∣U∣,
D
u
=
X
l
+
1
,
X
l
+
2
,
…
,
X
l
+
u
D_u={Xl+1,Xl+2,…,Xl+u}
Du=Xl+1,Xl+2,…,Xl+u。
工作流程:
(1)初始化:在有监督的深度学习模块中,使用
D
l
0
D_l^0
Dl0作为训练集来训练深度学习机
L
L
L。然后,在无监督深度学习模块中,
D
u
′
=
(
X
l
+
1
,
y
^
l
+
1
)
,
(
X
l
+
2
,
y
^
l
+
2
)
,
…
,
(
X
l
+
u
,
y
^
l
+
u
)
D_u^{'}={(X_{l+1},~\hat{y}_{l+1}),(X_{l+2},~\hat{y}_{l+2}),…,(X_{l+u},~\hat{y}_{l+u})}
Du′=(Xl+1, y^l+1),(Xl+2, y^l+2),…,(Xl+u, y^l+u)的伪标签通过训练的深度学习机L和它们的置信度值σ生成,如果
σ
0
σ_0
σ0是过滤
D
u
′
D_u^{'}
Du′中不自信的伪标签的阈值,则
D
u
′
D_u^{'}
Du′的置信伪标签集可以表示为
D
p
s
e
u
0
=
(
(
X
l
+
i
,
y
^
l
+
i
)
,
(
X
l
+
i
+
1
,
y
^
l
+
i
+
1
)
,
…
,
(
X
l
+
p
+
i
,
y
^
l
+
p
+
2
)
)
D_{pseu}^0={((X_{l+i},~\hat{y}_{l+i}),(X_{l+i+1},~\hat{y}_{l+i+1}),…,(X_{l+p+i},~\hat{y}_{l+p+2}))}
Dpseu0=((Xl+i, y^l+i),(Xl+i+1, y^l+i+1),…,(Xl+p+i, y^l+p+2)),大小为
∣
P
0
∣
|P_0 |
∣P0∣。
(2)重复:新的训练集
D
l
1
=
∣
D
l
0
∪
D
p
s
e
u
0
∣
=
(
X
1
,
y
1
)
,
(
X
1
,
y
1
)
,
…
,
(
X
l
,
y
l
)
,
…
,
(
X
l
+
p
,
y
l
+
p
)
D_l^1=|D_l^0∪D_{pseu}^0 |={(X_1,y_1 ),(X_1,y_1 ),…,(X_l,y_l ),…,(X_{l+p},y_{l+p})}
Dl1=∣Dl0∪Dpseu0∣=(X1,y1),(X1,y1),…,(Xl,yl),…,(Xl+p,yl+p)用于重新训练深度学习机器L以生成新的置信标签集
D
p
s
e
u
2
D_{pseu}^2
Dpseu2,大小为
∣
P
1
∣
|P_1 |
∣P1∣和一个新的训练集
D
l
2
=
∣
D
l
1
∪
D
p
s
e
u
1
∣
D_l^2={|{D_l^1}∪{D_{pseu}^1 }|}
Dl2=∣Dl1∪Dpseu1∣。重复此步骤,直到
D
p
s
e
u
t
=
D
p
s
e
u
t
+
1
D_{pseu}^t=D_{pseu}^{t+1}
Dpseut=Dpseut+1。
2、深度学习机器 L L L基本架构
L
L
L是通过现有神经网络(例如RNN、CNN、LSTM和Bi-LSTM)中添加置信层来构建。
(1)Embedding layer
(2)Dropout layer(设置为0.5)
(3)Bi-LSTM layer
(4)Softmax layer
(5)Confidence-function layer:
置信网络层会自动返回并添加校正结果,以此帮助神经网络积累正样本案例。
本层用来计算
D
u
D_u
Du中每个元素的置信度值
σ
σ
σ,并在
D
u
′
D_u^{'}
Du′中生成伪标签。对于每个输入
X
i
X_i
Xi,
σ
(
X
i
)
=
m
a
x
(
0
,
p
(
y
=
j
∣
X
i
)
)
σ_(X_i )=max(0,p(y=j|X_i))
σ(Xi)=max(0,p(y=j∣Xi));
假设
σ
0
σ_0
σ0是过滤
D
u
′
D_u^{'}
Du′中不自信的伪标签的阈值,则
D
u
′
D_u^{'}
Du′中的元素
X
i
X_i
Xi的置信伪标签,如果
σ
(
X
i
)
>
σ
0
σ_{(X_i )}>σ_0
σ(Xi)>σ0,则
y
^
=
{
0
,
o
t
h
e
r
w
i
s
e
1
,
i
f
j
=
a
r
g
m
a
x
p
(
y
=
j
∣
X
i
)
\hat{y}=\{^{1,~if~~j=argmax~p(y=j|X_i)}_{0,~otherwise}
y^={0, otherwise1, if j=argmax p(y=j∣Xi)。
然后我们得到
D
u
′
D_u^{'}
Du′的整个置信伪标签集
D
p
s
e
u
0
D_{pseu}^0
Dpseu0,其大小为
∣
P
0
∣
|P_0 |
∣P0∣。
最终新的训练集
D
l
1
=
∣
D
l
0
∪
D
p
s
e
u
0
∣
=
(
X
1
,
y
1
)
,
(
X
1
,
y
1
)
,
…
,
(
X
l
,
y
l
)
,
…
,
(
X
l
+
p
,
y
l
+
p
)
D_l^1=|D_l^0∪D_pseu^0 |={(X_1,y_1 ),(X_1,y_1 ),…,(X_l,y_l ),…,(X_{l+p},y_{l+p})}
Dl1=∣Dl0∪Dpseu0∣=(X1,y1),(X1,y1),…,(Xl,yl),…,(Xl+p,yl+p)用于重新训练深度学习机器L以生成一个新的置信伪标签集
D
p
s
e
u
2
D_{pseu}^2
Dpseu2,大小为
∣
P
1
∣
|P_1 |
∣P1∣和一个新的训练集
D
l
2
=
∣
D
l
1
∪
D
p
s
e
u
1
∣
D_l^2=|D_l^1∪D_{pseu}^1 |
Dl2=∣Dl1∪Dpseu1∣。重复此步骤,直到
D
p
s
e
u
t
=
D
p
s
e
u
t
+
1
D_{pseu}^t=D_{pseu}^{t+1}
Dpseut=Dpseut+1。
五、数据集
FakeNewsNet存储库中的PolitiFact和GossipCop数据集,每个数据集都包含新闻内容、社会背景和时空信息。
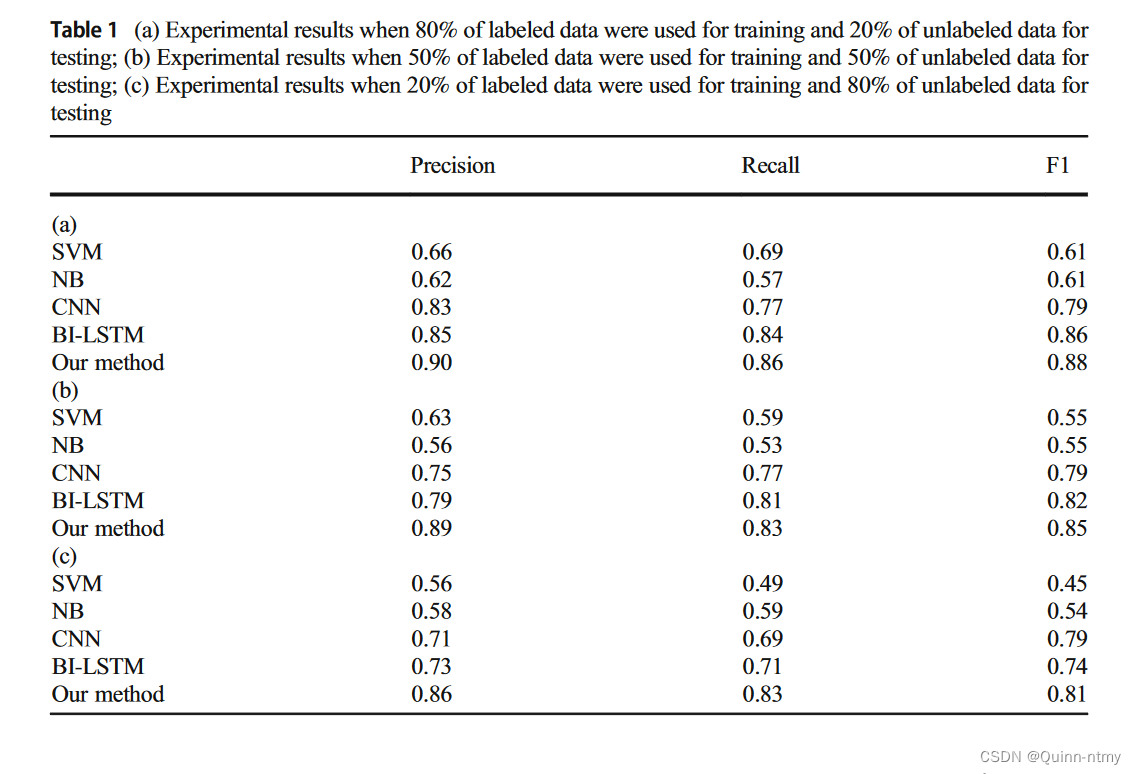
六、实验结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









