







 该博客详细介绍了Kaggle泰坦尼克号生存预测问题的数据预处理过程,包括导入数据集、探索性分析、填补缺失值、归一化和标准化。博主关注了Pclass、Sex、Embarked、Age、Fare等关键特征与生存率的关系,并用线性模型进行预测,最终在Kaggle上取得了0.7606的分数。
该博客详细介绍了Kaggle泰坦尼克号生存预测问题的数据预处理过程,包括导入数据集、探索性分析、填补缺失值、归一化和标准化。博主关注了Pclass、Sex、Embarked、Age、Fare等关键特征与生存率的关系,并用线性模型进行预测,最终在Kaggle上取得了0.7606的分数。
整理了一下全部流程,写成了一个ipynb文件
导入数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
##载入数据集
data_path = 'D:/Now/Titanic/'
train_data = pd.read_csv(data_path + 'train.csv',sep = ',')
test_data = pd.read_csv(data_path + 'test.csv',sep = ',')
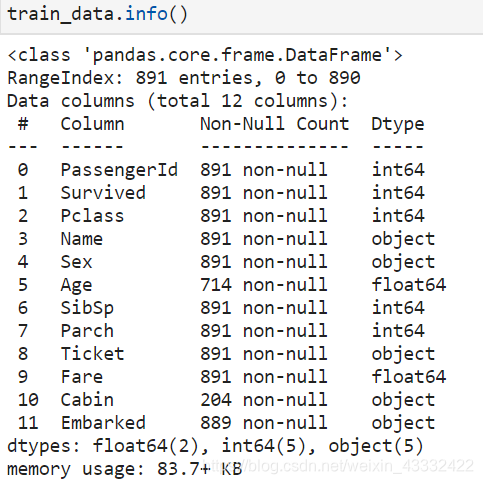
train_data.info()
数据探索性分析
##查看缺失值
train_miss_data = train_data.isnull().sum()
train_miss_data = train_miss_data[train_miss_data>0]
train_miss_data.plot.bar()
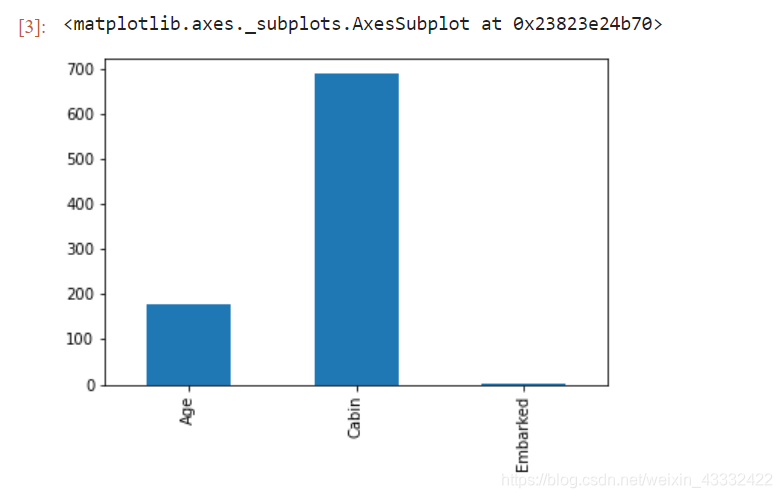
在train_data的缺失值中,可以看到Cabin的缺失值比较多。Age的缺失值相对来说也比较多
train_data.head(10)

Pclass,Cabin,Embarked,Ticket,Sex,Survived是定性数据,Fare,SibSp,Parch,Age是定量数据。
查看Embarked数据
查阅资料得知:泰坦尼克号从英国南安普敦(Southampton)港出发,途经法国瑟堡-奥克特维尔(Cherbourg-Octeville)以及爱尔兰昆士敦(Queenstown),计划中的目的地为美国纽约(New York),开始了这艘“梦幻客轮”的处女航。
train_data['Embarked'].value_counts()

将Embarked转换成数值型数据
#train_data将S转为1,C转为2,Q转为3
train_data['Embarked'].replace('S',1,inplace=True)
train_data['Embarked'].replace('C',2,inplace=True)
train_data['Embarked'].replace('Q',3,inplace=True)
train_data['Embarked'].value_counts()
'''
1.0 644
2.0 168
3.0 77
Name: Embarked, dtype: int64
'''
#test_data将S转为1,C转为2,Q转为3
test_data['Embarked'].replace('S',1,inplace=True)
test_data['Embarked'].replace('C',2,inplace=True)
test_data['Embarked'].replace('Q',3,inplace=True)
test_data['Embarked'].value_counts()
'''
1 270
2 102
3 46
Name: Embarked, dtype: int64
'''
查看Sex数据
train_data['Sex'].value_counts()

将Sex转换成数值型数据
#train_data将male转换成1,female转换成2
train_data['Sex'].replace('male',1,inplace=True)
train_data['Sex'].replace('female',2,inplace=True)
train_data['Sex'].value_counts()
'''
1 577
2 314
Name: Sex, dtype: int64
'''
#test_data将male转换成1,female转换成2
test_data['Sex'].replace('male',1,inplace=True)
test_data['Sex'].replace('female',2,inplace=True)
test_data['Sex'].value_counts()
'''
1 266
2 152
Name: Sex, dtype: int64
'''
转换之后查看相关性
abs(train_data.corr(method='pearson')).plot(kind='bar')
plt.legend(loc = 'best')
abs(train_data.corr(method='pearson'))


查看存活情况和其他数据的相关性
abs(train_data.corr(method='pearson'))['Survived']
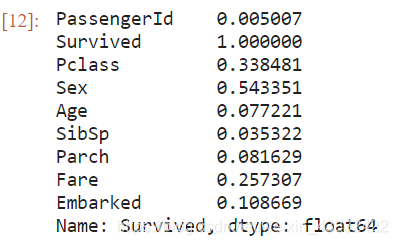
可以看到,Sex,Pclass,Fare与Survived都有较明显的相关性
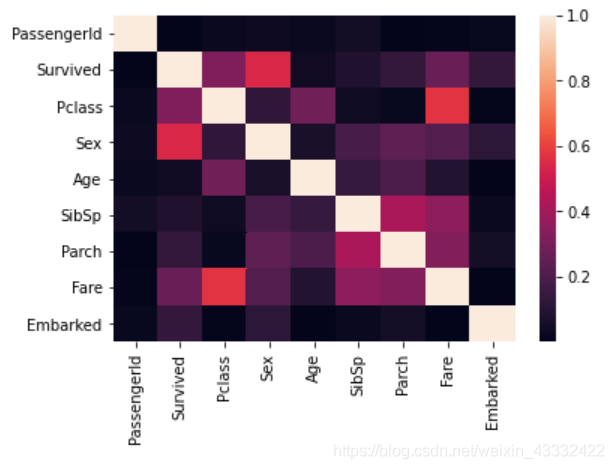
换个图看看:
sns.heatmap(abs(train_data.corr(method='kendall')))
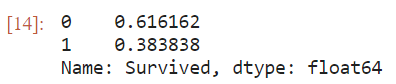
train_data['Survived'].value_counts(normalize=True)
#空准确率 有38%的人获救
##对每一列绘制图观察
cols = ['Age','SibSp','Parch','Fare']
for i in cols:
sns.distplot(train_data[train_data['Survived']==0][i],label='notSurvived',kde=False)
sns.distplot(train_data[train_data['Survived']==1][i],label='Survived',kde=False)
# plt.hist(train_data[train_data['Survived']==0][i],10,alpha = 0.5,label='notSurvived')
# plt.hist(train_data[train_data['Survived']==1][i],10,alpha = 0.5,label='Survived')
plt.legend(loc = 'best')
plt.xlabel(i)
plt.ylabel('count')
plt.show()
col = ['Pclass','Sex', 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









