




不说了,直接使用别人的表来做一个测试表吧
-- 建表
create table student_scores(
id int,
studentId int,
language int,
math int,
english int,
classId string,
departmentId string
);
-- 写入数据
insert into table student_scores values
(1,111,68,69,90,'class1','department1'),
(2,112,73,80,96,'class1','department1'),
(3,113,90,74,75,'class1','department1'),
(4,114,89,94,93,'class1','department1'),
(5,115,99,93,89,'class1','department1'),
(6,121,96,74,79,'class2','department1'),
(7,122,89,86,85,'class2','department1'),
(8,123,70,78,61,'class2','department1'),
(9,124,76,70,76,'class2','department1'),
(10,211,89,93,60,'class1','department2'),
(11,212,76,83,75,'class1','department2'),
(12,213,71,94,90,'class1','department2'),
(13,214,94,94,66,'class1','department2'),
(14,215,84,82,73,'class1','department2'),
(15,216,85,74,93,'class1','department2'),
(16,221,77,99,61,'class2','department2'),
(17,222,80,78,96,'class2','department2'),
(18,223,79,74,96,'class2','department2'),
(19,224,75,80,78,'class2','department2'),
(20,225,82,85,63,'class2','department2');
聚合开窗函数
count开窗函数
先把department1的给弄出来

测试1:
select studentid,math,departmentld,classid,
count(math) over() as count1 from student_scores where departmentld='department1';
从这里可以看到,我们如果简单的使用count(math)是不行的,所以需要开窗,为每个属于department1条件的行都过来成为一组,然后count(math)默认将整个筛选出来的成为一组,除非里面有分区函数,那么直接将所有的行math聚合,然后作为一列给每一行都附上
测试2
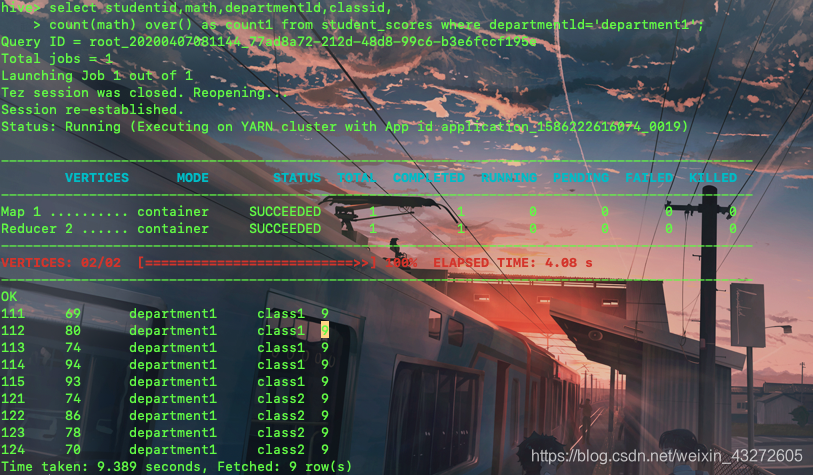
select studentid,math,departmentld,classid,
count(math) over(partition by classid) as count2 from student_scores where departmentld='department1';
**这个结果就有意思了,可以看到这个SQL我们在over里面根据classid分区了,那么count2这一列,就是class1的都是5,class2的都是4,看看class1的个数是5,class2的总数也确实是4,那么的确可以哦,根据分组了之后仍然可以为每一行做一个汇总

测试3
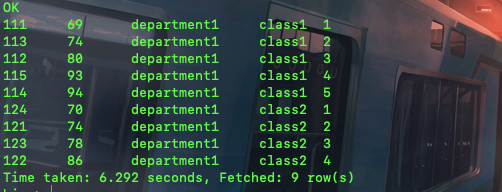
select studentid,math,departmentld,classid,
count(math) over(partition by classid order by math) as count3 from student_scores where departmentld='department1';
看一看,这一次除了分区外,我还加了一个order by,这个就会又一个累计过程,比如对于class1来说,数学分数从低到高分别是69,74,80,93,94,那么这个count(math)就会又一个累计过程,相当于每一行记录的是目前为止的math count数,比如对于69分数来说,它和它之前只有1个,对于74来说就只有2个,那么就相当于一个累计过程,到最后一个94,就相当于累计了5个了。
对于class2也是一样的
测试4
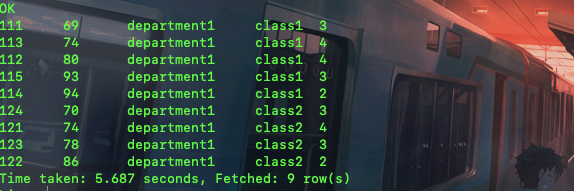
select studentid,math,departmentld,classid,
count(math) over(partition by classid order by math
rows between 1 preceding and 2 following)
as count4 from student_scores where departmentld='department1';
这个语句可以看到,除了上面的order by之外,我还添加了一个语句就是 rows between 1 preceding and 2 following ,这个rows between代表之间的,而preceding代表往前的行数,following代表往后的行数。
看看,对于class1来说,它首先根据class分组了,然后根据math排序了,那么rows between 1 preceding and 2 following 就是计算前一行一直到后两行一共有多少个。比如,对于math为69的来说,也就是第一行,那么往前一行,没有,往后两行,也就是第三行,这三行做count(math)是3,同理第二行,前一行有一直到后两行一直是4行,而对于最后一行,即从前一行一直到自己这一行,因为后面属于class1的没有了,那么就只有两行了。
那么细心的就会发现,上面的没有这个rows between的就是默认从当前组的期待到末尾
PRECEDING:往前 FOLLOWING:往后 CURRENT ROW:当前行 UNBOUNDED:无边界,UNBOUNDED
PRECEDING 表示从最前面的起点开始, UNBOUNDED FOLLOWING:表示到最后面的终点
–其他AVG,MIN,MAX,和SUM用法一样
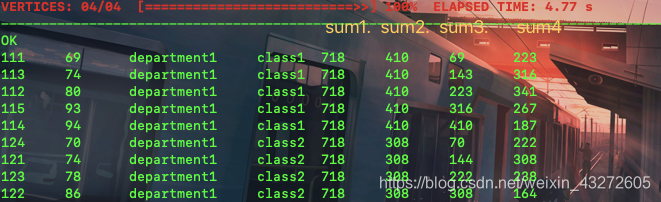
Sum开窗函数

**可以看到,这个partition+orderby同样是一个累计过程,只是这次是根据sum累计了,count是根据count累计的,那么同理sum4是一边累计一边定制了起始点和终点。
Min开窗函数

**和上面结果一样咯,min2,根据分区找自己分区最小的,而min3是分区之外加排序,有个类似于reduce的累计过程,窗口不断变大。min4就是
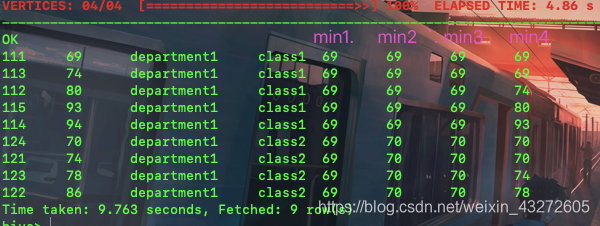
max,avg函数也是同样道理,这里就不演示了
简单来看上面的过程就是一次次reduce过程,窗口的话就是逐渐变大的过程。每次往窗口添加一个元素
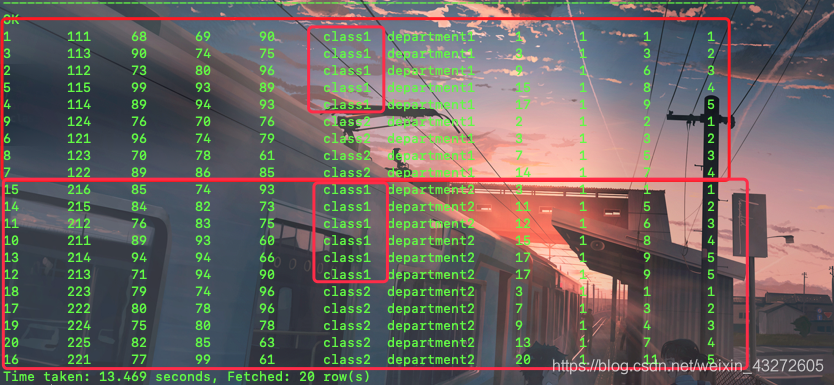
rank开窗函数
rank应该是不支持自定义窗口的,也就是说是全局的或者分区全局

第一个rank根据了math排序,那么分别对应了名次了
第二个rank没有多大意义不要管
第三个rank就是根据departmentld分区后然后根据math排序,就有了rank3
第四个rank就是根据department和class分区,然后排序,就有了四个1名,分别对应的是某个department某个class里面的东西



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











