









 本文介绍了两种Scrapy框架下的爬虫策略:一是设置ROBOTSTXT_OBEY为False,直接忽略robots.txt规则,但易导致IP被封;二是保持ROBOTSTXT_OBEY为True,通过修改USER_AGENT来模仿目标网站支持的爬虫,实现更隐蔽的爬取方式。
本文介绍了两种Scrapy框架下的爬虫策略:一是设置ROBOTSTXT_OBEY为False,直接忽略robots.txt规则,但易导致IP被封;二是保持ROBOTSTXT_OBEY为True,通过修改USER_AGENT来模仿目标网站支持的爬虫,实现更隐蔽的爬取方式。
参考文章:https://blog.youkuaiyun.com/zzk1995/article/details/51628205
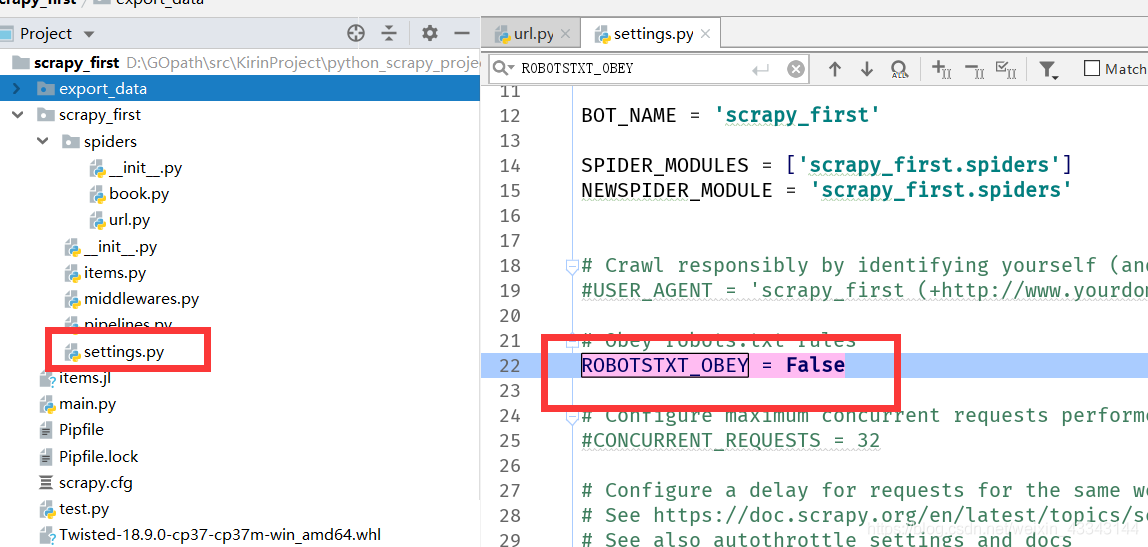
方法一:设置ROBOTSTXT_OBEY = False,这种不推荐(非万不得已),强行爬虫容易封ip
scrapy框架这个属性设置为False即可(默认为True)
ROBOTSTXT_OBEY = False
第二种方法就是不改变 ROBOTSTXT_OBEY=True的默认值,而伪装平台支撑的爬虫(推荐这种方式)
# Crawl responsibly by identifying yourself (and your website) on the user-agent
你要爬虫那个网站,就伪装它支持的爬虫平台,如百度阅读支持百度的爬虫
https://yuedu.baidu.com/robots.txt第一个User-agent: Baiduspider
USER_AGENT = 'Baiduspider'
# Obey robots.txt rules(默认是禁止爬虫设置了robots.txt文件的网站)
ROBOTSTXT_OBEY = True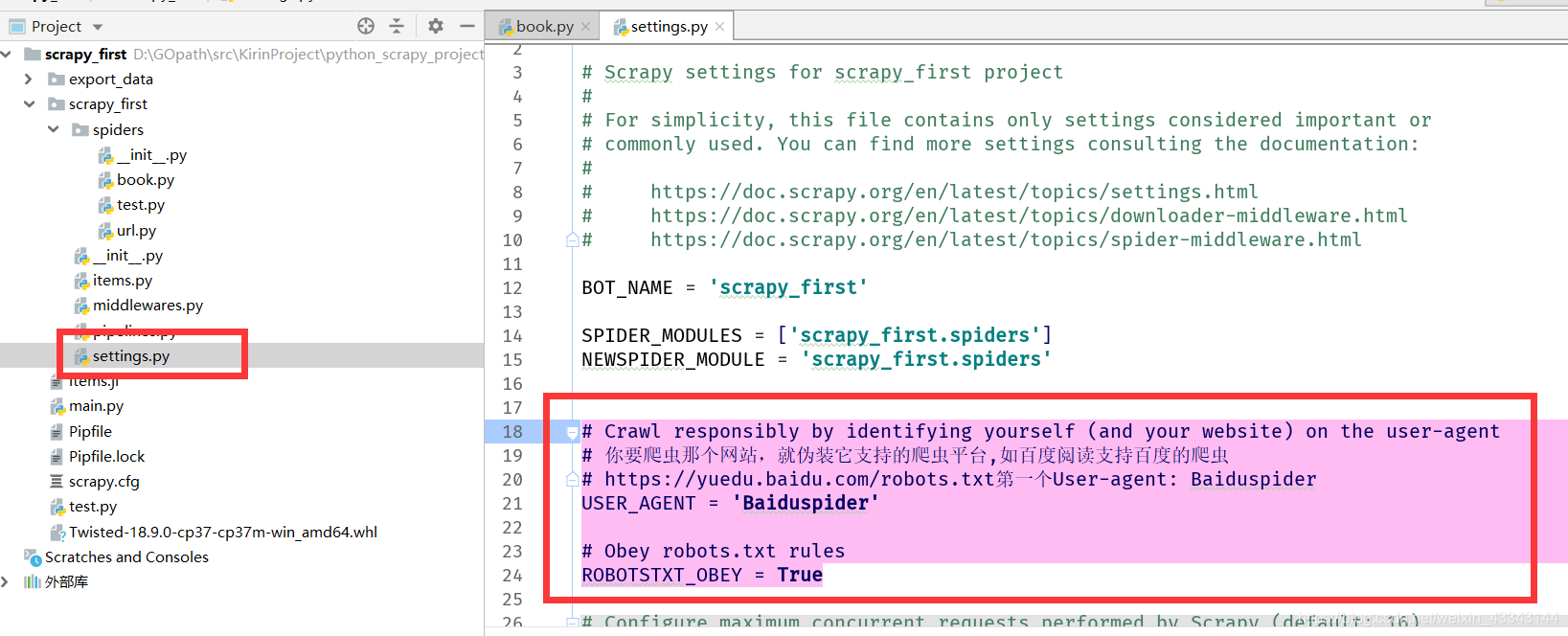

















 57
57

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









