







1、生产者分区策略
- 指定了分区号。 producer就发往指定分区。
- 没有分区号但是指定了key。 producer的分区号由key的hash值 % 分区数量来决定。
- 没有分区号也没有key。 第一次调用时随机生成一个整数,后面每次调用在此整数上自增。此整数 % 分区数量的值就是分区号。也就是round-robin(轮询)算法。
2、消费者消费策略
- Range 范围策略(默认的)
用分区数除以消费者数来决定每个Consumer消费几个Partition,除不尽的前面几个消费者将会多消费一个
举个例子:假设为Topic A 创建了 10个分区,有三个消费者(C1,C2,C3),分配如下:
C1:0,1,2,3 C2:4,5,6 C3:7,8,9
-
RoundRobin 轮询策略
轮询策略是将消费组内所有的消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。
举个例子:假设为Topic A 创建了 3个分区(P0,P1,P2),有两个消费者(C1,C2),按照字典排序分区变成了 P0->P1->P2,然后依次将P0分配C1,P1分配给C2,P2又分配给C1,最终分配如下:
C1: P0,P2 C2:P1
如需修改策略,修改consumer.properties配置
#轮训策略
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
#范围策略
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignor
3、消息队列的两种模式
首先需要知道:一个partition只能被一个Consumer Group组中一个消费者消费
- 点对点模式(一对一)
这里的一对一,指的是1条消息只能被一个消费者消费。如果消息只被一个Consumer Group消费,那么kafka天然支持这种模式 - 发布订阅模式(一对多)
这里的一对多,指的是1条消息能被多个订阅了该topic的消费者消费。
4、生产者发送流程
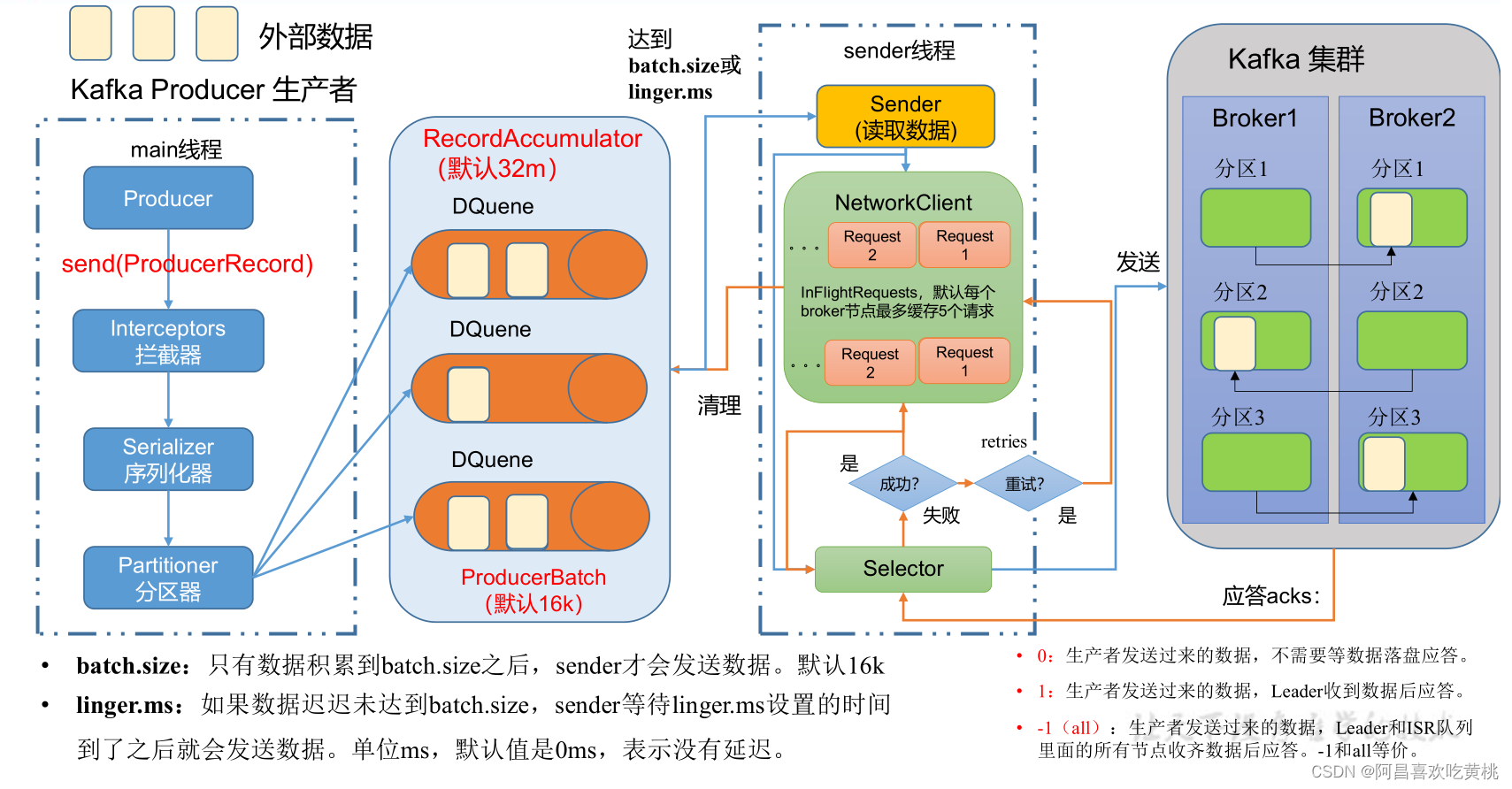
kafka在发送消息的过程中,主要涉及两个线程main 线程和 sender 线程。
1、在 main 线程 中创建了一个双端队列 RecordAccumulator。
2、main 线程将消息发送给 RecordAccumulator。
3、sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker
(1)生产者发送时机
从上图可知,当有消息时,生产者不是立马发送到broken上,而是先写入内存的队列中,只有当满足以下两个条件时,才会发送到broken上:
- batch.size:数据累计到batch.size之后,sender才会发送数据。
- linger.ms:如果数据迟迟未达到batch.size,但是设置的linger.ms时间满足条件,则就进行发送数据,单位未ms,默认值是0ms;表示没有延迟。
以上两个参数均为生产者配置,其余生产者重要配置项如下:

(2)消息确认机制
消息发送到broker上,通过配置的acks来确认消息是否投递成功,acks有3个值可选 0、1和-1(或者all)默认值为1
- 0:producer发送后即为成功,无需分区partition的leader确认写入成功
- 1:producer发送后需要接收到partition的leader发送确认收到的回复
- -1:producer发送后,需要ISR中所有副本都成功写入成功才能收到成功响应
5、kafka具有高吞吐量的原因
- 顺序写入
Kafka使用了顺序IO提升了磁盘的写入速度,Kafka会将数据顺序插入到文件末尾,消费者端经过控制偏移量来读取消息 - 零拷贝
零拷贝是指将数据直接从磁盘文件复制到网卡设备中,减少了不必要的拷贝次数。没使用零拷贝之前是这样的:
1、第一次:将磁盘文件,read()到操作系统内核缓冲区;
2、第二次:将内核缓冲区的数据,复制到用户模式的buffer;
3、第三步:将用户模式buffer中的数据,复制到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
从上面的过程可以看出,数据平白无故地从内核模式到用户模式“走了一圈”,浪费了2次复制过程:第一次是从内核模式复制到用户模式;第二次是从用户模式再复制回内核模式,即上面4次过程中的第2步和第3步。而且在上面的过程中,内核和用户模式的上下文的切换也是4次。如果采用了零拷贝技术,那么应用程序可以直接请求内核把磁盘中的数据传输给 Socket - 批量发送
kafka生产者在发送消息时,不会有消息就立马发送给broker,而是采用批量发送,这样就减少了网络的开销。优先发送到自己内存队列中,只有当消息满足batch.size或者linger.ms才进行批量发送:
1、batch.size:通过这个参数来设置批量提交的数据大小,默认是16k。当积压的同一分区的消息达到这个值的时候就会统一发送。
2、linger.ms:这个是配合batch.size一起来设置,可避免消息长时间凑不齐batch.size指定的大小,导致消息一直积压在内存里发送不出去的情况。默认大小是0ms(就是有消息就立即发送)。 - 批量压缩
Kafka支持多种压缩协议(包括Gzip和Snappy压缩协议),将消息进行批量压缩。
6、kafka如何解决数据重复性问题
从上面生产者发送流程可知,当生产者收到broker的acks回复时,表示消息发送成功,但有可能由于网络问题,导致生产者触发重试机制,导致消息重复,同样的,消费者再消费的时候,消息消费成功,但是再提交offset的时候失败,同样也会触发消息重试,导致消息重复:
1、生产者发送重复
再解决生产者幂等,只需要将Producer的enable.idempotence配置项设为true,其原理是kafka引入了ProducerID和Sequence。
- PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
- 序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
broker会为每个TopicPartition组合维护PID和序列号。对每条接收到的消息,都会检查它的序列号是否比Broker所维护的值严格+1,只有这样才是合法的,其他情况都会丢弃。当出现消息重试时,broker就会检测到有两条PID 一样且seq 也一致的的消息写入了Partition,并忽略掉重发的那一条
其中这种方式是有部分缺陷的:
单会话有效
只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
原因:重启之后标识producer的PID就变化了,导致broker无法根据这个<PID,TP,SEQNUM>条件去去判断是否重复。
单分区有效
只能保证单分区上的幂等性。即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。
原因:在某一个partition 上判断是否重复是通过一个递增的sequence number,也就是说这个递增是针对当前特定分区的,如果你要是发送到其他分区上去了,那么递增关系就不存在了。
为解决以上问题,实现跨分区跨会话的事务kafka又引入一个全局唯一的 Transaction ID,并将 Producer 获得的 PID 和 Transaction ID 绑定。这样当Producer重启之后,就可以通过正在运行的 Transaction ID 获得原来的 PID。
为了管理 Transaction,Kafka引入了一个新的组件 Transaction Coordinator。Producer就是通过 Transaction Coordinator 获得 Transaction ID 对应的任务状态。Transaction Coordinator还负责将事务状态写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复。
2、消费者消费重复
一般又业务方自行保证,如将唯一键存入第三方介质,要操作数据的时候先判断第三方介质(数据库或者缓存)有没有这个唯一键。
7、kafka消息有序性
- 全局有序
将消息发往同一个Partition,也就是将分区数设置为1,这样就保证了消息的顺序,但牺牲了性能 - 局部有序
比如有如下场景:发送给 kafka 的消息为对 mysql 表的操作, 有对于同一条数据的插入、更新、删除等操作。若这些操作消息被分配到 kafka 的不同 Partition, 就会导致无序消费的情况。因此, 需要将处理同样数据的消息发送到同一个 Partition。kafka也提供了相关的实现,生产者向 kafka 发送消息时, 可以指定消息的特征值, kafka 会对特征值做 hash,并将消息发送到相应 hash 的 Partition 分区中。
但是上面都存在一个问题,假设消息A先发送,网络抖动,消息发送失败,消息B紧接着发送,且发送成功,消息A重试成功,那么A和B的顺序就出现了错乱,解决这种问题的方法:
(1)将 max.in.flight.requests.per.connection设置为1,这个参数用来缓存生产者最大发送失败的请求连接,也就是说指定了该参数,生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
(2)将acks > 0,根据上面消息确认机制可知,acks为0,代表producer发送后即为成功,无需broker回复,这样也有可能导致出现乱序
这样设置完后,在 Kafka 的发送端,消息发出后,响应必须满足 acks 设置的参数后,才会发送下一条消息。所以,虽然在使用时,还是异步发送的方式,其实底层已经是一条接一条的发送了。
8、kafka参数详解
kafka的有序性 - dreamness的个人空间 - OSCHINA - 中文开源技术交流社区

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









