




 本文详细解析Hadoop中的NameNode和SecondaryNameNode的工作机制,以及FSImage和edits文件在元数据管理中的作用。NameNode负责元数据管理,元数据存储于内存并持久化到FSImage和edits。SecondaryNameNode执行定期检查点合并FSImage和edits,确保元数据安全。同时,文章探讨了元数据信息的查看方法和多目录配置以增强可靠性。
本文详细解析Hadoop中的NameNode和SecondaryNameNode的工作机制,以及FSImage和edits文件在元数据管理中的作用。NameNode负责元数据管理,元数据存储于内存并持久化到FSImage和edits。SecondaryNameNode执行定期检查点合并FSImage和edits,确保元数据安全。同时,文章探讨了元数据信息的查看方法和多目录配置以增强可靠性。
目录
一、NameNode与SecondaryNameNode解析
一、NameNode与SecondaryNameNode解析
-
NameNode主要负责集群当中的元数据信息管理,而且元数据信息需要经常随机访问,因为元数据信息必须高效的检索,那么如何保证namenode快速检索呢??元数据信息保存在哪里能够快速检索呢??如何保证元数据的持久安全呢??
-
为了保证元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中元数据信息能够最快速的检索,那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。
-
如果所有的元数据信息都存放内存,服务器断电,内存当中所有数据都消失,为了保证元数据的安全持久,元数据信息必须做可靠的持久化,在hadoop当中为了持久化存储元数据信息,将所有的元数据信息保存在了FSImage文件当中,那么FSImage随着时间推移,必然越来越膨胀,FSImage的操作变得越来越难,为了解决元数据信息的增删改,hadoop当中还引入了元数据操作日志edits文件,edits文件记录了客户端操作元数据的信息,随着时间的推移,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNamenode来专门做fsimage与edits文件的合并
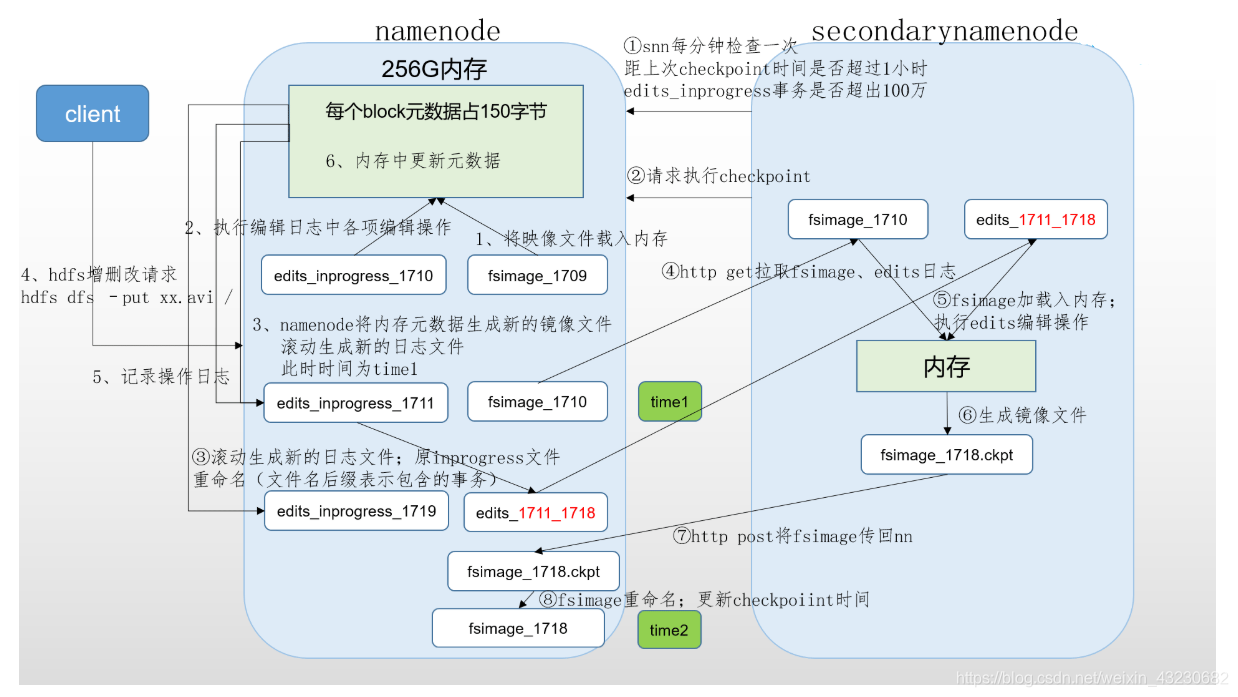
1、NameNode工作机制
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









