







文章目录
from: https://www.youtube.com/watch?v=P6sfmUTpUmc&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=4
282,558次观看 2022年10月5日
We dive into some of the internals of MLPs with multiple layers and scrutinize the statistics of the forward pass activations, backward pass gradients, and some of the pitfalls when they are improperly scaled. We also look at the typical diagnostic tools and visualizations you’d want to use to understand the health of your deep network. We learn why training deep neural nets can be fragile and introduce the first modern innovation that made doing so much easier: Batch Normalization. Residual connections and the Adam optimizer remain notable todos for later video.
Chapters:
00:00:00 intro
00:01:22 starter code
00:04:19 fixing the initial loss
00:12:59 fixing the saturated tanh
00:27:53 calculating the init scale: “Kaiming init”
00:40:40 batch normalization
01:03:07 batch normalization: summary
01:04:50 real example: resnet50 walkthrough
01:14:10 summary of the lecture
01:18:35 just kidding: part2: PyTorch-ifying the code
01:26:51 viz #1: forward pass activations statistics
01:30:54 viz #2: backward pass gradient statistics
01:32:07 the fully linear case of no non-linearities
01:36:15 viz #3: parameter activation and gradient statistics
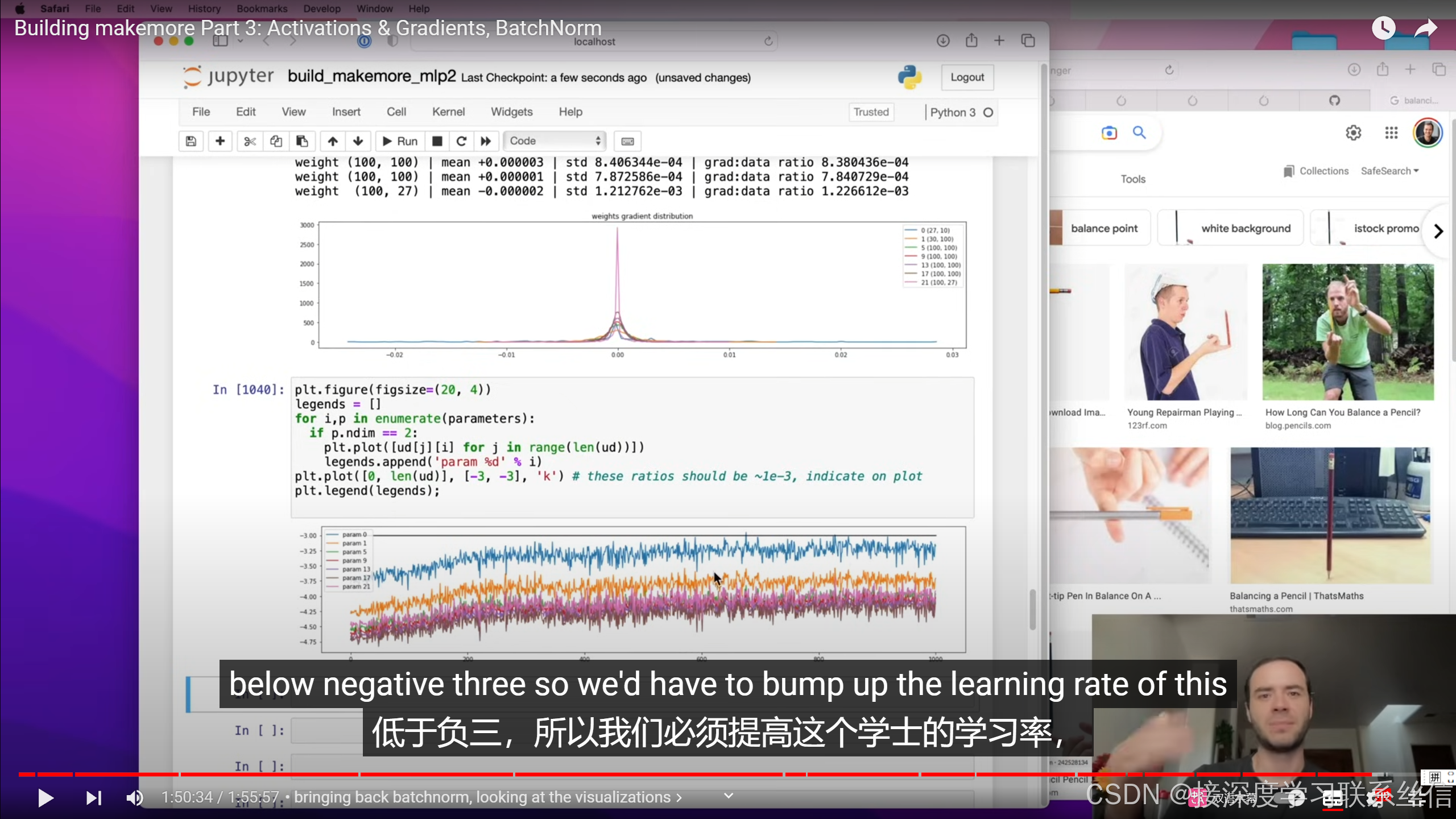
01:39:55 viz #4: update:data ratio over time
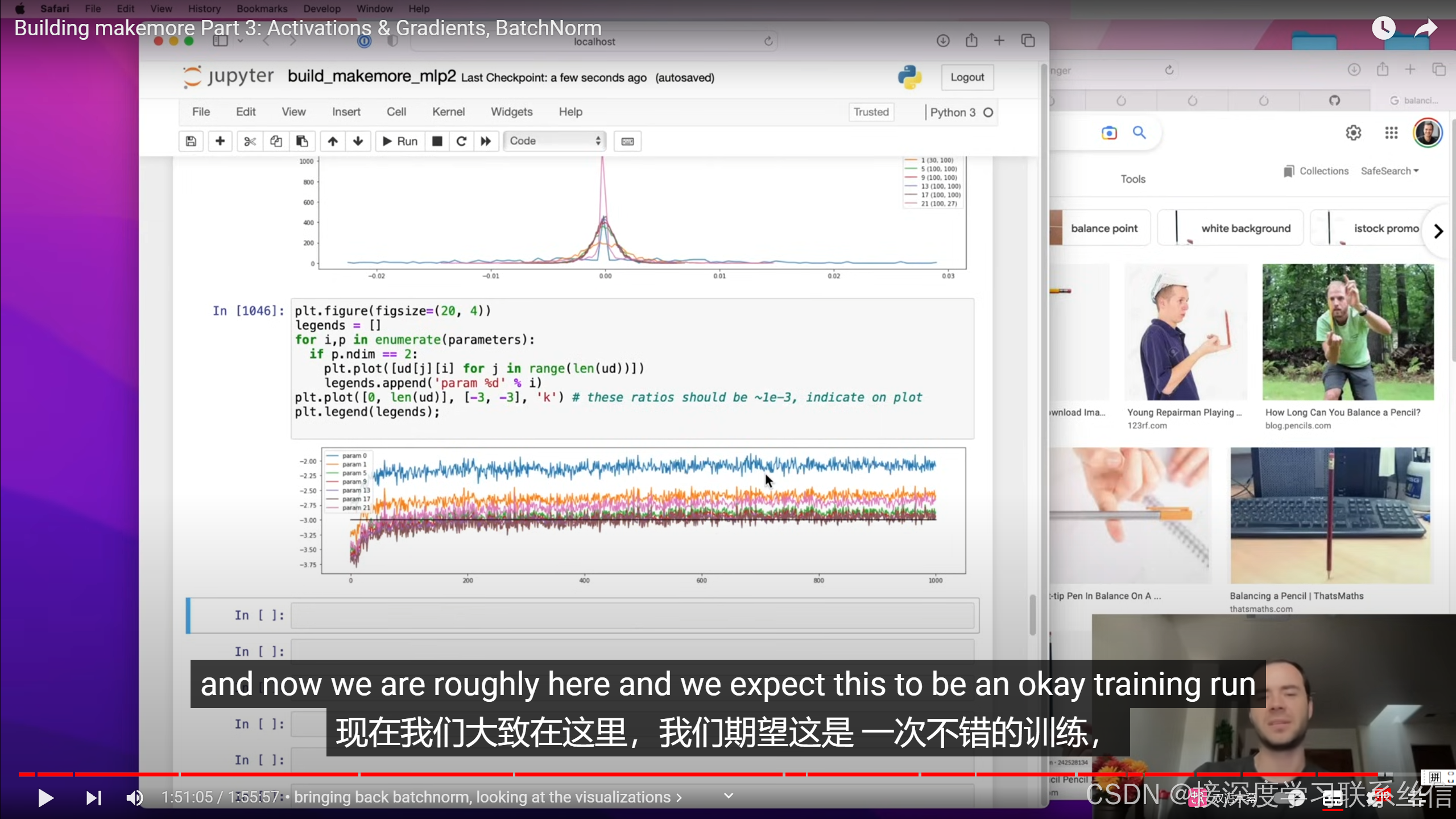
01:46:04 bringing back batchnorm, looking at the visualizations
01:51:34 summary of the lecture for real this time
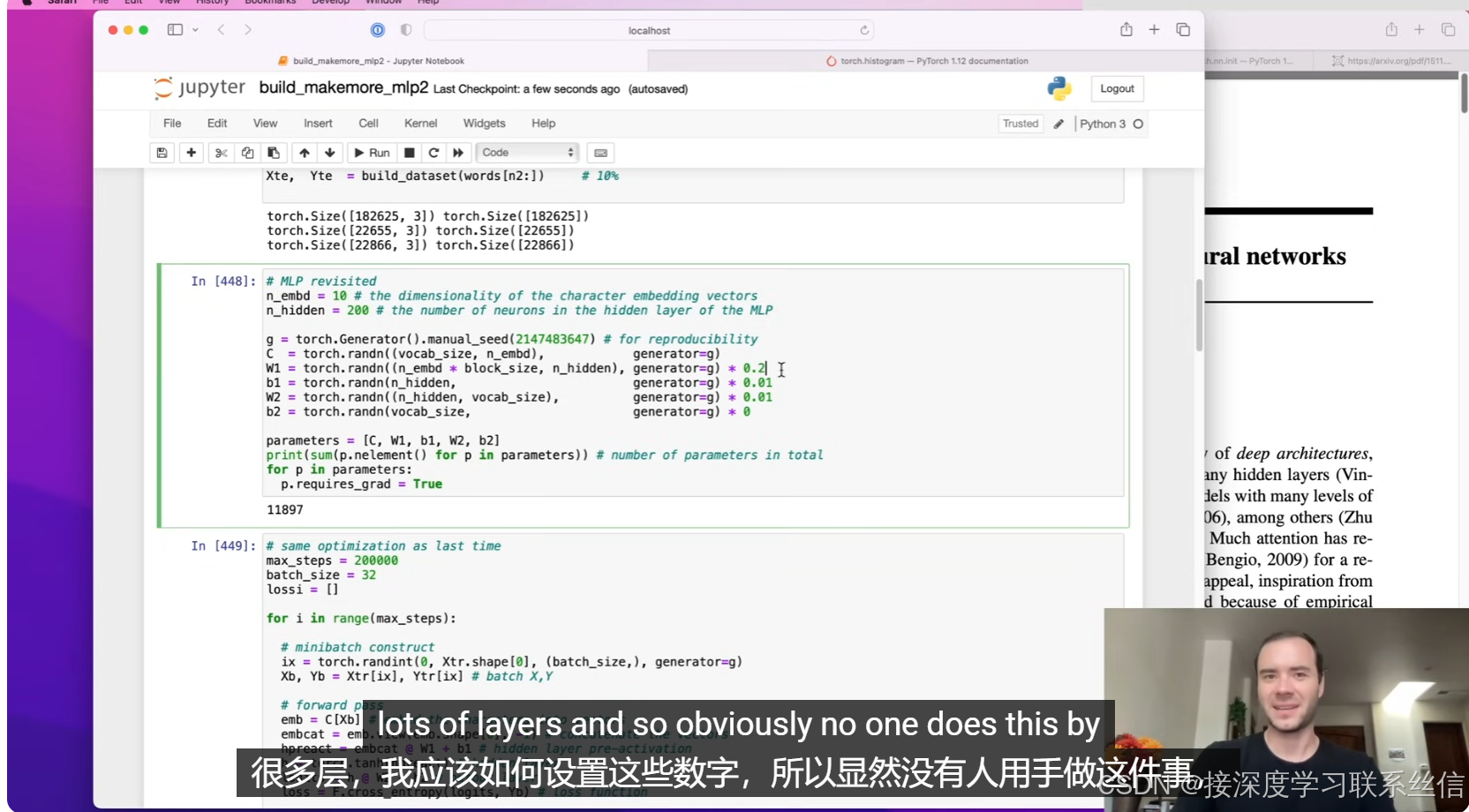
1.【参数初始化的重要性!】
对神经网络参数进行初始化,损失函数不再是曲棍球棒【参数初始化的重要性!】
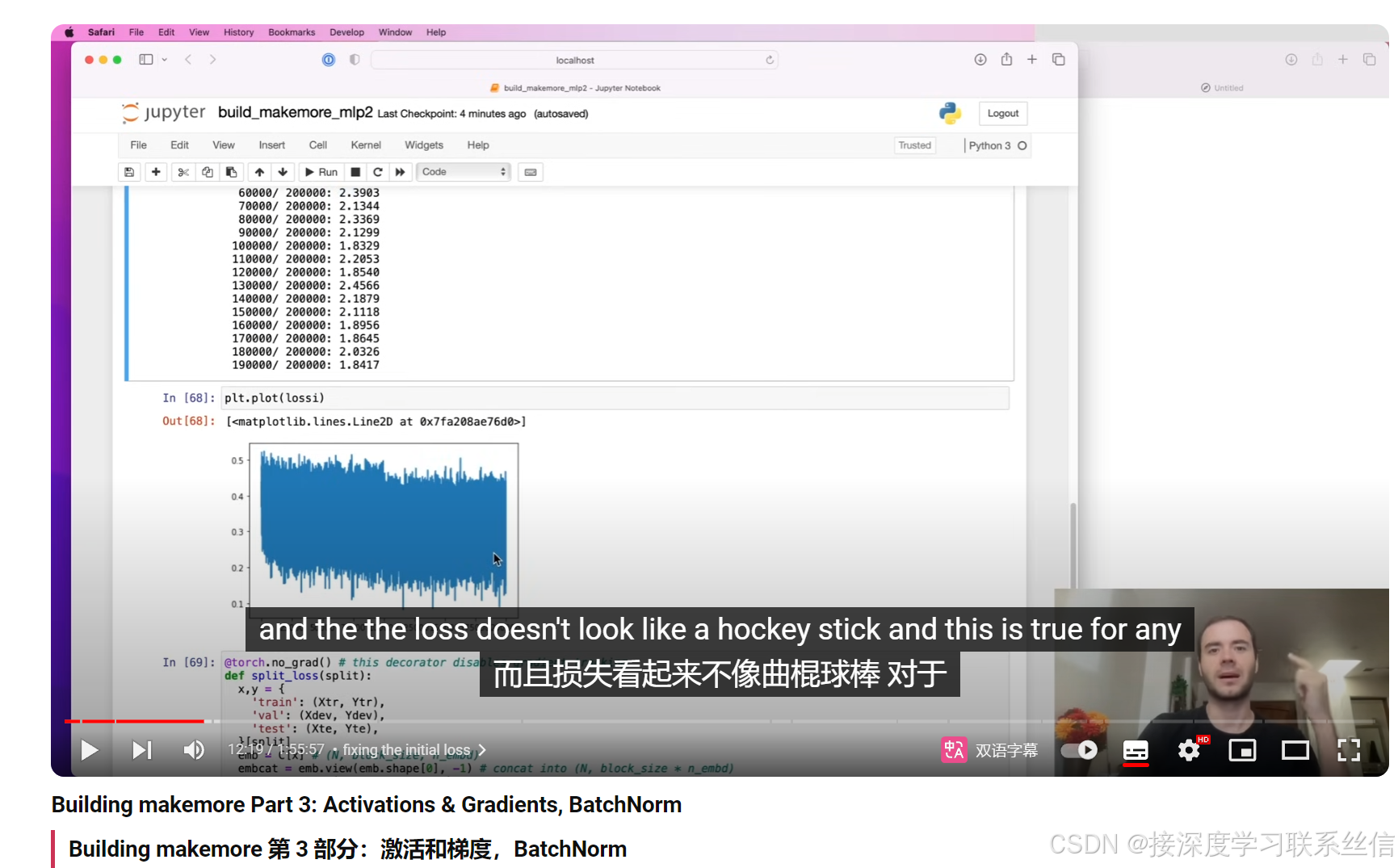

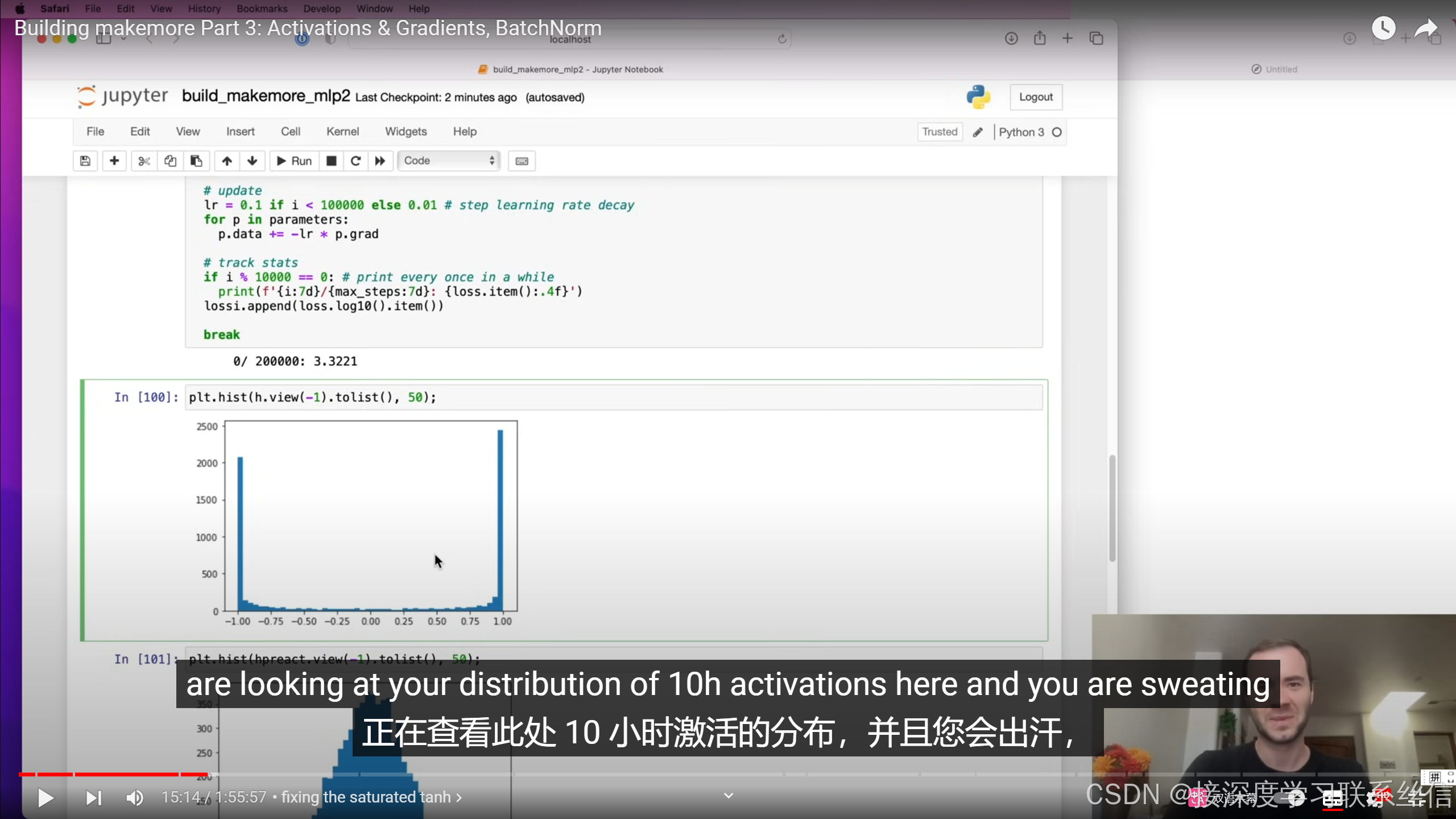
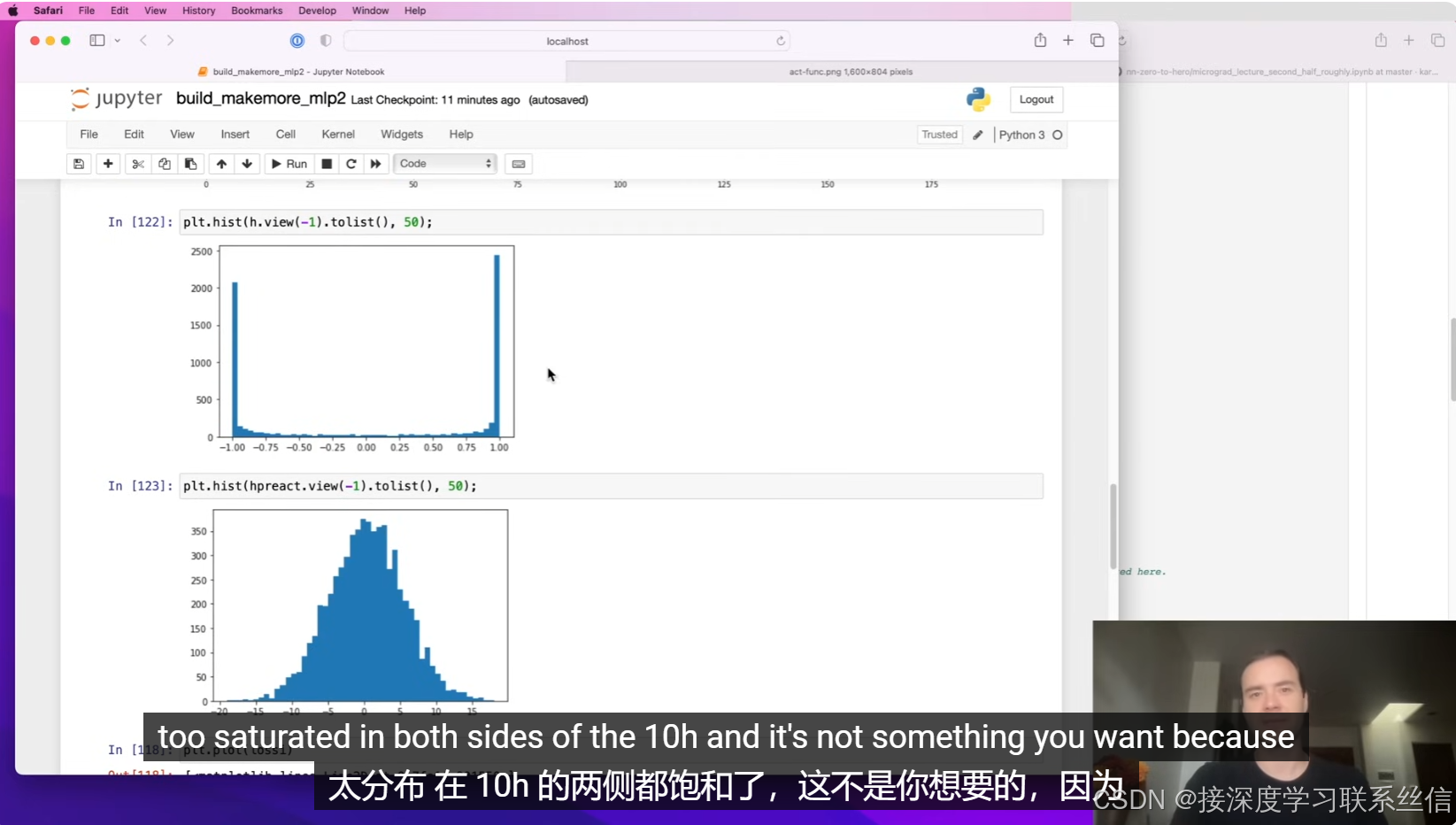
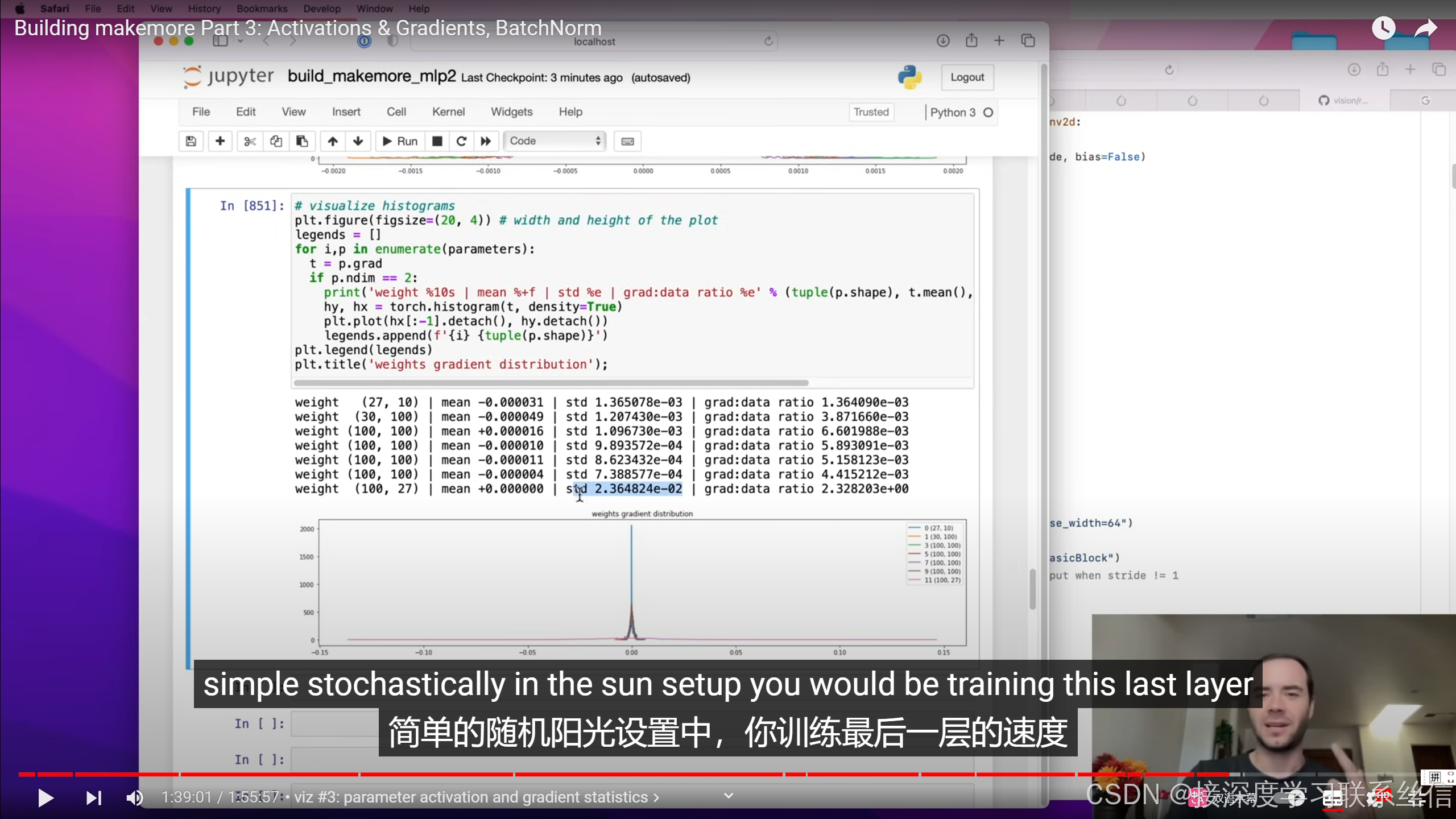
2. 【检查值的分布,神经元激活,死亡?检查梯度流动】
检查值的分布,梯度的感知!【神经元激活,死亡?】
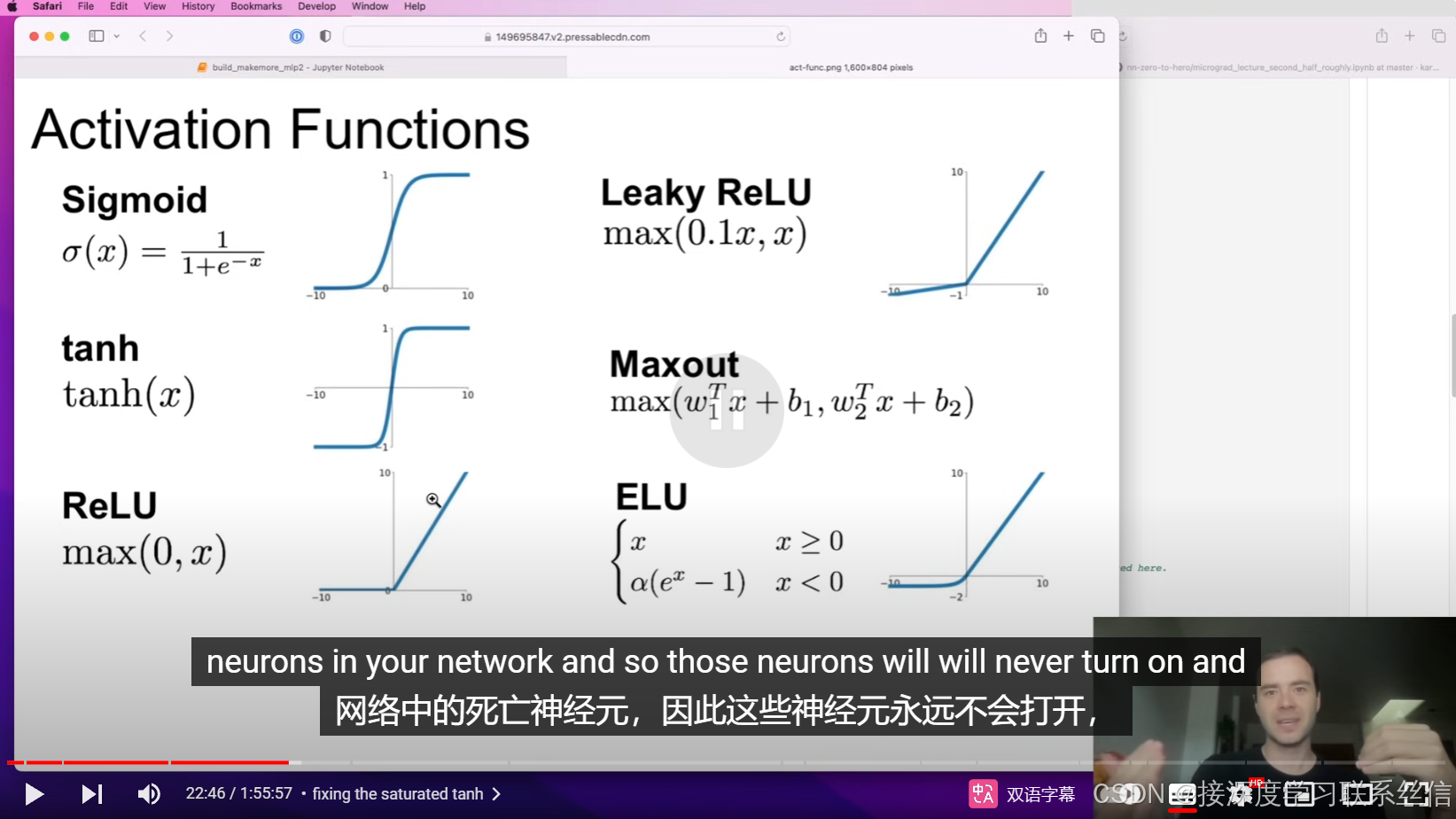
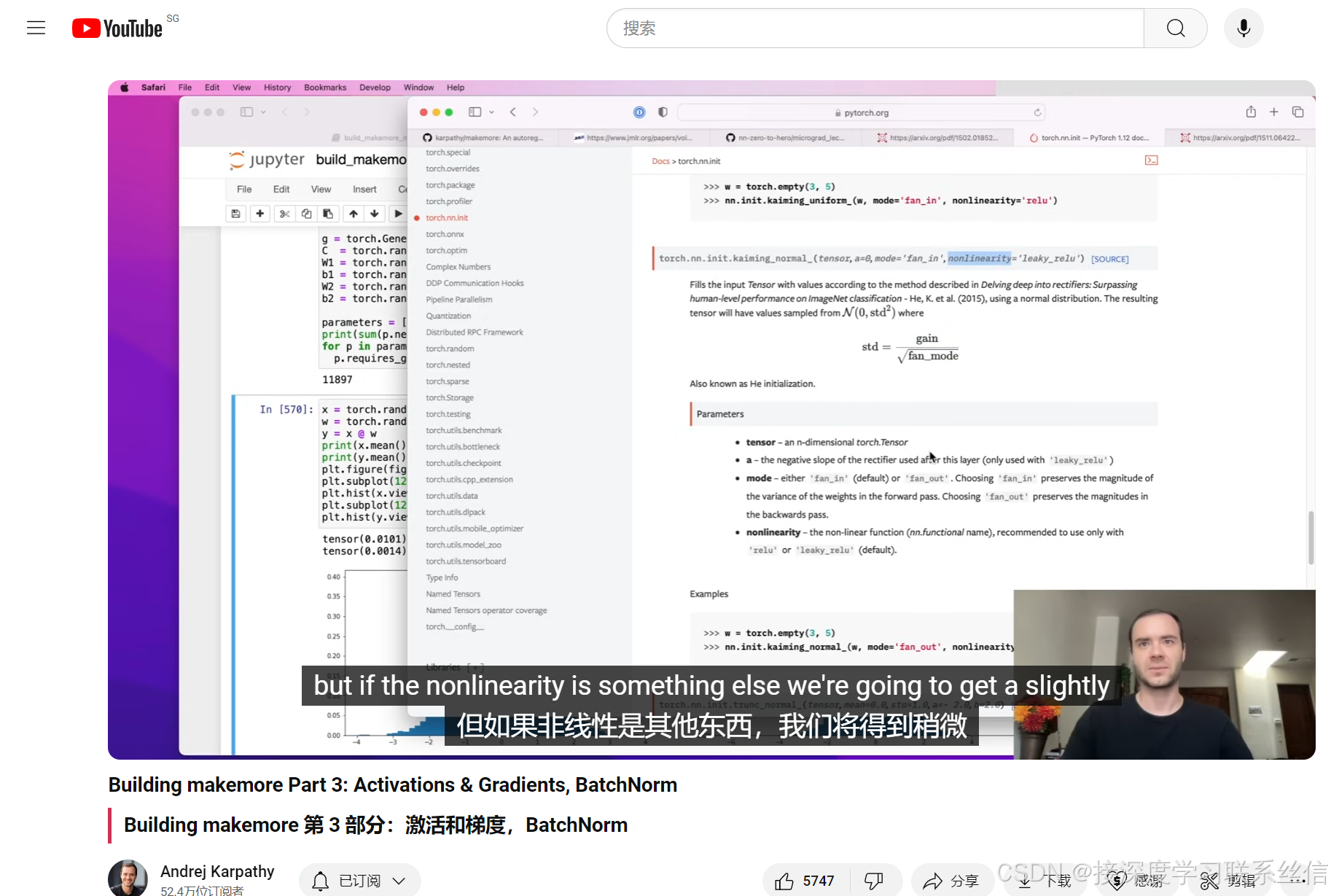
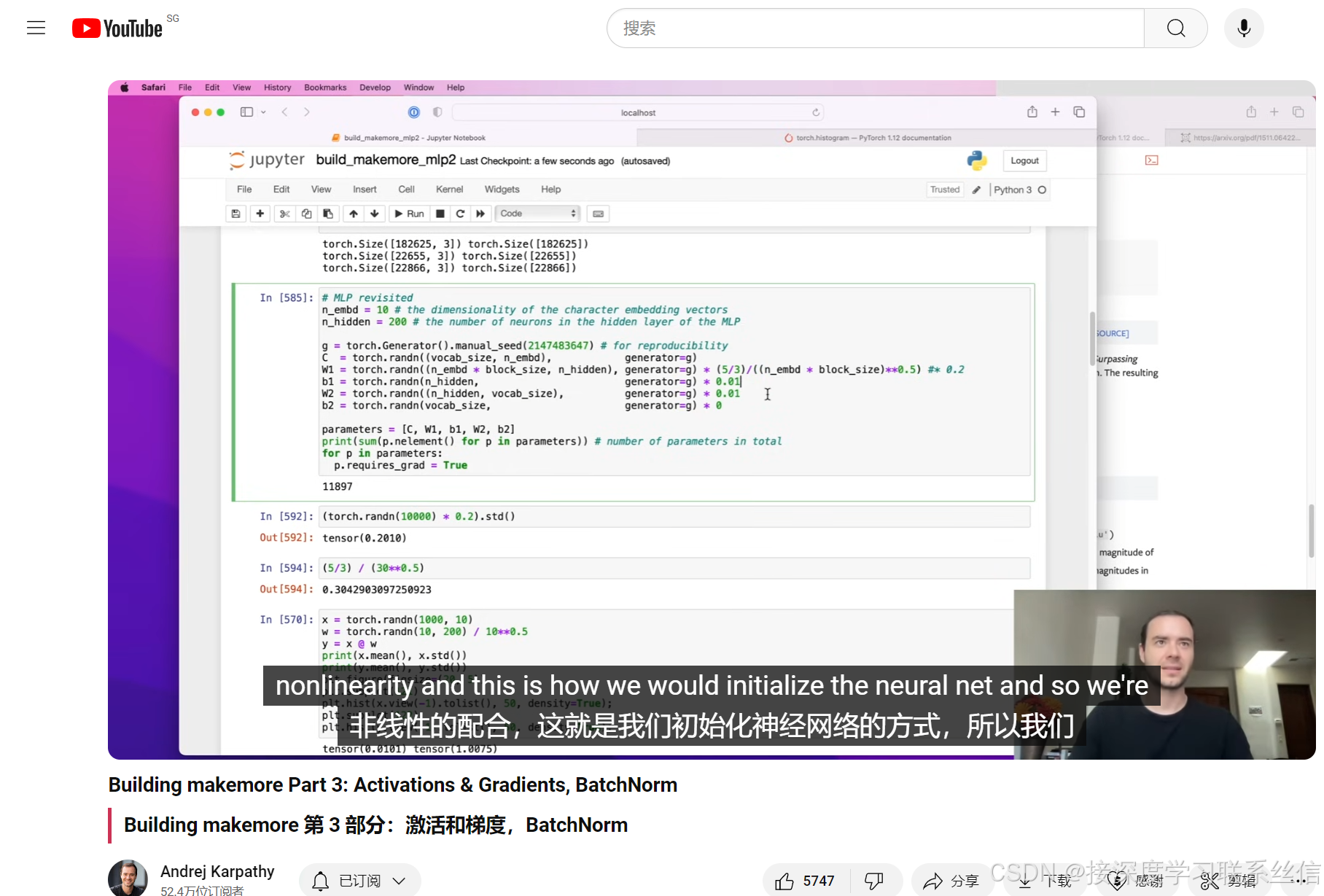
3. 具体 参数初始化 方法
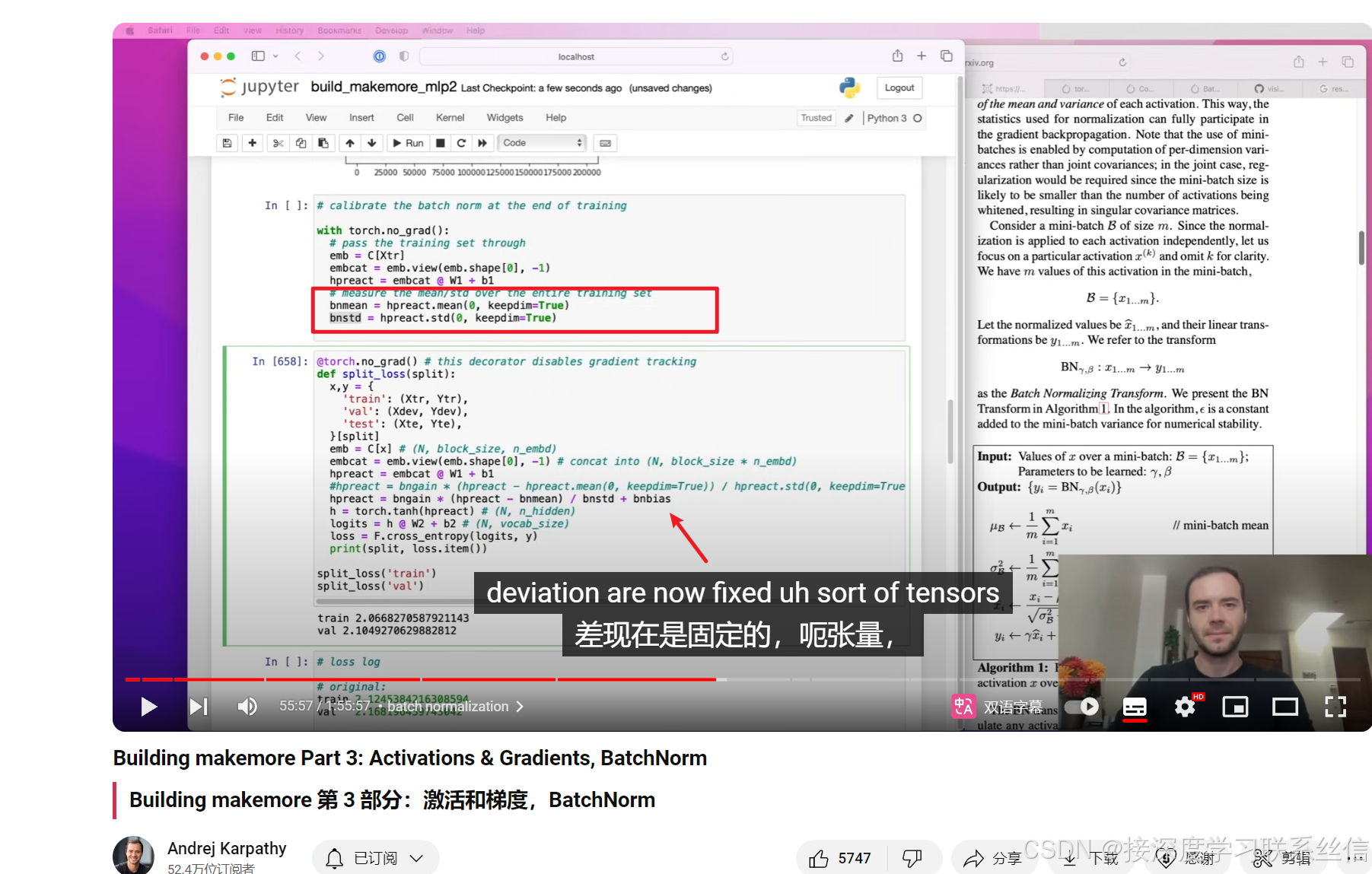
4. bn【对隐藏层也做归一化参数】,只在训练时用,测试不用
加上 bngain和 偏移bnbias
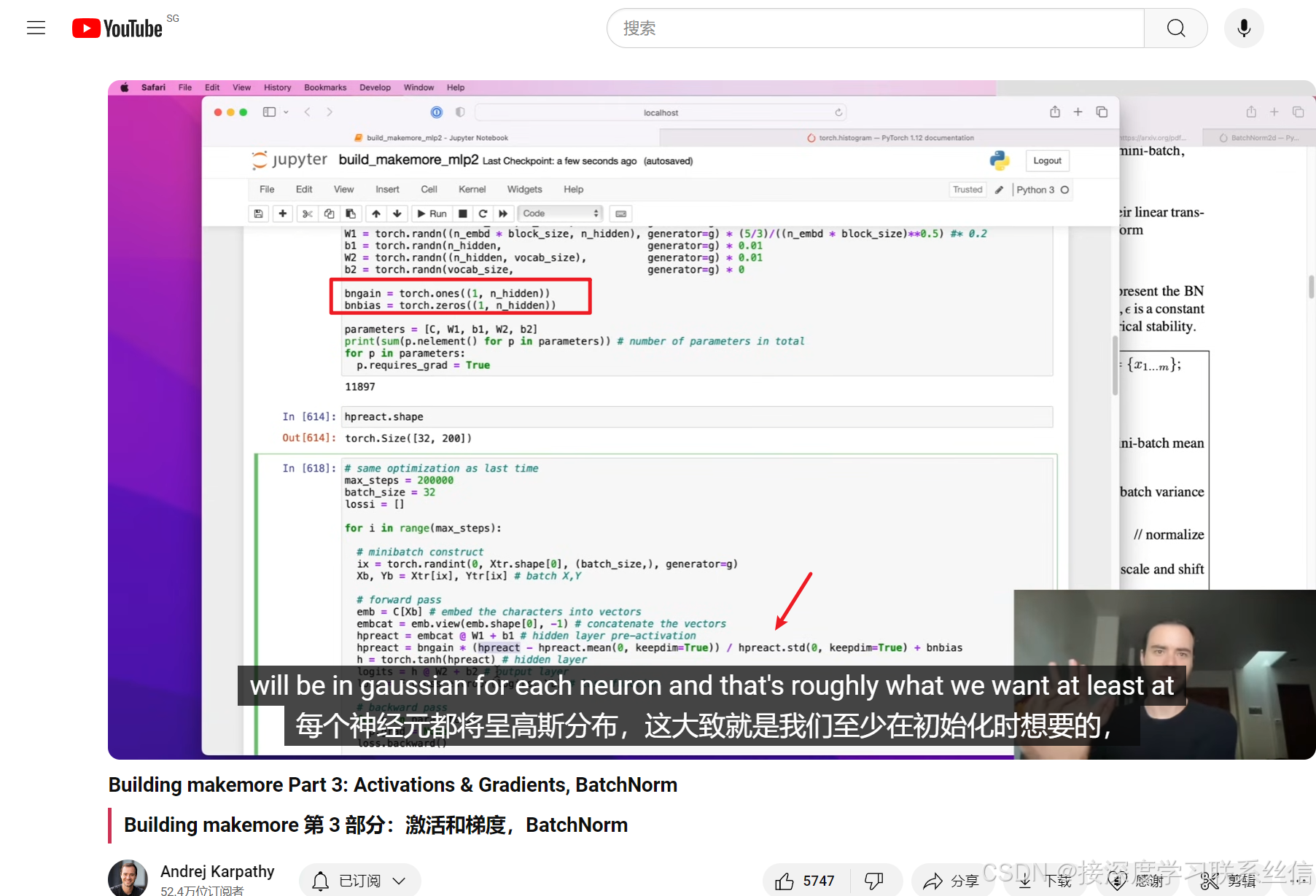
只在训练时用,测试不用
5. 梯度和值的比例不能过大





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









