




 本文详细探讨了语音识别中的动态解码器、WFST静态解码和Lattice技术,包括Viterbi算法、树形词典、剪枝优化、WFST的使用以及混合解码策略,旨在提升大词典下的解码效率和准确性。
本文详细探讨了语音识别中的动态解码器、WFST静态解码和Lattice技术,包括Viterbi算法、树形词典、剪枝优化、WFST的使用以及混合解码策略,旨在提升大词典下的解码效率和准确性。
解码为给定声学观测序列的前提下,找到最有可能出现的词序列
,由贝叶斯得:
解码的目的:从解码空间中找到一条或多条从初始状态到终止状态的最优路径。
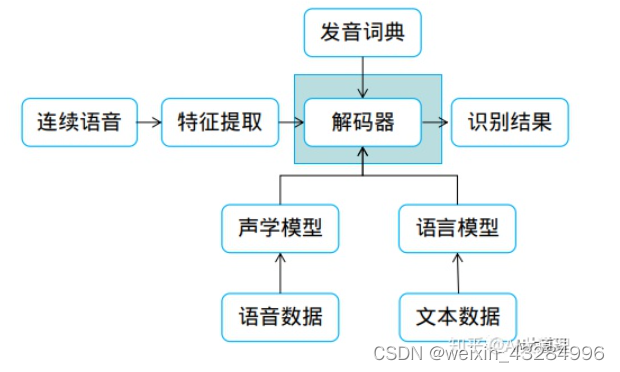
解码器是语音识别系统中的重要一环,主要解码方式有以下几种:
1)动态解码器 (dynamic decoders):动态解码器使用广度优先搜索在原始的搜索网络中同时生成多条假设,并且依靠剪枝算法不会使网络变得太大。
2)有限加权状态转换器 (weighted finte-state transducers ):加权有限状态转换器是使用有限状态自动机算法来表示和优化状态级网络结构,并用最短路径算法搜索得到的图结构。
3)多通道搜索 (multi-pass search):最初使用词内二元语言模型。 可以使用一些简单的模型来生成多个假设;在第一遍获得的 N-best list 或词网格上使用更准确的词间模型重新评分假设。
基于Viterbi的原始动态解码器:
基于Viterbi的原始动态解码器使用广度优先搜索在原始的搜索网络中同时生成多条假设,并且依靠剪枝算法不会使网络变得太大。
动态解码网络仅仅把词典编译为状态网络,构成搜索空间。
以一个四单词词典来举例,其词典包涵以下四个单词:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









