







disruptor和kafka区别
disruptor,内存队列,使用场景一般在系统内部,提高在高并发的情况下系统的性能,一般作用于线程间的消息传递
kafka,分布式消息队列,使用场景一般在系统和系统间的消息传递,吞吐量高,也适用于消息流数据处理的中间件
队列
队列有两种实现思路。一种是基于链表实现的链式队列,另一种是基于数组实现的顺序队列。不同的需求背景下,我们会选择不同的实现方式。
无界队列,指的是队列的大小事先不确定,这种情况下,我们适合选用链表来实现队列。因为链表支持快速地动态扩容。
有界队列,指的是队列的大小事先确定,当队列中数据满了之后,生产者就需要等待。直到消费者消费了数据,队列有空闲位置的时候,生产者才能将数据放入。由于非循环的顺序队列在添加、删除数据的工程中,会涉及数据的搬移操作,导致性能变差。而循环队列正好可以解决这个数据搬移的问题,所以,大部分用到顺序队列的场景中,都选择用顺序队列中的循环队列。
循环队列这种数据结构,也是内存消息队列的雏形。
常见的内存队列往往采用循环队列来实现。这种实现方法,对于只有一个生产者和一个消费者的场景,已经足够了。但是,当存在多个生产者或者多个消费者的时候,单纯的循环队列的实现方式,就无法正确工作了。
这主要是因为,多个生产者在同时往队列中写入数据的时候,在某些情况下,会存在数据覆盖的问题。而多个消费者同时消费数据,在某些情况下,会存在消费重复数据的问题。
针对这个问题,最简单、暴力的解决方法就是,对写入和读取过程加锁。这种处理方法,相当于将原来可以并行执行的操作,强制串行执行,相应地就会导致操作性能的下降。
disruptor
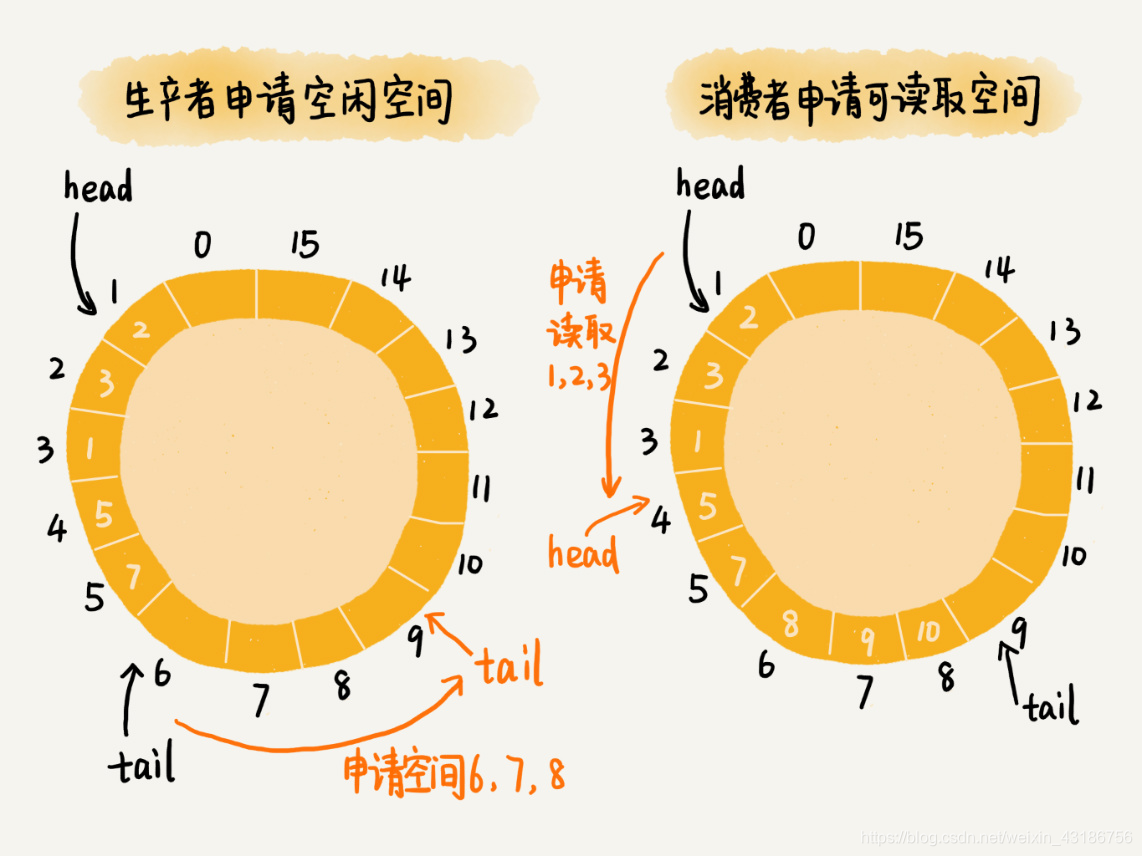
为了在保证逻辑正确的前提下,尽可能地提高队列在并发情况下的性能,Disruptor 采用了“两阶段写入”的方法。在写入数据之前,先加锁申请批量的空闲存储单元,之后往队列中写入数据的操作就不需要加锁了,写入的性能因此就提高了。Disruptor 对消费过程的改造,跟对生产过程的改造是类似的。它先加锁申请批量的可读取的存储单元,之后从队列中读取数据的操作也就不需要加锁了,读取的性能因此也就提高了。
基于无锁的并发“生产者 - 消费者模型”
对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的 n 个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,从刚刚的描述中,我们可以看出,申请存储单元的过程是需要加锁的。
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
不过,还有一个需要特别注意的地方,那就是,如果生产者 A 申请到了一组连续的存储单元,假设是下标为 3 到 6 的存储单元,生产者 B 紧跟着申请到了下标是 7 到 9 的存储单元,那在 3 到 6 没有完全写入数据之前,7 到 9 的数据是无法读取的。这个也是 Disruptor 实现思路的一个弊端。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









