







 本文详细介绍了Spark的特征、工作流程、运行方式,重点讨论了Spark SQL的兼容性、性能优化策略,包括参数和代码层面的优化。此外,还探讨了Spark MLlib机器学习库、PySpark使用、Spark Streaming与Storm的比较以及Spark Streaming集成Kafka的场景。
本文详细介绍了Spark的特征、工作流程、运行方式,重点讨论了Spark SQL的兼容性、性能优化策略,包括参数和代码层面的优化。此外,还探讨了Spark MLlib机器学习库、PySpark使用、Spark Streaming与Storm的比较以及Spark Streaming集成Kafka的场景。
目录
(3)在进行表连接的时候,将小表广播可以提高性能,spark2.+中可以调整参数
(6)写数据库的时候,关闭自动提交,不要每条提交一次,自己手动每个批次提交一次
5、 机器学习工作流(ML Pipelines)—— spark.ml包
1. RDD(Resilient Distributed Dataset):弹性分布式数据集,是记录的只读分区集合,是Spark的基本数据结构。RDD代表一个不可变、可分区、里面的元素可并行计算的集合。RDD的依赖关系分为两种:窄依赖(Narrow Dependencies)、宽依赖(Wide Dependencies)。Spark会根据宽依赖窄依赖来划分具体的Stage,依赖可以高效地解决数据容错。
- 窄依赖:每个父RDD的一个Partition最多被子RDD的一个Partition所使用(1:1 或 n:1)。例如map、filter、union等操作都会产生窄依赖。
子RDD分区与数据规模无关; - 宽依赖:一个父RDD的Partition会被多个子RDD的Partition所使用(1:m 或 n:m),例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖。
子RDD分区与数据规模有关。
2. DAG(Directed Acyclic Graph):有向无环图,在Spark里每一个操作生成一个RDD,RDD之间连成一条边,最后生成的RDD和他们之间的边组成一个有向无环图。有了计算的DAG图,Spark内核下一步的任务就是根据DAG图将计算划分成任务集,也就是Stage。
3. RDD与DAG的关系:Spark计算的中间结果默认保存在内存中,Spark在划分Stage的时候会充分考虑在分布式计算中,可流水线计算(pipeline)的部分来提高计算效率,而在这个过程中Spark根据RDD之间依赖关系的不同,将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算;对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
4. Application:用户编写的Spark应用程序。
5. Job:一个作业包含多个RDD及作用于相应RDD上的各种操作。
6. Task:任务运行在Executor上的工作单元,是Executor中的一个线程。
三者关系:Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成,Executor进程以多线程的方式运行Task。
7. Action:该操作将触发基于RDD依赖关系的计算。
8. Transformation:该转换操作具有懒惰执行的特性,它只指定新的RDD和其父RDD的依赖关系,只有当Action操作触发到该依赖的时候,它才被计算。
9. PairRDD:指数据为Tuple2数据类型的RDD,其每个数据的第一个元素被当做key,第二个元素被当做value。
10. 持久化操作:声明对一个RDD进行cache后,该RDD不会被立即缓存,而是等到它第一次因为某个Action操作触发后被计算出来时才进行缓存。可以使用persist明确指定存储级别,常用的存储级别是MEMORY_ONLY和MEMORY_AND_DISK。
11. 共享变量:当Spark集群在许多节点上运行一个函数时,默认情况下会把这个函数涉及到的对象在每个节点生成一个副本。但是,有时候需要在不同节点或者节点和Driver之间共享变量。Spark提供两种类型的共享变量:广播变量、累加器。
- 广播变量:不可变变量,实现在不同节点不同任务之间共享数据;广播变量在每个节点上缓存一个只读的变量,而不是为每个task生成一个副本,可以减少数据的传输。
- 累加器:主要用于不同节点和Driver之间共享变量,只能实现计数或者累加功能;累加器的值只有在Driver上是可读的,在节点上只能执行add操作。
12. 广播变量:
- 广播变量是一个只读变量,通过它我们可以将一些共享数据集或者大变量缓存在Spark集群中的各个机器上而不用每个task都需要copy一个副本,后续计算可以重复使用,减少了数据传输时网络带宽的使用,提高效率。相比于Hadoop的分布式缓存,广播的内容可以跨作业共享。
- 广播变量要求广播的数据不可变、不能太大但也不能太小(一般几十M以上)、可被序列化和反序列化、并且必须在driver端声明广播变量,适用于广播多个stage公用的数据,存储级别目前是MEMORY_AND_DISK。
- 广播变量存储目前基于Spark实现的BlockManager分布式存储系统,Spark中的shuffle数据、加载HDFS数据时切分过来的block块都存储在BlockManager中。
二、Spark特征
高效性:不同于MapReduce将中间计算结果放入磁盘中,Spark采用内存存储中间计算结果,减少了迭代运算的磁盘IO,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间。
易用性:Spark提供了超过80种不同的算子,如map,reduce,filter,groupByKey,sortByKey,foreach等;Spark task以线程的方式维护,对于小数据集读取能够达到亚秒级的延迟。
通用性:Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
兼容性:Spark能够跟很多开源工程兼容使用。如Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且Spark可以读取多种数据源,如HDFS、HBase、MySQL等。
Spark运行架构特点:
- 每个Application均有专属的Executor进程,并且该进程在Application运行期间一直驻留;
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可;
- Task采用了数据本地性和推测执行等优化机制。
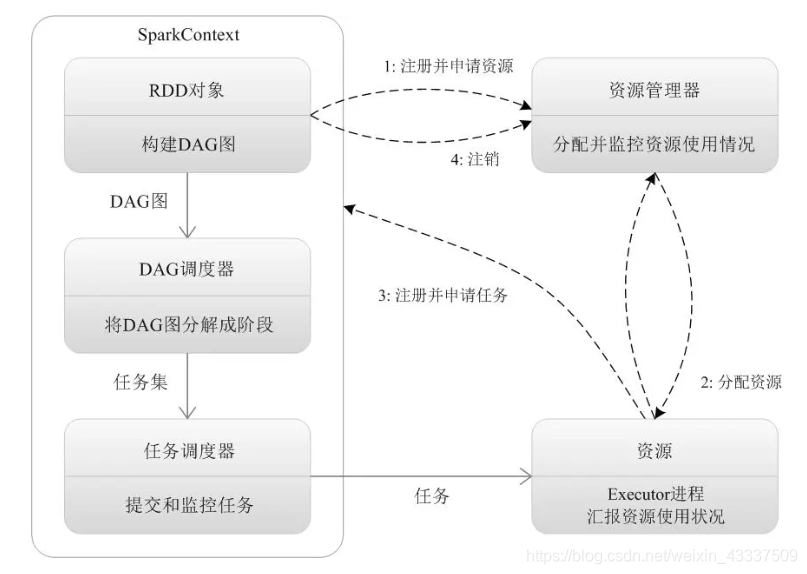
三、Spark整体工作流程
- 构建Spark Application运行环境;
- SparkContext向资源管理器注册;
- SparkContext向资源管理器申请运行Executor;
- 资源管理器分配Executor;
- 资源管理器启动Executor;
- Executor发送心跳至资源管理器;
- SparkContext构建成DAG图;
- 将DAG图分解成Stage(TaskSet);
- 把Stage(TaskSet)发送给TaskScheduler;
- Executor向SparkContext申请Task;
- TaskScheduler将Task发送给Executor运行;同时SparkContext将应用程序代码发放给Executor;
- Task在Executor上运行,运行完毕释放所有资源。
四、Spark运行方式
spark本身是用Scala编写的,spark1.4.0 起支持R语言和Python3编程。
- 通过spark-shell进入Spark交互式环境,使用Scala语言;
- 通过spark-submit提交Spark应用程序进行批处理;该方法可以提交Scala或Java语言编写的代码编译后生成的jar包,也可以直接提交Python脚本。
- 通过pyspark进入pyspark交互式环境,使用Python语言;该方式可以指定jupyter或者ipython为交互环境。
- 通过zepplin notebook交互式执行;zepplin在jupyter notebook里。
- 安装Apache Toree-Scala内核,可以在jupyter 中运行spark-shell。使用spark-shell运行时,可以添加两个常用的两个参数:master指定使用何种分布类型;jars指定依赖的jar包。
五、Spark SQL
Spark SQL 是从shark发展而来。
1、Spark SQL兼容性
Spark SQL在Hive兼容层面仅依赖HQL parser、Hive Metastore和Hive SerDe(后两者用于兼容Hive存储格式)。
- 从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管。
- 执行计划生成和优化都由Catalyst负责,借助Scala的模式匹配等函数式语言特性,利用Catalyst开发执行计划优化策略比Hive要简洁得多。
2、Spark SQL编码方式tips
- 直接通过Spark编码:需提前声明构建SQLContext或者是SparkSession(Spark2之后建议使用);
- spark-sql(shell)脚本编码:启动前可以通过bin/spark-sql –help 查看配置参数,调整部署模式资源等;
- Thriftserver编码:基于HiveServer2实现的一个Thrift服务,旨在无缝兼容HiveServer2。部署好Spark Thrift Server后,可以直接使用hive的beeline访问Spark Thrift Server,执行相关语句。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









