







 批量规范化(BatchNorm)是解决深度网络训练困难的策略之一,它通过内部协变量转移(Internal Covariate Shift)的概念来加速训练。本文详细介绍了BatchNorm的工作原理,包括归一化、缩放和平移的过程,以及在训练和测试阶段的应用。BatchNorm不仅加速训练,还可以作为正则化手段,甚至在某些情况下可以替代dropout。
批量规范化(BatchNorm)是解决深度网络训练困难的策略之一,它通过内部协变量转移(Internal Covariate Shift)的概念来加速训练。本文详细介绍了BatchNorm的工作原理,包括归一化、缩放和平移的过程,以及在训练和测试阶段的应用。BatchNorm不仅加速训练,还可以作为正则化手段,甚至在某些情况下可以替代dropout。
参考出处:https://blog.youkuaiyun.com/qq_25737169/article/details/79048516
在上一篇关于解决梯度消失和梯度爆炸的介绍中提到了其中一种方法就是采用batchnorm,可译为批量规范化,这篇介绍就好好讲讲batchnorm的相关概念。
就跟我们之前谈到,训练深度网络的时候经常发生训练困难的问题,原因是因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了),此现象称之为Internal Covariate Shift(内部协变量转换)。
Internal Covariate Shift和Covariate Shift具有相似性,但并不是一个东西,前者发生在神经网络的内部,所以是Internal,后者发生在输入数据上。Covariate Shift主要描述的是由于训练数据和测试数据存在分布的差异性,给网络的泛化性和训练速度带来了影响,我们经常使用的方法是做归一化或者白化,如下图:
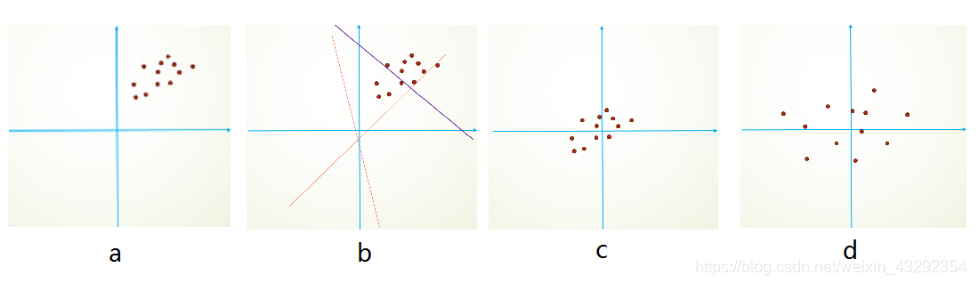
假设我们的数据分布如a所示,参数初始化一般是0均值,和较小的方差,此时拟合的y=wx+b如b图中的橘色线,经过多次迭代后,达到紫色线,此时具有很好的分类效果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









