







什么是主从复制
- 1个master可以有多个slave
- 1个slave只能有1个master
- 数据流向是单向的,master到slave
作用: - 为数据提供了多个副本
- 扩展了redis读的性能
复制的配置(不允许在同一台机器上部署主从节点)
两种方式:
- slaveof命令
- 配置
 将6380设置为6379的从节点
将6380设置为6379的从节点
 取消从节点,注意:取消从节点之后,之前复制的数据并不会被清除,只是断了与之前主节点的联系,但是如果成为了一个新主节点的从节点,那么就会复制新的主节点的数据,之前的数据就会被清除。
取消从节点,注意:取消从节点之后,之前复制的数据并不会被清除,只是断了与之前主节点的联系,但是如果成为了一个新主节点的从节点,那么就会复制新的主节点的数据,之前的数据就会被清除。
 第一条配置是设置成某一ip和端口号的从节点
第一条配置是设置成某一ip和端口号的从节点
第二条配置是设置只读不写,以保证和主节点数据的一致性
两种配置的比较

命令
设置主从节点的配置文件6379为主节点,6380为从节点
[root@iZ8vbhgs0bdip8zvxd6xjjZ redis-4.0.6]# ll
drwxr-xr-x 2 root root 4096 Nov 27 14:10 config
-rw-rw-r-- 1 root root 57765 Apr 3 2019 redis.conf
-rw-rw-r-- 1 root root 7606 Dec 5 2017 sentinel.conf
drwxrwxr-x 3 root root 4096 Nov 16 15:35 src
drwxrwxr-x 10 root root 4096 Dec 5 2017 tests
drwxrwxr-x 8 root root 4096 Dec 5 2017 utils
- 将主设置文件redis.conf复制到config文件夹
[root@iZ8vbhgs0bdip8zvxd6xjjZ redis-4.0.6]# cp redis.conf config
- 将主设置文件redis.conf复制到config文件夹
[root@iZ8vbhgs0bdip8zvxd6xjjZ redis-4.0.6]# cp redis.conf config
[root@iZ8vbhgs0bdip8zvxd6xjjZ redis-4.0.6]# cd config/
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# ll
total 64
-rw-r--r-- 1 root root 57765 Dec 15 14:51 redis.conf
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# cp redis.conf redis-6379.conf # 复制到redis-6379.conf
- 更改redis-6379.conf配置文件
daemonize yes # 以守护进程运行redis
pidfile /var/run/redis_6379.pid 将进程文件加上6379
logfile "6379.log" # 将log文件命名为6379.log
#save 900 1 # 这三个在生产环境中不会这样用,关掉
#save 300 10
#save 60 10000
dbfilename dump-6379.rdb # 将rdb文件命名为dump-6379.rdb(主从复制是依赖于rdb的,如果主从用一个rdb文件,会有一些影响)
- 配置redis-6380.conf配置文件
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# cp redis-6379.conf redis-6380.conf # 复制一个6380的配置文件
修改6380的配置文件
port 6380
pidfile /var/run/redis_6380.pid
logfile "6380.log"
dbfilename dump-6380.rdb
slaveof 127.0.0.1 6379
- 重新启动主节点
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-server redis-6379.conf
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# ps -ef | grep redis-server
root 6549 1 0 Nov16 ? 00:19:58 redis-server 127.0.0.1:6379
root 28005 27740 0 14:26 pts/0 00:00:00 grep --color=auto redis-server
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli # 打开客户端
127.0.0.1:6379> info replication # 查看复制区的信息
# Replication
role:master # 默认是主节点
connected_slaves:0 # 无从节点
master_replid:793ea29532c0cc6e58080ef322b5063c488bdb1c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
- 重新启动从节点
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-server redis-6380.conf
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# ps -ef | grep redis-server | grep 6380 # 查看是否启动成功
root 28015 1 0 14:31 ? 00:00:00 redis-server 127.0.0.1:6380
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6380 info replication # 查看从节点信息
# Replication
role:slave # 角色是从节点
master_host:127.0.0.1 主节点
master_port:6379 主节点端口
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
- 测试主从复制
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> dbsize
(integer) 1
127.0.0.1:6379> exit
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6380
127.0.0.1:6380> get hello
"world"
127.0.0.1:6380> set hello java # 该从节点只能做读操作
(error) READONLY You can't write against a read only slave.
- 取消从节点
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6380
127.0.0.1:6380> slaveof no one
OK
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli
127.0.0.1:6379> mset a b c d e f g h
OK
127.0.0.1:6379> dbsize
(integer) 6
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli
127.0.0.1:6379> mset a b c d e f g h
OK
127.0.0.1:6379> dbsize
(integer) 6
127.0.0.1:6379> exit
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6380
127.0.0.1:6380> dbsize
(integer) 2
127.0.0.1:6380> set abc6380 hello
OK
127.0.0.1:6380>
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 再次设置为从节点
OK
127.0.0.1:6380> get abc6380 # 会对之前的数据进行清除
(nil)
runid和复制偏移量
什么是runid?
redis每次启动的时候都会随机生成一个runid,以保证redis的标识
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6379 info server | grep run
run_id:2abbf0e2f01c0d4ba7bf02cd778af9883f2460d9
偏移量
[root@iZ8vbhgs0bdip8zvxd6xjjZ config]# redis-cli -p 6379 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=7175,lag=0 # 从节点偏移量
master_replid:5bc6138e8f770cc3ec183c89bbabfe904a0a9bb9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7175 # 主节点偏移量
全量复制和部分复制
对于一个已经存了很多数据的master节点而言,slave节点需要复制master节点的数据,将当前master数据同步过来,master在这期间写的数据也要同步过来,这样才能实现数据真正同步的效果。那么redis是怎么实现这个功能呢?
首先将自己的Rdb文件同步给slave,在此期间它写入的命令会单独记录起来,然后当rdb文件加载完之后,他会通过偏移量的对比,将这期间写入的值同步给slave。
全量复制的开销
- bgsave的时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载RDB文件的时间
- 可能的AOF重写时间 (RDB文件加载之后,如果AOF开启的话,需要AOF重写,以保证AOF是最新的数据)
部分复制
如果master和slave之间的网络发生抖动,那一段时间内数据就会发生丢失, 此时slave会向master发送一个命令,其中包含自己的offset和runid,那么master就会根据从节点的偏移量和自己的buffer进行比较,然后从上一次数据传输的断点开始继续传输数据。
故障处理
自动故障转移
主从结构中怎么处理故障转移?
- slave故障
假如在一主两从结构中,一个slave发生故障,可以将客户端转移到另一个slave节点读取数据 - master故障
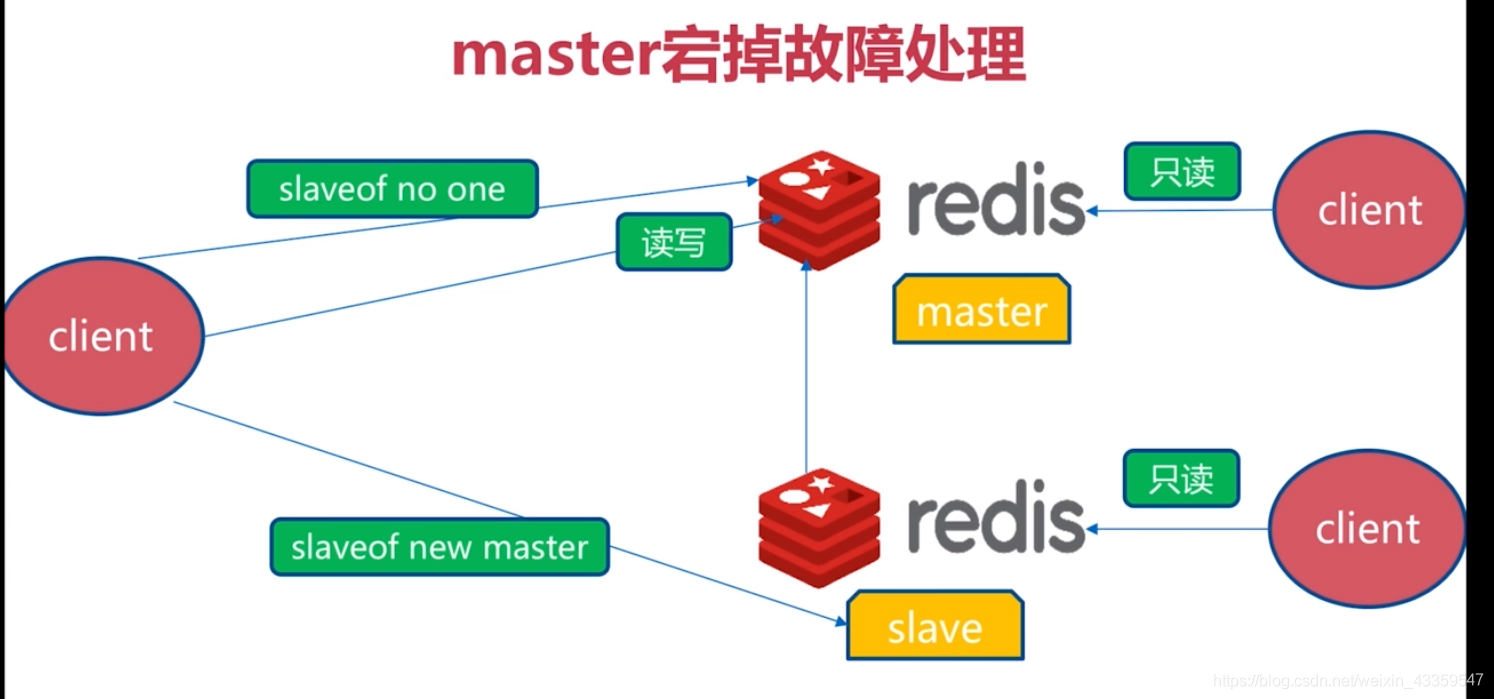 选择其中一个从节点为主节点进行读写操作,并且将另一个从节点更换一个master。
选择其中一个从节点为主节点进行读写操作,并且将另一个从节点更换一个master。
开发运维常见问题
- 读写分离
读流量分摊到从节点
可能遇到的问题:- 复制数据延迟(如果从节点出现阻塞,那么就会延迟更新从主节点复制的数据)
- 读到过期数据
- 从节点故障
- 主从配置不一致
可能遇到的问题:- 例如maxmemory不一致:丢失数据
- 例如数据结构优化参数(例如hash-max-ziplist-entries):内存不一致
- 规避全量复制
可能遇到的问题:- 第一次全量复制不可避免(小主节点、低峰)
- 节点运行ID不匹配(例如:主节点重启,运行ID变化,可以故障转移,例如哨兵或集群)
- 复制积压缓冲区不够(例如:网络中断,部分复制无法满足,可以增大复制缓冲区配置rel_backlog_size,网络“增强”)
- 规避复制风暴
可能遇到的问题:- 单主节点复制风暴(主节点重启,多从节点复制,可以改变复制拓扑)
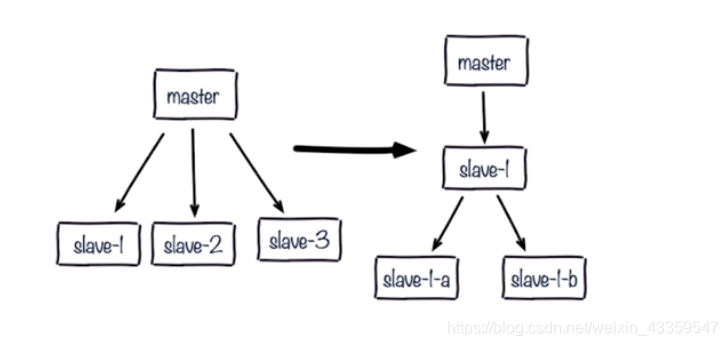
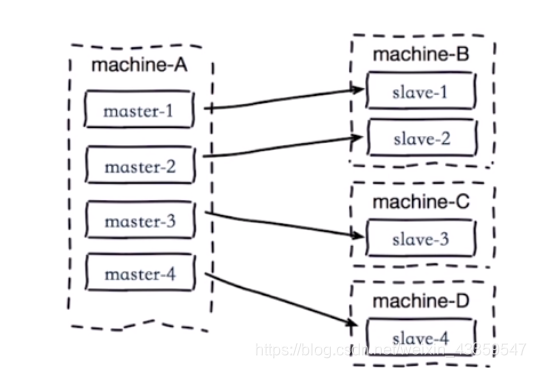
- 单机器复制风暴(机器宕机后,大量全量复制,可以主节点分散多机器)
- 单主节点复制风暴(主节点重启,多从节点复制,可以改变复制拓扑)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









