







 超级会员免费看
超级会员免费看
 本文介绍了Spark中的核心概念RDD,包括其作为不可变、可分区数据集的特性,以及RDD的5大特性与特点,如分区、只读、依赖关系、缓存和检查点等,阐述了RDD在并行计算中的作用和如何通过RDD实现数据处理流程。
本文介绍了Spark中的核心概念RDD,包括其作为不可变、可分区数据集的特性,以及RDD的5大特性与特点,如分区、只读、依赖关系、缓存和检查点等,阐述了RDD在并行计算中的作用和如何通过RDD实现数据处理流程。
前言
之前的文章主要介绍Spark基础知识,例如集群角色、Spark集群运行流程等,接下来会进一步讨论Spark相对核心的知识,让我们拭目以待,同时也期待各位的精彩留言!
一、RDD简介
RDD称为弹性分布式数据集,是Spark中最基本的数据抽象,其为一个不可变、可分区、元素可并行计算的集合;RDD中的数据是分布式存储,可用于并行计算,同时,RDD中的数据可以存储在内存或者磁盘中,这就是“弹性”的意义所在。
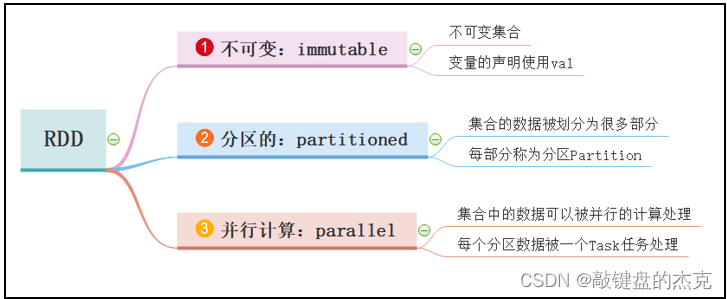
二、RDD的特性
RDD有5大特性,前三个特性是每个RDD必备的,而后面两个特性是可选的,特性分别为:
(1)RDD数据集可分区;
(2)一个函数会作用在RDD的每一个分区上;
(3)RDD间存在依赖关系,RDD的每一次转换都会生成一个全新的RDD,新旧RDD间存在依赖关系,当分区的部分数据丢

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











