






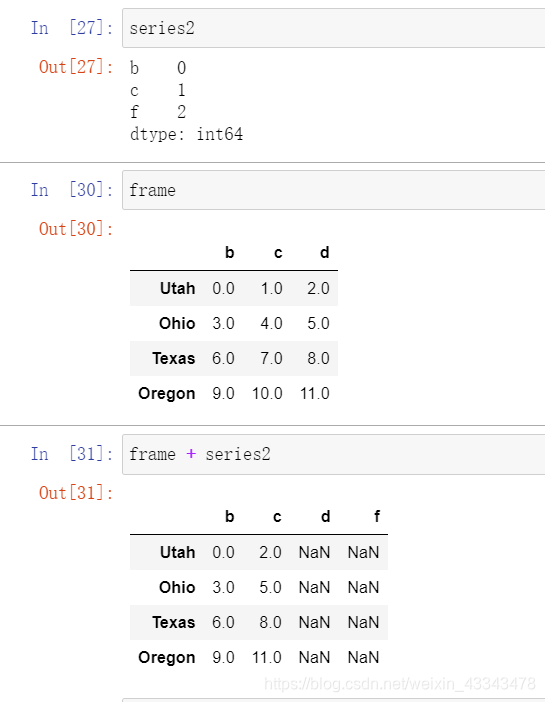
- DataFrame和Series的维度不同,在线性代数中是无法进行乘积运算的,但在pandas中是可以进行运算的。,但需要注意的是,pandas中是将Series缺失的维度进行广播(将缺失的维度用原数据进行补齐,然后运算)。
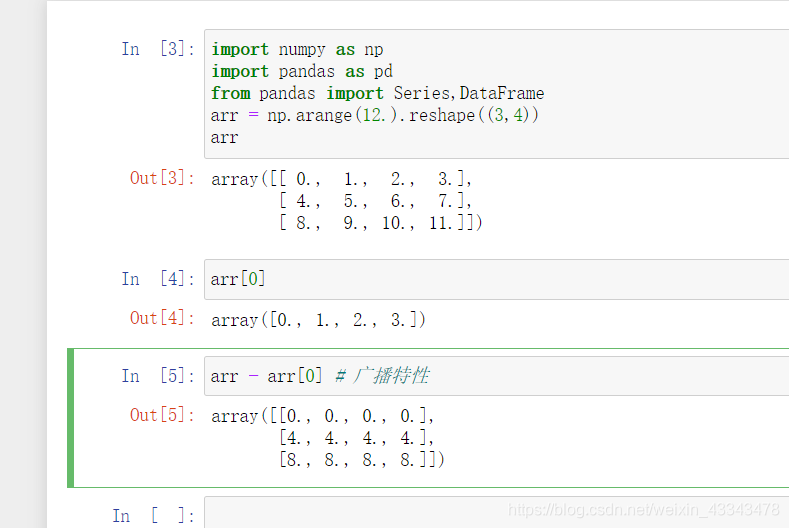
- 运算时,如果在DataFrame中没找到对应的index,或者在Series中没有找到对应的columns,那么对象会重新索引以形成联盟,同时series进行广播。
即两者都有的index(columns)进行相应的运算,其中一个有而另一个没有的columns会以NaN的数值存在
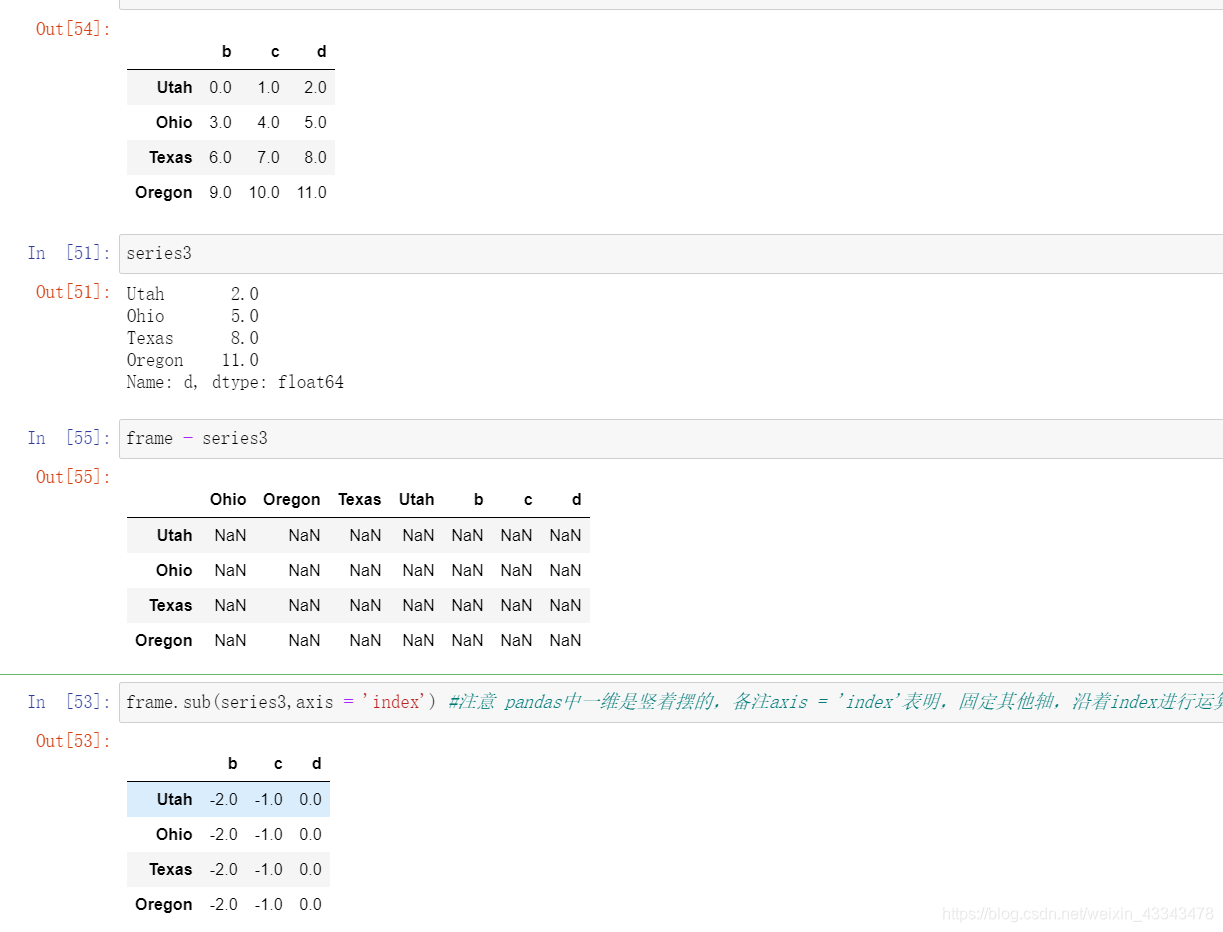
- Pandas中一维数组是竖着摆的!
Python—Pandas学习之【DataFrame和Series之间的操作】
最新推荐文章于 2025-03-17 08:15:00 发布


















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









