




 本文深入探讨了Attention机制,包括在encoder-decoder结构中的应用,以及硬注意力与软注意力的区别。特别强调了自注意力机制的重要性和工作原理,如在Transformer模型中的多头自注意力机制。此外,还介绍了位置编码在模型中如何弥补序列信息的缺失。
本文深入探讨了Attention机制,包括在encoder-decoder结构中的应用,以及硬注意力与软注意力的区别。特别强调了自注意力机制的重要性和工作原理,如在Transformer模型中的多头自注意力机制。此外,还介绍了位置编码在模型中如何弥补序列信息的缺失。
Attention机制学习笔记
在这里主要介绍三种attention机制:hard attention、soft attention和self attention。
一、注意力机制
注意力机制(attention mechanism)是机器学习中的一种处理数据的方法,广泛应用于多种单模态、多模态任务中,比如:计算机视觉领域中的目标检测,图像分割等任务,自然语言处理领域中的机器翻译,语义标注等任务,多模态领域中的image captioning、visual question answering等…
在实际生活中,注意力机制和人类的视觉注意力十分相似,在看到一张图片或是一篇文章时,会有选择性的关注场景中最为显眼或者比较重要的部分,也就是说人们对一个场景中的每一个部分给予的注意力是不同的,机器学习中的注意力机制也可以这样解释。
那么attention机制的基本模型是如何进行工作的呢?
实际上attention机智的本质思想是将输入看作是一个<key,value>对,给定一个与任务相关的查询query向量,通过计算q和输入中的k之间的注意力分布并和v进行加权求和,从而得到weighted value,即附加了注意力的一系列value。这个过程极大的降低了模型计算复杂度,只需要从所有输入中选择部分和任务输出相关的部分输入送入模型即可,而不再是需要将全部输入都送进模型进行计算。整个过程可由下图表示
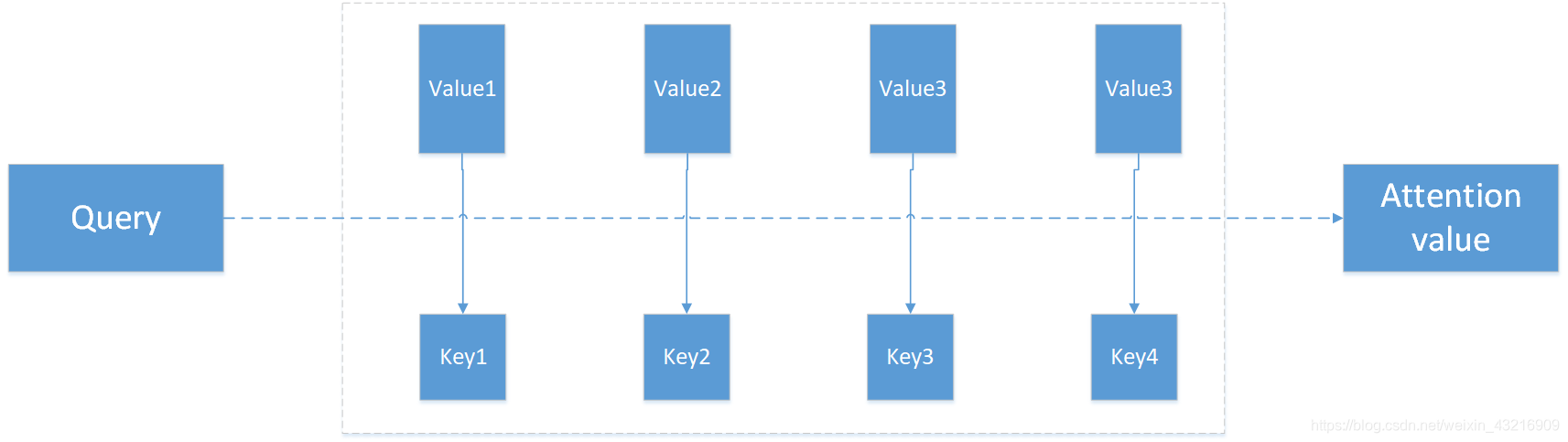
整个attention的过程可大致分为三个步骤:
- 信息输入
- 权重注意力分布计算
- 信息加权和/加权平均计算
第一步:定义输入序列X=[x1,x2,…,xn]
第二步:根据上述对attention机制的描述,我们令key=value=X,计算query和key之间的相似度,经过softmax归一化得到每一个key对应value的权重
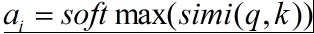
第三步:求出每部分的权值后,对value进行加权和/加权平均得到最终附加了注意力分布的值
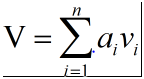
下面我们会以encoder-decoder结构为载体对几种注意力机制进行讨论
二、encoder-decoder结构
encoder-decoder框架是一个端到端的学习模型,简单来说就是使用encoder对模型的输入进行编码,得到想要得到的信息作为encoder的输出,之后将encoder的输入传入decoder端进行解码,得到最终结果,下图为一般的encoder-decode
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9270
9270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









