




1、创新点:
本文解决了目标检测中的两个关键问题。
问题一:速度
经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断。
问题二:训练集
经典的目标检测算法在区域中提取人工设定的特征(Haar,HOG)。本文则需要训练深度网络进行特征提取。可供使用的有两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
本文使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
2、R-CNN思路
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、非极大值抑制四个步骤进行目标检测、只不过进行了部分改进。
经典的目标检测算法使用滑动窗法依次判断所有可能的区域。而这里预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断,大大减少了计算量。
将传统的特征(如SIFT,HOG特征等)换成了深度卷积网络提取特征。
在训练时使用两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
3、 算法简述
数据集采用pascal VOC,这个数据集的object一共有20个类别。首先用selective search方法在每张图像上选取约2000个region proposal,region proposal就是object有可能出现的位置。然后根据这些region proposal构造训练和测试样本,注意这些region proposal的大小不一,另外样本的类别是21个(包括了背景)。
然后是预训练,即在ImageNet数据集下,用AlexNet进行训练。然后再在我们的数据集上fine-tuning,网络结构不变(除了最后一层输出由1000改为21),输入是前面的region proposal进行尺寸变换到一个统一尺寸227x227,保留f7的输出特征2000x4096维。
针对每个类别(一共20类)训练一个SVM分类器,以f7层的输出作为输入,训练SVM的权重4096x20维,所以测试时候会得到2000x20的得分输出,且测试的时候会对这个得分输出做NMS(non-maximun suppression),简单讲就是去掉重复框的过程。同时针对每个类别(一共20类)训练一个回归器,输入是pool5的特征和每个样本对的坐标即长宽。
流程
RCNN算法分为4个步骤
一张图像生成1K~2K个候选区域
对每个候选区域,使用深度网络提取特征
特征送入每一类的SVM 分类器,判别是否属于该类
使用回归器精细修正候选框位置
4、训练步骤
4.1候选区域生成
对于训练集中的所有图像,采用selective search方式来获取,最后每个图像得到2000个region proposal。
预先找出图中目标可能出现的位置,即候选区域(Region Proposal)。利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千甚至几百)的情况下保持较高的召回率(Recall)。所以,问题就转变成找出可能含有物体的区域/框(也就是候选区域/框,比如选2000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举所有框了。大牛们发明好多选定候选框Region Proposal的方法,比如Selective Search和EdgeBoxes。那提取候选框用到的算法“选择性搜索”到底怎么选出这些候选框的呢?
基本思路如下:
使用一种过分割手段,将图像分割成小区域
查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
输出所有曾经存在过的区域,所谓候选区域
具体操作:
- (1)产生初始的分割区域
选择性搜索算法需要先使用《Efficient Graph-Based Image Segmentation》RCNN中的前期准备:Efficient Graph-Based Image Segmentation(9)—《深度学习》论文里的方法产生初始的分割区域,然后使用相似度计算方法合并一些小的区域。
这篇论文的思想是把图像看作为一个图(graph),图中的节点就是图像中的像素,而权重就是相邻像素之间的差异性。然后通过贪心算法不断融合差异性小的像素或者区域为一个区域,将图最后划分为数个区域(regions或者是components),从而完成对图像的分割。
我们不能使用原始分割图的区域作为候选区域,原因如下:
大部分物体在原始分割图里都被分为多个区域
原始分割图无法体现物体之间的遮挡和包含。
- (2)将产生初始的分割区域作为输入,通过选择性搜索进行合并:
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
选择性搜索算法如何计算两个区域的像素度的呢?
主要是通过以下四个方面:颜色、纹理、大小和形状交叠
最终的相似度是这四个值取不同的权重相加,具体计算可以参考:选择性搜索相似度计算
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
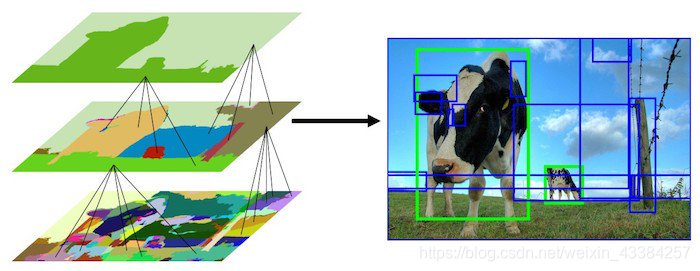
通过不停的迭代,候选区域列表中的区域越来越大。可以说,我们通过自底向下的方法创建了越来越大的候选区域。表示效果如下:
4.2 准备正负样本
如果某个region proposal和当前图像上的所有ground truth(标记)重叠面积最大的那个的IOU大于等于0.5,则该region proposal作为这个ground truth类别的正样本,否则作为负样本(认为是背景)。
注意:
【当前图像上的所有ground truth(标记)重叠面积最大的实际上就是region proposal的真实目标】
另外正样本还包括了Ground Truth。因为VOC一共包含20个类别,所以这里region proposal的类别为20+1=21类,1表示背景。
训练数据 :
使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
简单说下IOU的概念,IOU是计算矩形框A、B的重合度的公式:IOU=(A∩B)/(A∪B),重合度越大,说明二者越相近。
4.3预训练
这一步主要是因为检测问题中带标签的样本数据量比较少,难以进行大规模训练。
训练(或者下载)一个分类模型(比如AlexNet)(5层卷积层,3层全连接层)
训练数据:
使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号。
4.4 微调 fine-tuning
AlexNet预训练好的网络,继续训练,由于ILSVRC 2012是一个1000类的数据集,而本文的数据集是21类(包括20个VOC类别和一个背景类别),所以将最后一个全连接层的输出由1000改成21,另外,其他结构不变。 训练结束后保存f7的特征!!!!
该网络输入为建议框【由selective search而来】变形后的227×227的图像,修改了原来的1000为类别输出,改为21维【20类+背景】输出,训练的是网络参数。
训练数据:
微调阶段正样本定义并不强调精准的位置,并且微调阶段的负样本是随机抽样的
mini-batch为32个正样本(属于20类)和96个负样本;
正样本:Ground Truth+与Ground Truth相交IoU>0.5的建议框【由于Ground Truth太少了】(属于20类)
负样本:与Ground Truth相交IoU≤0.5的建议框
PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;
采用训练好的AlexNet CNN网络进行PASCAL VOC 2007样本集下的微调,学习率=0.001【0.01/10为了在学习新东西时不至于忘记之前的记忆】;
将(4.2)PASCAL VOC 2007中得到的样本==进行尺寸变换,==使得大小一致,这是由于((4.2))PASCAL VOC 2007中得到的region proposal大小不一,所以需要将region proposal变形成227*227
那么问题来了,如何进行变形操作呢?
本文中对所有不管什么样大小和横纵比的region proposal都直接拉伸到固定尺寸,具体原因以及操作见解析分析中的2 : 为什么要将建议框变形为227×227?怎么做? 。然后预训练好的网络的输入,继续训练网络。
我理解的就是一张图片有2000个候选框,抽出来32个正样本(Iou>0.5)以及96个负样本(随机抽取)——然后将这些样本变换到227x227——送入网络,将网络最后一个全连接层由1000变为21——学习率=0.001训练网络
4.5 针对每个类别训练一个SVM的二分类器
输入是f7的特征,f7的输出维度是2000x4096,输出的是是否属于该类别,训练结果是得到SVM的权重矩阵W,W的维度是4096x20(其实每一列4096个元素就是一个SVM的二分类,一共20列,也就是20个分类器。)。这里负样本的选定和前面的有所不同,将IOU的阈值从0.5改成0.3,即IOU<0.3的是负样本,正样本是Ground Truth。IOU的阈值选择和前面fine-tuning不一样,主要是因为:前面fine-tuning需要大量的样本,所以设置成0.5会比较宽松。而在SVM阶段是由于SVM适用于小样本,所以设置0.3会更严格一点。
IOU的阈值从0.5到0.3使得正样本数量增加,负样本数量减少。
SVM算法是一个数学问题,实际上,一共2000个候选区,每一个候选区的f7输出的大小是4096个数字,经过SVM的权重4096x20可以得到一个行向量,这个行向量有20个元素,一共2000个候选区,可以得到2000个包括20个元素的行向量,组合起来可以看做是2000x20.。这个20实际上是每个候选框在每一类上的分数。
候选区根据IOU判断正负样本,这2000个行向量,对于每一个类有正样本有负样本, SVM的训练过程,实际上就是根据已经知道的正样本和负样本,来学习权重。比如第一类是person=[1,0,0,0,0,……]person是第一类,表示的第一个值就应该最大。训练,候选框如果是person的正样本,那么这4096个数乘以SVM的4096x20矩阵,就应当输出第一类person分数很大,其余的很小,(也就是这20个数中,第一个数应该很大)也就是[1,0,0,0,0,……],如果不是就应该继续学习。
因为微调时和训练SVM时所采用的正负样本阈值不同,微调阶段正样本定义并不强调精准的位置,而SVM正样本只有Ground Truth;并且微调阶段的负样本是随机抽样的,而SVM的负样本是经过=hard negative mining方法筛选的
首先是negative,即负样本,其次是hard,说明是困难样本,也就是说在对负样本分类时候,loss比较大(label与prediction相差较大)的那些样本,也可以说是容易将负样本看成正样本的那些样本,例如roi里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫easy negative;如果roi里有物体的很大一部分,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是hard negative。hard negative mining就是多找一些hard negative加入负样本集,进行训练,这样会比easy negative组成的负样本集效果更好。主要体现在虚警率更低一些(也就是false positive少)。
训练数据:
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的4096维特征,输出是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本 :本类的真值标定框。
负样本: 考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本。对于负样本严格了一些。负样本相对于微调时,变少了。
4.6 回归
使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
用pool5的特征6x6x256维和bounding box的ground truth来训练回归,每种类型的回归器单独训练。输入是pool5的特征,以及每个样本对的坐标和长宽值。另外只对那些跟ground truth的IOU超过某个阈值且IOU最大的proposal回归,其余的region proposal不参与。
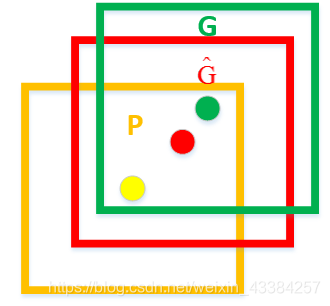
输入:P和G的坐标以及w和h
输出:横向位移变化量,纵向位移变化量,宽度缩放尺寸,高度缩放尺寸


训练:

关于回归具体可以看:解析分析 5 :为什么要采用回归器?回归器是什么有什么用?如何进行操作?
训练样本:
与Ground Truth相交IoU最大的Region Proposal,并且IoU>0.6的Region Proposal
训练阶段几个问题:
(1)什么叫有监督预训练?为什么要进行有监督预训练?
有监督预训练也称之为迁移学习,举例说明:若有大量标注信息的人脸年龄分类的正负样本图片,利用样本训练了CNN网络用于人脸年龄识别;现在要通过人脸进行性别识别,那么就可以去掉已经训练好的人脸年龄识别网络CNN的最后一层或几层,换成所需要的分类层,前面层的网络参数直接使用为初始化参数,修改层的网络参数随机初始化,再利用人脸性别分类的正负样本图片进行训练,得到人脸性别识别网络,这种方法就叫做有监督预训练。这种方式可以很好地解决小样本数据无法训练深层CNN网络的问题,我们都知道小样本数据训练很容易造成网络过拟合,但是在大样本训练后利用其参数初始化网络可以很好地训练小样本,这解决了小样本训练的难题。
这篇文章最大的亮点就是采用了这种思想,ILSVRC样本集上用于图片分类的含标注类别的训练集有1millon之多,总共含有1000类;而PASCAL VOC 2007样本集上用于物体检测的含标注类别和位置信息的训练集只有10k,总共含有20类,直接用这部分数据训练容易造成过拟合,因此文中利用ILSVRC2012的训练集先进行有监督预训练。
(2)ILSVRC 2012与PASCAL VOC 2007数据集有冗余吗?
即使图像分类与目标检测任务本质上是不同的,理论上应该不会出现数据集冗余问题,但是作者还是通过两种方式测试了PASCAL 2007测试集和ILSVRC 2012训练集、验证集的重合度:第一种方式是检查网络相册IDs,4952个PASCAL 2007测试集一共出现了31张重复图片,0.63%重复率;第二种方式是用GIST描述器匹配的方法,4952个PASCAL 2007测试集一共出现了38张重复图片【包含前面31张图片】,0.77%重复率,这说明PASCAL 2007测试集和ILSVRC 2012训练集、验证集基本上不重合,没有数据冗余问题存在。
(3)可以不进行特定样本下的微调吗?可以直接采用AlexNet CNN网络的特征进行SVM训练吗?
首先,反正CNN都是用于提取特征,那么我直接用Alexnet做特征提取,省去fine-tuning阶段可以吗?这个是可以的,你可以不需重新训练CNN,直接采用Alexnet模型,提取出p5、或者f6、f7的特征,作为特征向量,然后进行训练svm,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择p5、f6、f7,这三层的神经元个数分别是9216、4096、4096。从p5到p6这层的参数个数是:4096x9216 ,从f6到f7的参数是4096x4096。那么具体是选择p5、还是f6,又或者是f7呢?
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
(4)为什么微调时和训练SVM时所采用的正负样本阈值【0.5和0.3】不一致?
微调阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松:Ground Truth+与Ground Truth相交IoU>0.5的建议框为正样本,否则为负样本;
SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本。
这里需要自己说明一下:是因为微调时和训练SVM时所采用的正负样本阈值不同,微调阶段正样本定义并不强调精准的位置,而SVM正样本只有Ground Truth;并且微调阶段的负样本是随机抽样的,而SVM的负样本是经过=hard negative mining方法筛选的。SVM训练时针对负样本要严格一些,所以IOU=0.3会使得负样本少了一些,严格了一些。
(5)为什么不直接采用微调后的AlexNet CNN网络最后一层SoftMax进行21分类【20类+背景】?
也可以认为:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,在训练的时候最后一层softmax就是分类层。那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别
训练过程的图片解析:
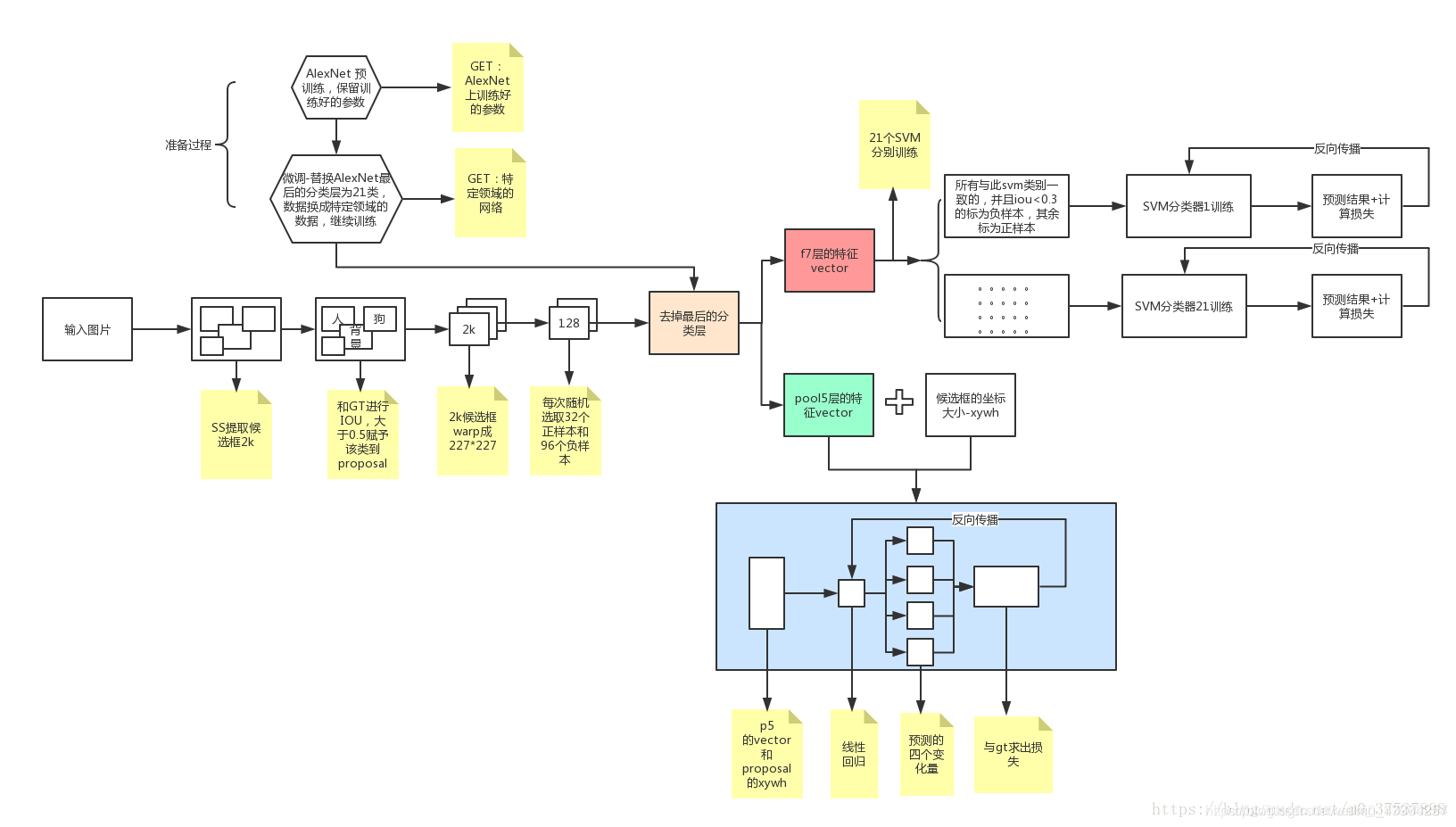
个人感觉这个图片稍微有一点点小问题,SVM训练应该有20个分类器,不应该是图中的21个。
5、测试
1、输入一张图像,利用selective search得到2000个region proposal。
2、对所有region proposal变换到固定尺寸并作为已训练好的CNN网络的输入,得到f7层的4096维特征,所以f7层的输出是2000x4096。
3、对每个类别,采用已训练好的这个类别的svm分类器对提取到的特征打分,所以SVM的weight matrix是4096xN,N是类别数,这里一共有20个SVM,N=20注意不是21。得分矩阵是2000x20,表示每个region proposal属于某一类的得分。
SVM类别判断:
从特征提取步骤中,生成一个4096维特征,将这个向量分别放入每一个SVM分类器中进行二值分类,并输出对每一个region proposal的4096维特征的得分.(这里的详细过程为:当我们用CNN提取2000个候选框,可以得到2000x4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096xN矩阵乘,得到2000xN的矩阵,就是每一个类对2000个候选框的打分,N为分类类别数目,就可以得到结果了)
4、用non-maximun suppression(NMS)对得分矩阵中的每一列中的region proposal进行剔除,就是去掉重复率比较高的几个region proposal,得到该列中得分最高的几个region proposal。NMS的意思是:举个例子,对于2000x20中的某一列得分,找到分数最高的一个region proposal,然后只要该列中其他region proposal和分数最高的IOU超过某一个阈值,则剔除该region proposal。【分数最高说明重叠度最高,最好,其他的和这个分数最高的候选框重叠度高说明其他的是多余的需要扔出】这一轮剔除完后,再从剩下的region proposal找到分数最高的,然后计算别的region proposal和该分数最高的IOU是否超过阈值,超过的继续剔除,【在从剩下的候选区找分数最高的是因为IOU没有超过那个阈值,说明这是另一个关于人的部分】直到没有剩下region proposal。对每一列都这样操作,这样最终每一列(即每个类别)都可以得到一些region proposal。
具体怎么做呢?
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
理解:
在R-CNN中对于2000多个region proposals得到特征向量(4096维)后,输入到SVM中进行打分(score)。除了背景以外VOC数据集共有20类。那么20004096维特征矩阵与20个SVM组成的权重矩阵409620相乘得到结果为2000*20维矩阵。这个矩阵2000行表示有2000个框。20列为每一个框属于这20个类的score(置信度)。也就是说每一列即每一类有2000个不同的分值。那么每一类有这么多候选框肯定大多冗余。所以需要利用非极大值抑制方法进行删除重叠候选框。
NMS算法的输入:2000个候选框的位置坐标(两个顶点的x,y坐标,共4个值)、score分数值(置信度)。
NMS算法的输出:所有满足筛选条件的建议框(可能不止一个)。
NMS算法的大致思想:对于有重叠的候选框:若大于规定阈值(某一提前设定的置信度)则删除,低于阈值的保留。
对于无重叠的候选框:都保留
**比如:**第一类有2000个候选框,得分分别是0.9 0.8 0.2 0.02 0.01 0.01…经过NMS前5步之后第一类也就是第一列剩下 0.9 0.8 0.2 0.02这四个。然后假设这一类是猫,然后会人为设定一个类别的得分域值比如0.5,就是这个框属于猫的类别得分太低,它就不是猫,很可能是背景,那0.9和0.8那两个框就留下来了。
5、用N=20个回归器对第4步得到的20个类别的region proposal进行回归,要用到pool5层的特征。pool5特征的权重W是在训练阶段的结果,测试的时候直接用。最终得到每个类别的修正后的得分最高的bounding box。
测试阶段几个问题:
(1)为什么要将建议框变形为227×227?怎么做?
本文采用AlexNet CNN网络进行CNN特征提取,为了适应AlexNet网络的输入图像大小:227×227,故将所有建议框变形为227×227。
== (1)各向异性缩放==
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227x227,如下图(D)所示;
(2)各向同性缩放
因为图片扭曲后,估计会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法
A、直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如下图(B)所示;
B、先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图©所示;
对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高。
(我理解padding就是将候选框的上下16个象素也取出来一同进行缩放)

(2)CNN特征如何可视化?
文中采用了巧妙的方式将AlexNet CNN网络中Pool5层特征进行了可视化。该层的size是6×6×256,即有256种表示不同的特征,这相当于原始227×227图片中有256种195×195的感受视野【相当于对227×227的输入图像,卷积核大小为195×195,padding=4,step=8,输出大小(227-195+2×4)/8+1=6×6】;
文中将这些特征视为”物体检测器”,输入10million的Region Proposal集合,计算每种6×6特征即“物体检测器”的激活量,之后进行非极大值抑制【下面解释】,最后展示出每种6×6特征即“物体检测器”前几个得分最高的Region Proposal,从而给出了这种6×6的特征图表示了什么纹理、结构,很有意思。
(3)为什么要进行非极大值抑制?
在测试过程完成到SVM之后,获得2000×20维矩阵表示每个建议框是某个物体类别的得分情况,此时会遇到下图所示情况,同一个车辆目标会被多个建议框包围,这时需要非极大值抑制操作去除得分较低的候选框以减少重叠框。

(4)为什么要采用回归器?回归器是什么有什么用?如何进行操作?
首先要明确目标检测不仅是要对目标进行识别,还要完成定位任务,所以最终获得的bounding-box也决定了目标检测的精度。
如下图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为selective search算法得出的建议框,即Region Proposal。即使黄色框中物体被分类器识别为卡宴车辆,但是由于绿色框和黄色框IoU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与selective search更接近, 以提高最终的检测精度。论文中采用bounding-box回归使mAP提高了3~4%。

那么问题来了,回归器如何设计呢?
具体参考:测试阶段的解析分析5
参考别人笔记做一下记录,如有侵权,请联系,立马删除
参考:
重要:目标检测算法之R-CNN算法详解
重要:R-CNN论文详解:回答了许多问题
重要:分析了很多问题
R-CNN系列详解
RCNN 简介
论文翻译


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









