







常用的模型评估方法总结
混淆矩阵(常用于二分类问题的模型评估)
P代表预测结果为正,N代表预测结果为负
T代表实际与预测相同,F代表实际与预测不同

准确率
ACC(A)=TP+TN / TP+FP+FN+TN 在所有预测结果中,预测对了的占比
精确度
PPV§ =TP/(TP+FP) 在预测为 1 的所有结果中,预测对了的占比
灵敏度
TPR®=TP/(TP+FN) 在真实为1 的所有结果中,预测对了的占比
FPR(F)=FP/(FP+TN) 在真实为 0 的所有结果中,预测为1的占比
特异度
TNR(S)=TN/(FP+TN) 在真实为 0 的所有结果中,预测对了的占比
ROC曲线
ROC的概念
ROC全称是Receiver Operating Characteristic,也叫“受试者工作特征曲线”,它的横坐标是假阳性率false positive rate(FPR),纵坐标是真阳性率true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。
为什么要使用ROC
评价标准很多,之所以还要使用ROC和AUC,是因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线的对比:
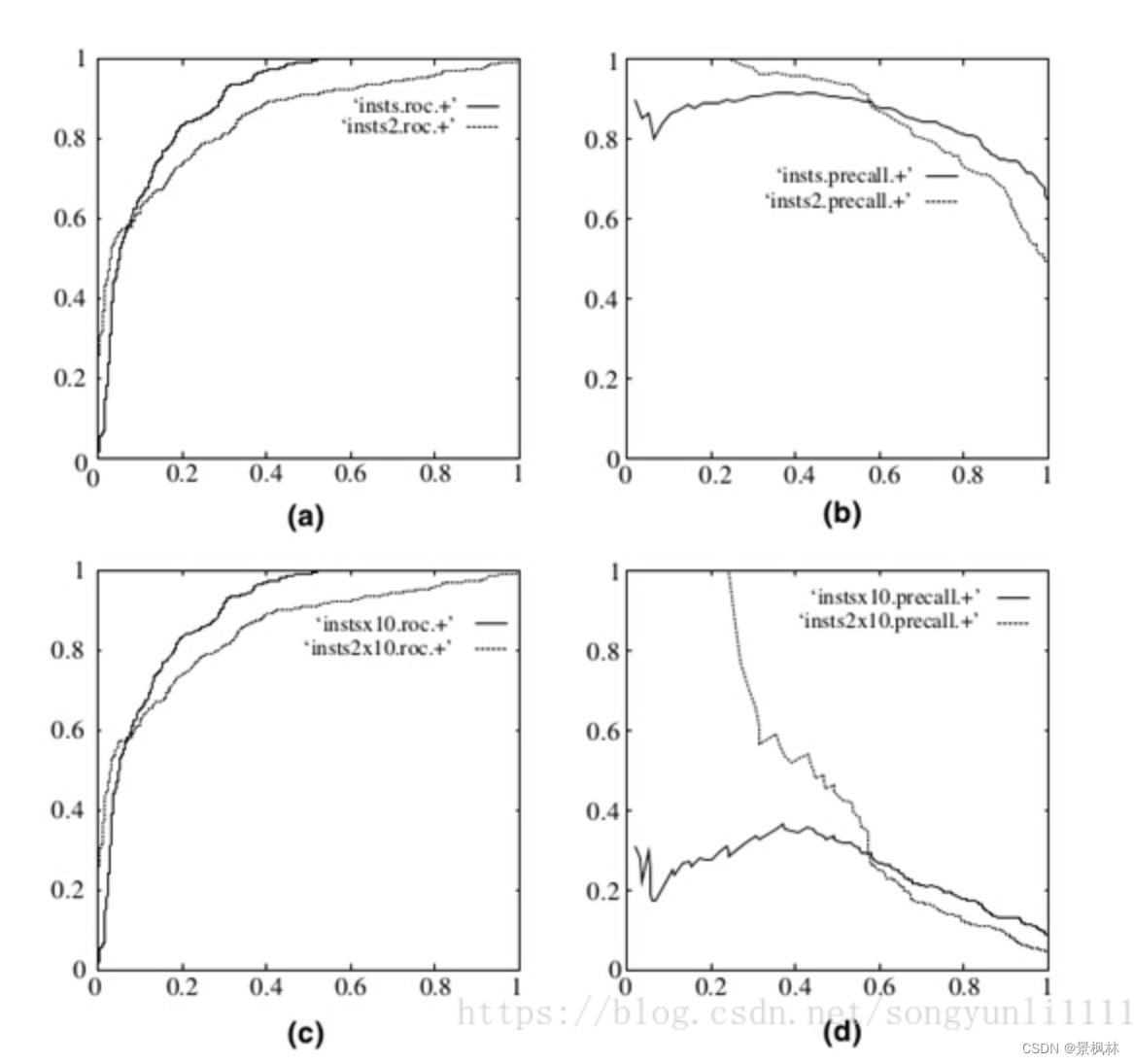
a图是原数据ROC曲线,b图是原数据P-R曲线。cd分别对应负样本增大10倍后的两个曲线图。可以看出,ROC曲线基本没有变化,但P-R曲线确剧烈震荡。因此,在面对正负样本数量不均衡的场景下,ROC曲线(AUC的值)会是一个更加稳定能反映模型好坏的指标。
AUC作为评价标准
AUC定义为ROC曲线下的面积,取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,AUC更大的分类器效果更好。
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
· 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
· AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
· AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC值越大,模型的分类效果越好,疾病检测越准确;不过两个模型AUC值相等并不代表模型效果相同。
下面两幅图中两条ROC曲线相交于一点,AUC值几乎一样:当需要高Sensitivity时,模型A比B好;当需要低Speciticity时,模型B比A好

ROC曲线如何绘制

第一步按照属于‘正样本’的概率将所有样本排序,如上图所示
第二步如果将样本1的score值做阈值,则只有score大于等于0.9时,才把样本归类到真阳性(true positive),那么对应的混淆矩阵(confusion matrix)如下图所示

其中,只有样本1我们看作是正确分类了(也就是我们预测是正样本,实际也是正样本);其余还有9个实际是正样本,而我们预测是负样本的(2,4,5,6,9,11,13,17,19);剩下的实际是负样本,我们都预测出是负样本了(也就是false positive = 0, true negative = 10)。
从混淆矩阵中,我们可以算出X轴坐标(false positive rate)= 0/(0+10)= 0 和Y轴坐标(true positive rate)= 1/(1+9)= 0.1,这就是下图中的第一个点

第三步,调整score的阈值,则混淆矩阵会相应的变化,落到ROC曲线上则对应不同的点,不断调整阈值,最终画出整个曲线。
参考:
https://blog.youkuaiyun.com/IT_flying625/article/details/103246932
https://www.zhihu.com/question/22844912/answer/246037337
https://www.jianshu.com/p/2ca96fce7e81


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









