



 本文介绍使用Python操作SQLite数据库的方法,包括创建数据库、保存数据及生成数据库等步骤,并提供了详细的代码示例。
本文介绍使用Python操作SQLite数据库的方法,包括创建数据库、保存数据及生成数据库等步骤,并提供了详细的代码示例。
第一步:新建数据库
def init_db(dbpath):
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
''' # 创建数据表
conn = sqlite3.connect(dbpath) #连接数据库,
cursor = conn.cursor() #创建一个游标
cursor.execute(sql) #执行sql
conn.commit() #提交sql
conn.close()
这里仅仅是新建的一个数据库,关于数据库的建立,如何连接SQlist在上一篇博客中已结发布了,这里就不在进行详解。关于基础的sql语句,这里都是比较简单的。
第二步:保存数据库
def saveData2DB(datalist, dbpath): #传入两个参数,一个是爬虫爬取的列表,一个是保存的地址
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)#join(data)将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串,这里用%s来格式化一个对象为字符
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
这里注意,在保存数据库的时候。每一个字段的名字不要编译错,因为我曾经写错,导致后续的代码出现大范围的报错,很麻烦。
第三步:保存数据,生成数据库
def main():
baseurl = "https://movie.douban.com/top250?start="
# 1.爬取网页
datalist = getData(baseurl)
# savepath = "豆瓣电影Top250.xls"
dbpath = "movie.db"
# 3.保存数据
# saveData(datalist,savepath)
saveData2DB(datalist, dbpath)
这里如果有不明白的可以去查看爬虫爬取网页呢一篇博文,这一片文章是承接了上一篇,后续会发布其他的关于网络爬虫,和爬取信息可视化。
这里会生成一个movie.db的数据库。如果想下载我会提供链接地址。
因为后续的项目需要用到该数据库的文件。
https://download.youkuaiyun.com/download/weixin_43165267/15726914
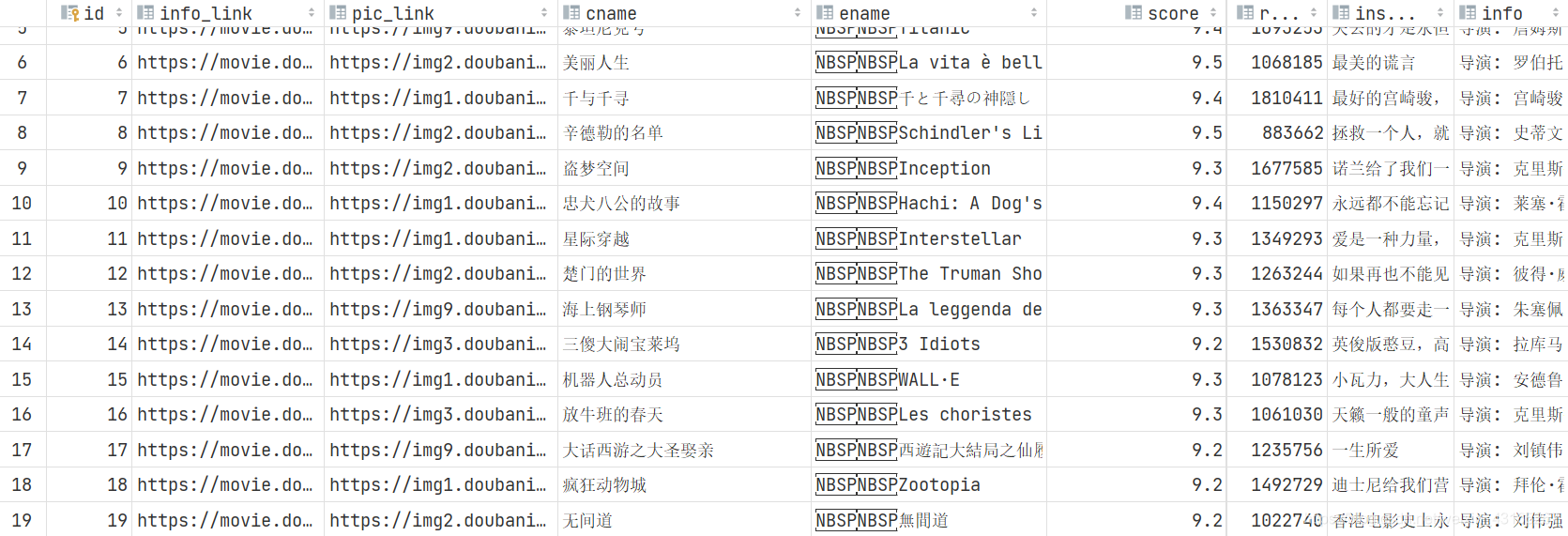
这里是部分数据



















 6225
6225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











