






 本文详细介绍了如何使用Python爬虫库Scrapy抓取我爱我家网站的房产信息,包括楼盘排名、名称、地址、面积和均价,并将数据存储到MySQL数据库。步骤涉及XPath解析、Item定义、数据库操作及Pipeline处理。
本文详细介绍了如何使用Python爬虫库Scrapy抓取我爱我家网站的房产信息,包括楼盘排名、名称、地址、面积和均价,并将数据存储到MySQL数据库。步骤涉及XPath解析、Item定义、数据库操作及Pipeline处理。
爬取链接:我爱我家
如果需要参考创建步骤,可以参考这篇文章
爬虫文件:loupan.py
import scrapy
from baiduSpider.items import BaiduspiderItem
class LoupanSpider(scrapy.Spider):
name = 'loupan'
allowed_domains = ['5i5j.com']
# start_urls = ['https://fang.5i5j.com/bj/loupan/n1/'] #爬取链接
start_urls=['https://fang.5i5j.com/bj/loupan/n%s/' % x for x in range(1,3)] #多页爬取
def parse(self, response):
item=BaiduspiderItem()
for row in response.xpath('/html/body/div[4]/div[1]/ul[1]/li'):
item['house_rank']=row.xpath('div[2]/div[1]/a/span[1]/text()').get() #楼盘排名
item['house_name']=row.xpath('div[2]/div[1]/a/span[2]/text()').get() #楼盘名
item['addr']=row.xpath('div[2]/div[3]/a/span[5]/text()').get().strip() #地址
item['size']=row.xpath('div[2]/div[2]/a/span[4]/text()').get() #大小
item['price']=row.xpath('div[3]/p/text()').get() #均价
yield item
items.py
import scrapy
class BaiduspiderItem(scrapy.Item):
house_rank=scrapy.Field()
house_name=scrapy.Field()
addr=scrapy.Field()
size=scrapy.Field()
price=scrapy.Field()
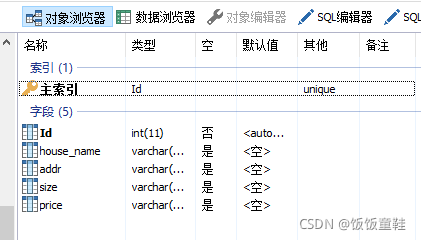
数据库里创建相应的表格和字段
USE test;
CREATE table loupan(
Id Int AUTO_INCREMENT PRIMARY key, #自增长主键
house_name varchar(255) CHARACTER set utf8,#楼盘名
addr varchar(255) CHARACTER set utf8, #楼盘地址
size varchar(255) CHARACTER set utf8, #大小
price varchar(255) CHARACTER set utf8 #价格
)
settings.py
MYSQL_DB_HOST = "127.0.0.1"
MYSQL_DB_PORT = 3306 # 端口
MYSQL_DB_NAME = "test"
MYSQL_DB_USER = "root"
MYSQL_DB_PASSWORD = "123456"
ITEM_PIPELINES = {
'baiduSpider.pipelines.MySQLPipeline': 2
}
pipelines.py
import pymysql
class BaiduspiderPipeline:
def process_item(self, item, spider):
return item
class MySQLPipeline():
# 开始爬取数据之前被调用
# 读取配置文件,初始化连接以及游标
def open_spider(self, spider):
host = spider.settings.get("MYSQL_DB_HOST", "127.0.0.1")
port = spider.settings.get("MYSQL_DB_PORT", 3306)
dbname = spider.settings.get("MYSQL_DB_NAME", "test")
user = spider.settings.get("MYSQL_DB_USER", "root")
pwd = spider.settings.get("MYSQL_DB_PASSWORD", "123456")
self.db_conn = pymysql.connect(host=host, port=port,
db=dbname, user=user, password=pwd)
self.db_cur = self.db_conn.cursor()
# 每解析完一个 item 调用
# 插入数据
def process_item(self, item, spider):
values = (
item['house_name'],
item['addr'],
item['size'],
item['price']
)
sql = "insert into loupan(house_name,addr,size,price) values(%s,%s,%s,%s)"
self.db_cur.execute(sql, values) #执行sql语句
return item
# 爬取完全部数据后被调用
# 提交数据,释放连接
def close_spider(self, spider):
self.db_conn.commit()
self.db_cur.close()
self.db_conn.close()
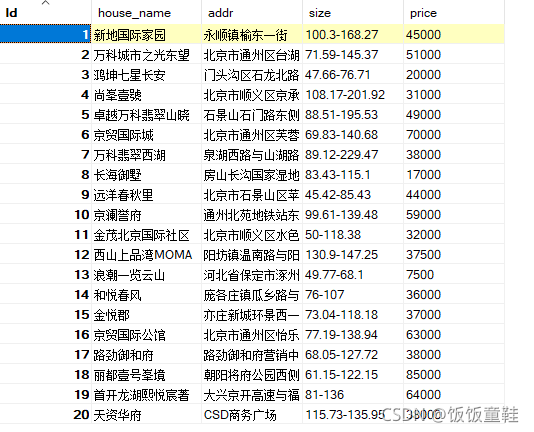
最后执行scrapy crawl loupan -o loupan.csv,数据库中存有了数据


















 2360
2360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









