











欢迎关注微信公众号:小满锅
前期准备
安装docker
yum安装
#安装 Docker
$ yum -y install docker
#启动 Docker 后台服务
$ service docker start
脚本安装
$ sudo yum update
$ curl -fsSL https://get.docker.com -o get-docker.sh
# 执行这个脚本会添加 docker.repo 源并安装 Docker。
$ sudo sh get-docker.sh
安装docker-compose
# 获取脚本
$ curl -L https://github.com/docker/compose/releases/download/1.25.0-rc2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
# 赋予执行权限
$chmod +x /usr/local/bin/docker-compose
镜像加速
打开/创建 /etc/docker/daemon.json 文件,添加以下内容:
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
搭建基本容器镜像
#镜像拉取
docker pull centos7
#创建一个容器,作为基础容器,后期制作为镜像
docker run -it --name hadoopimages centos /bin/bash
#将scala和jdk的包拷贝到容器里
docker cp scala-2.11.12.tgz hadoopimages:/
docker cp jdk-8u201-linux-x64.tar.gz hadoopimages:/
#进入容器
docker exec -it hadoopimages /bin/bash
然后将jdk和scala上传到docker
配置JAVA环境变量

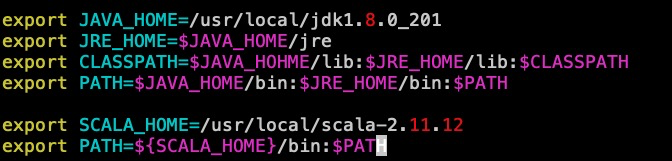
小问题:这里可能会有退出容器后环境变量失效的问题,可以将环境变量配置在~/.bashrc文件或者使用DockerFile方式
yum install net-tools
yum install openssh-server
yum -y install openssh-clients
#提交容器为镜像
#docker commit 容器名字或者id 自己要定义的镜像名
docker commit hadoopimages hadoop
#查看一下镜像
docker images

创建网络bigdata,供各种大数据应用共同一个网络
这里指定的是172.25.0.0/16子网,注意不要和自己的其他子网相冲突,以免一些不必要的麻烦
docker network create --driver bridge --subnet 172.25.0.0/16 --gateway 172.25.0.1 bigdata
Zookeeper搭建
拉取zookeeper镜像
#选取自己合适的镜像即可
docker pull zookeeper:3.4.13
使用docker-compose创建三个zookeeper容器
version: '2'
services:
zoo1:
image: zookeeper:3.4.13 # 镜像名称
restart: always # 当发生错误时自动重启
hostname: zoo1
container_name: zoo1
privileged: true
ports: # 端口
- 2181:2181
volumes: # 挂载数据卷
- ./zoo1/data:/data
- ./zoo1/datalog:/datalog
environment:
TZ: Asia/Shanghai
ZOO_MY_ID: 1 # 节点ID
ZOO_PORT: 2181 # zookeeper端口号
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 # zookeeper节点列表
networks:
default:
ipv4_address: 172.25.0.11
zoo2:
image: zookeeper:3.4.13
restart: always
hostname: zoo2
container_name: zoo2
privileged: true
ports:
- 2182:2181
volumes:
- ./zoo2/data:/data
- ./zoo2/datalog:/datalog
environment:
TZ: Asia/Shanghai
ZOO_MY_ID: 2
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
networks:
default:
ipv4_address: 172.25.0.12
zoo3:
image: zookeeper:3.4.13
restart: always
hostname: zoo3
container_name: zoo3
privileged: true
ports:
- 2183:2181
volumes:
- ./zoo3/data:/data
- ./zoo3/datalog:/datalog
environment:
TZ: Asia/Shanghai
ZOO_MY_ID: 3
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
networks:
default:
ipv4_address: 172.25.0.13
networks:
default:
external:
name: bigdata
#运行命令
docker-compose up -d
➜ zookeeper docker-compose up -d
Recreating 44dad6cddccd_zoo1 ... done
Recreating 9b0f2cfe666f_zoo3 ... done
Creating zoo2 ... done


Kafka集群搭建
#拉取Kafka镜像和kafka-manager镜像
docker pull wurstmeister/kafka:2.12-2.3.1
docker pull sheepkiller/kafka-manager
编辑docker-compose.yml文件
version: '2'
services:
broker1:
image: wurstmeister/kafka:2.12-2.3.1
restart: always # 出现错误时自动重启
hostname: broker1# 节点主机
container_name: broker1 # 节点名称
privileged: true # 可以在容器里面使用一些权限
ports:
- "9091:9092" # 将容器的9092端口映射到宿主机的9091端口上
environment:
KAFKA_BROKER_ID: 1
KAFKA_LISTENERS: PLAINTEXT://broker1:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:9092
KAFKA_ADVERTISED_HOST_NAME: broker1
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181/kafka1,zoo2:2181/kafka1,zoo3:2181/kafka1
JMX_PORT: 9988 # 负责kafkaManager的端口JMX通信
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./broker1:/kafka/kafka\-logs\-broker1
external_links:
- zoo1
- zoo2
- zoo3
networks:
default:
ipv4_address: 172.25.0.14
broker2:
image: wurstmeister/kafka:2.12-2.3.1
restart: always
hostname: broker2
container_name: broker2
privileged: true
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 2
KAFKA_LISTENERS: PLAINTEXT://broker2:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker2:9092
KAFKA_ADVERTISED_HOST_NAME: broker2
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181/kafka1,zoo2:2181/kafka1,zoo3:2181/kafka1
JMX_PORT: 9988
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./broker2:/kafka/kafka\-logs\-broker2
external_links: # 连接本compose文件以外的container
- zoo1
- zoo2
- zoo3
networks:
default:
ipv4_address: 172.25.0.15
broker3:
image: wurstmeister/kafka:2.12-2.3.1
restart: always
hostname: broker3
container_name: broker3
privileged: true
ports:
- "9093:9092"
environment:
KAFKA_BROKER_ID: 3
KAFKA_LISTENERS: PLAINTEXT://broker3:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker3:9092
KAFKA_ADVERTISED_HOST_NAME: broker3
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181/kafka1,zoo2:2181/kafka1,zoo3:2181/kafka1
JMX_PORT: 9988
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./broker3:/kafka/kafka\-logs\-broker3
external_links: # 连接本compose文件以外的container
- zoo1
- zoo2
- zoo3
networks:
default:
ipv4_address: 172.25.0.16
kafka-manager:
image: sheepkiller/kafka-manager:latest
restart: always
container_name: kafka-manager
hostname: kafka-manager
ports:
- "9000:9000"
links: # 连接本compose文件创建的container
- broker1
- broker2
- broker3
external_links: # 连接本compose文件以外的container
- zoo1
- zoo2
- zoo3
environment:
ZK_HOSTS: zoo1:2181/kafka1,zoo2:2181/kafka1,zoo3:2181/kafka1
KAFKA_BROKERS: broker1:9092,broker2:9092,broker3:9092
APPLICATION_SECRET: letmein
KM_ARGS: -Djava.net.preferIPv4Stack=true
networks:
default:
ipv4_address: 172.25.0.10
networks:
default:
external: # 使用已创建的网络
name: bigdata
#运行命令
docker-compose up -d
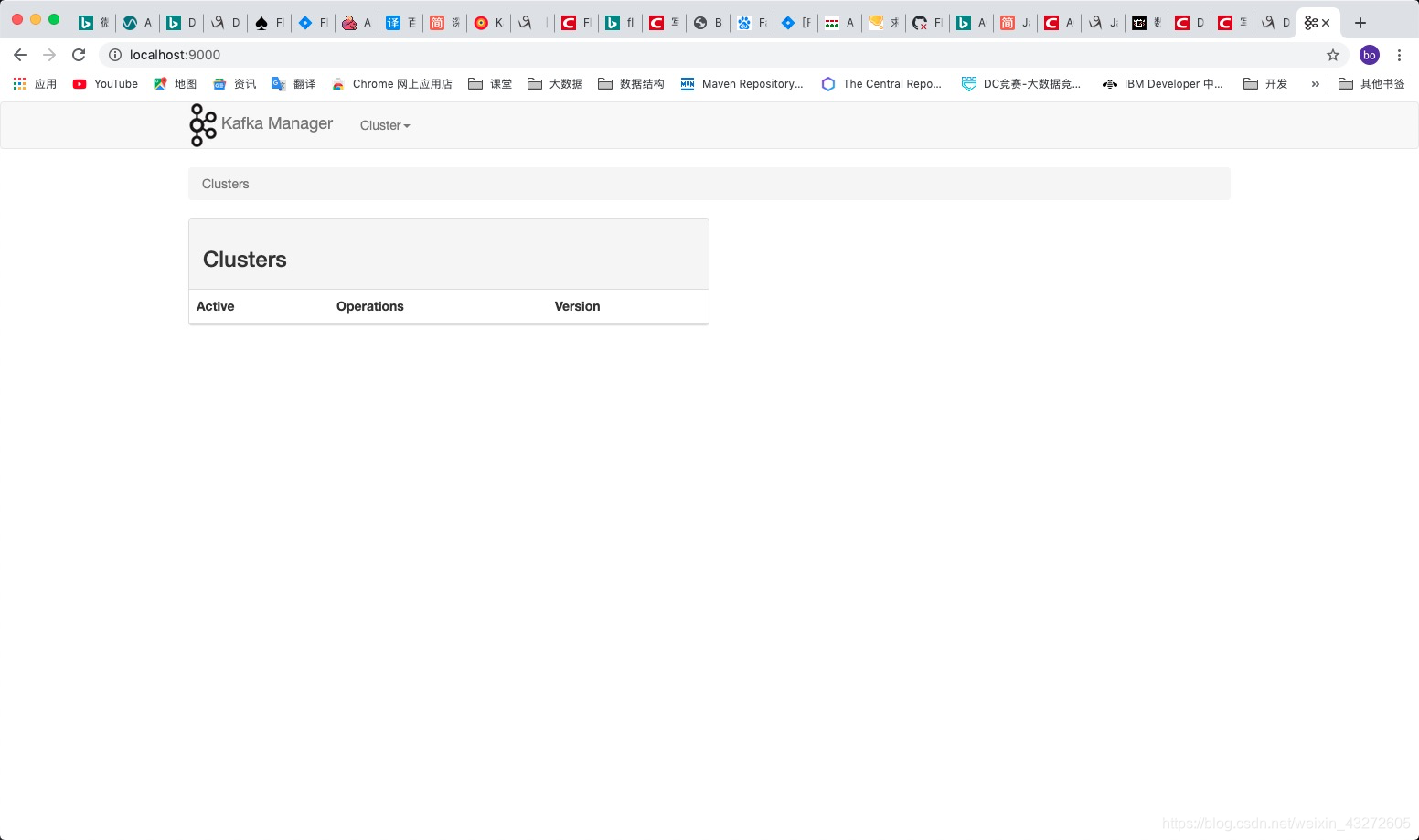
**看看本地端口9000也确实起来了
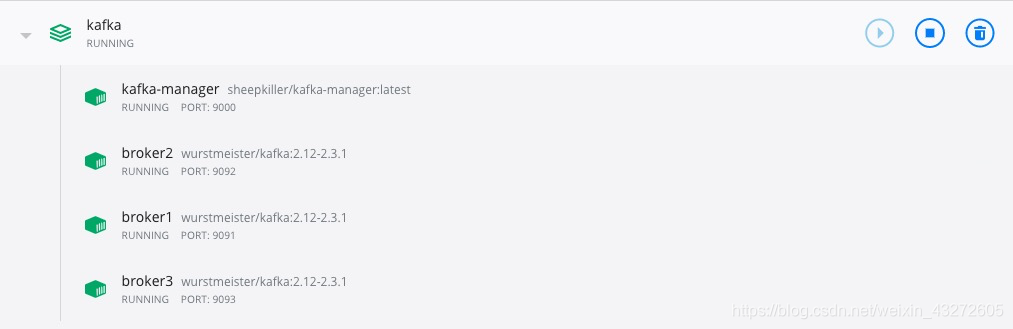
Hadoop高可用集群搭建
docker-compose创建集群
version: '2'
services:
master:
image: hadoop:latest
restart: always # 出现错误时自动重启
hostname: master# 节点主机
container_name: master # 节点名称
privileged: true # 可以在容器里面使用一些权限
networks:
default:
ipv4_address: 172.25.0.3
master_standby:
image: hadoop:latest
restart: always
hostname: master_standby
container_name: master_standby
privileged: true
networks:
default:
ipv4_address: 172.25.0.4
slave01:
image: hadoop:latest
restart: always
hostname: slave01
container_name: slave01
privileged: true
networks:
default:
ipv4_address: 172.25.0.5
slave02:
image: hadoop:latest
restart: always
container_name: slave02
hostname: slave02
networks:
default:
ipv4_address: 172.25.0.6
slave03:
image: hadoop:latest
restart: always
container_name: slave03
hostname: slave03
networks:
default:
ipv4_address: 172.25.0.7
命令行方式创建
#创建一个master节点
docker run -tid --name master --privileged=true hadoop:latest /usr/sbin/init
#创建热备master_standby节点
docker run -tid --name master_standby --privileged=true hadoop:latest /usr/sbin/init
#创建三个slave
docker run -tid --name slave01 --privileged=true hadoop:latest /usr/sbin/init
docker run -tid --name slave02 --privileged=true hadoop:latest /usr/sbin/init
docker run -tid --name slave03 --privileged=true hadoop:latest /usr/sbin/init
给每台节点配置免密码登陆
ssh-keygen -t rsa
#然后不断会车,最终如下图所示
#每台机器都是如此
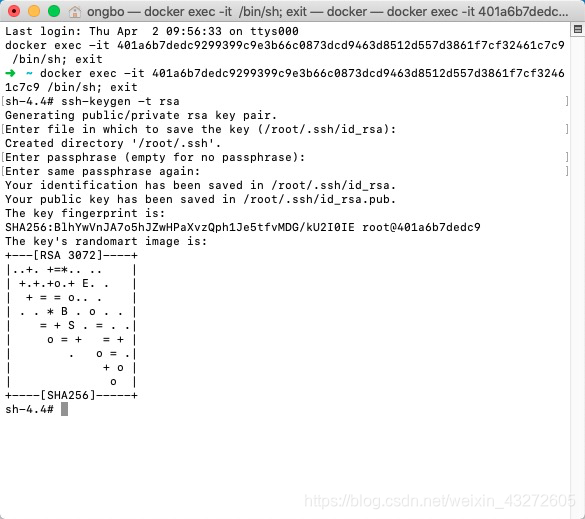
将各自的公钥传到每台机器authorized_keys里面
这里有个小问题:先检查安装了passwd没有,如果没有执行以下命令:
yum install passwd
#然后设置密码
passwd

#一台机器的公钥都要弄到自己和其他机器的authorized_keys
#以免以后安装其他东西减少不必要的麻烦
cat id_rsa.pub >> .ssh/authorized_keys
编辑/etc/hosts
注意:这里的master_standby可能不允许带下划线,有的机器在hdfs格式化的时候会不合法,所以你配置最后不要带特殊字符
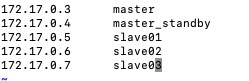
#将/etc/hosts复制到每台节点
scp /etc/hosts master_standby:/etc/
scp /etc/hosts slave01:/etc/
scp /etc/hosts slave02:/etc/
scp /etc/hosts slave03:/etc/
配置Hadoop
#解压hadoop包
tar -zxvf hadoop-2.8.5.tar.gz
配置环境变量
#配置环境变量
vim ~/.bashrc
#添加以下内容
export HADOOP_HOME=/usr/local/hadoop-2.8.5
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#将这个文件拷到其他机器的下面
scp ~/.bashrc 机器名字:~/
#hadoop命令验证一下
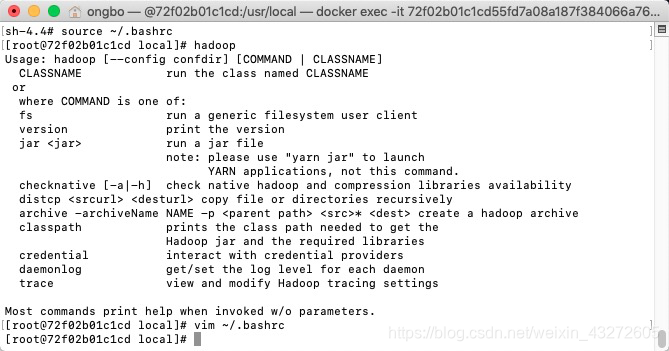
配置文件
hdfs-site.xml
<configuration>
<!-- same with core-site.xml:defaultFS-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- two NameNode,nn1 and nn2-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- mycluster.nn1 Namenode's RPC Address-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
</property>
<!-- mycluster.nn1 Namenode's Http Address-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:50070</value>
</property>
<!-- mycluster.nn2 Namenode's RPC Address-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>master_standby:9000</value>
</property>
<!-- mycluster.nn2 Namenode's Http Address-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>master_standby:50070</value>
</property>
<!-- where the NameNode's metadata store in JournalNodes -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave01:8485;slave02:8485;slave03:8485/mycluster</value>
</property>
<!-- where Journaldata store in its disk-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.8.5/journaldata</value>
</property>
<!-- open automatic-failover when fail-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- the way when fail -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- set the methods which disdancy-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.8.5/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zoo1:2181,zoo2:2181,zoo3:2181</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- open the yarn HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- RM's cluster id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<!-- Rm's name-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- RM1's address-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<!-- RM2's address-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master_standby</value>
</property>
<!-- zookeeper cluster address-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zoo1:2181,zoo2:2181,zoo3:2181</value>
</property>
<!-- mapreduce-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- open RM restart-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8001</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master_standby:8001</value>
</property>
<!-- RM1 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:8033</value>
</property>
<!-- RM2 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>master_standby:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>master_standby:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>master_standby:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>master_standby:8033</value>
</property>
<!-- YARN ?~[~F群?~Z~D?~A~Z?~P~H?~W??~W?~\~@?~U??~]?~U~Y?~W??~U? -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<!--1天-->
<value>86400</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
slaves
slave01
slave02
slave03
~
将配置文件分发到其他的每个节点
启动
#在三台slave上执行
sbin/hadoop-daemon.sh start journalnode
#在master执行hdfs格式化
bin/hdfs namenode -format
#在masterstandby上执行来同步元数据
#或者直接拷贝过去scp -r /usr/local/hadoop-2.8.5/tmp masterstandby:/usr/local/hadoop-2.8.5
hdfs namenode -bootstrapStandby
#格式化zk
bin/hdfs zkfc -formatZK
#之后启动hdfs
sbin/start-hdfs.sh
#启动yarn
sbin/start-yarn.sh
master进程
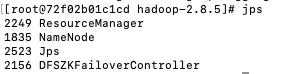
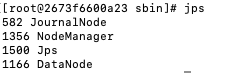
masterstandby进程

slave进程


















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











