









项目实战 – 用 Scrapy 抓取股票信息
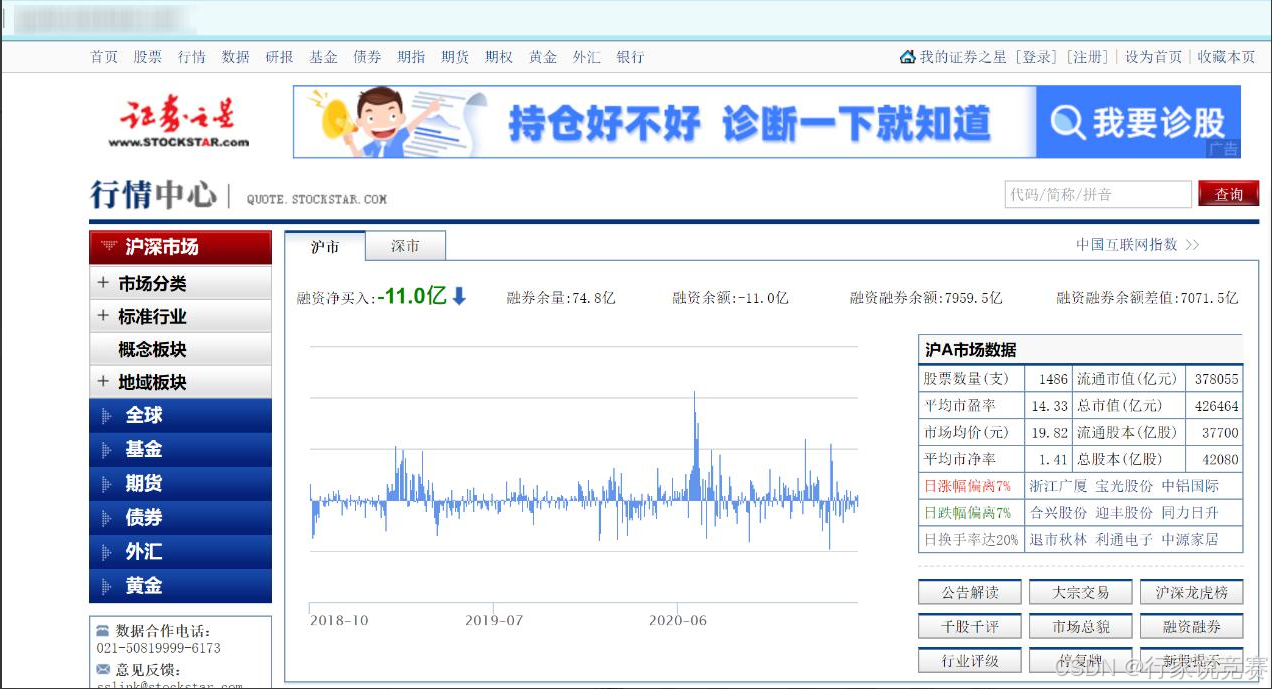
证券之星始创于 1996 年,是自中国互联网发展早期就开始提供财经资讯的专业网站。公司长期为投资者提供专业、及时、精准、深度的财经资讯服务,全面覆盖股票、基金、期货、黄金等投资领域。本项目用例就基于证券之星网站爬取 2021 年 4 月 4 日沪深 A 股页面中所有股票的市值和股本信息。
沪深 A 股市场数据图:
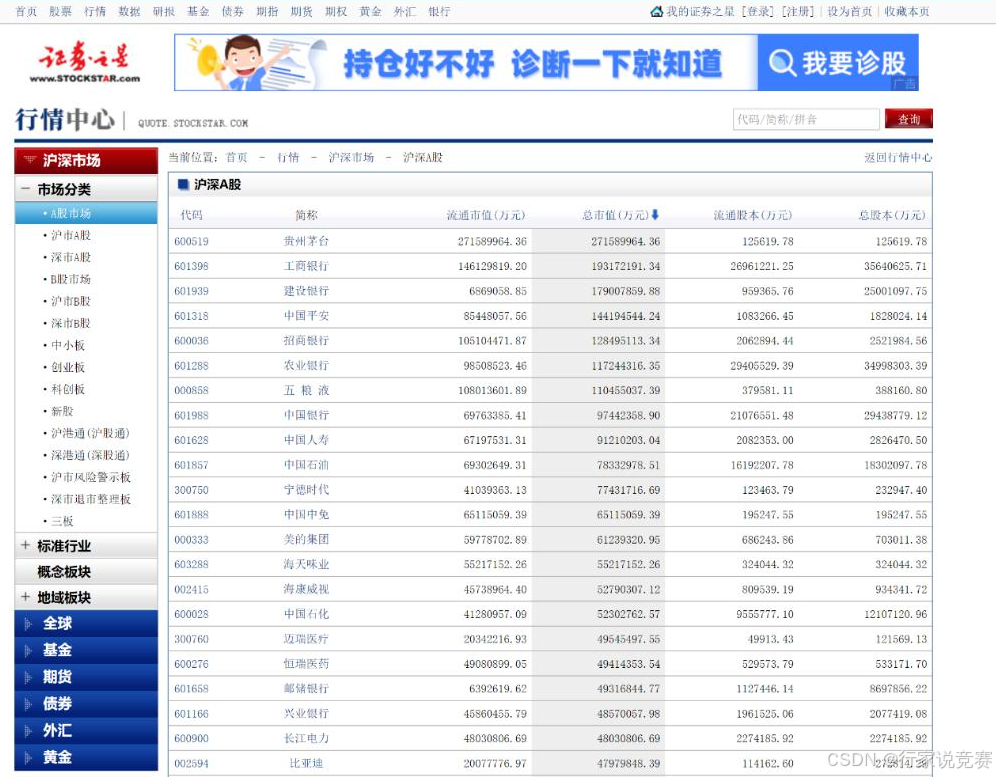
沪深 A 股所有股票的市值和股本信息:
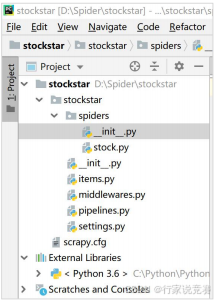
开 CMD 切到项目文件夹,输入以下代码 scrapy startproject stockstar 正式创建scrapy 项目,然后进入 stockstar 目录夹生成一个名为 stock 的爬虫,如图所示。


stockstar 目录结构,开始进行各个文件代码的编写。
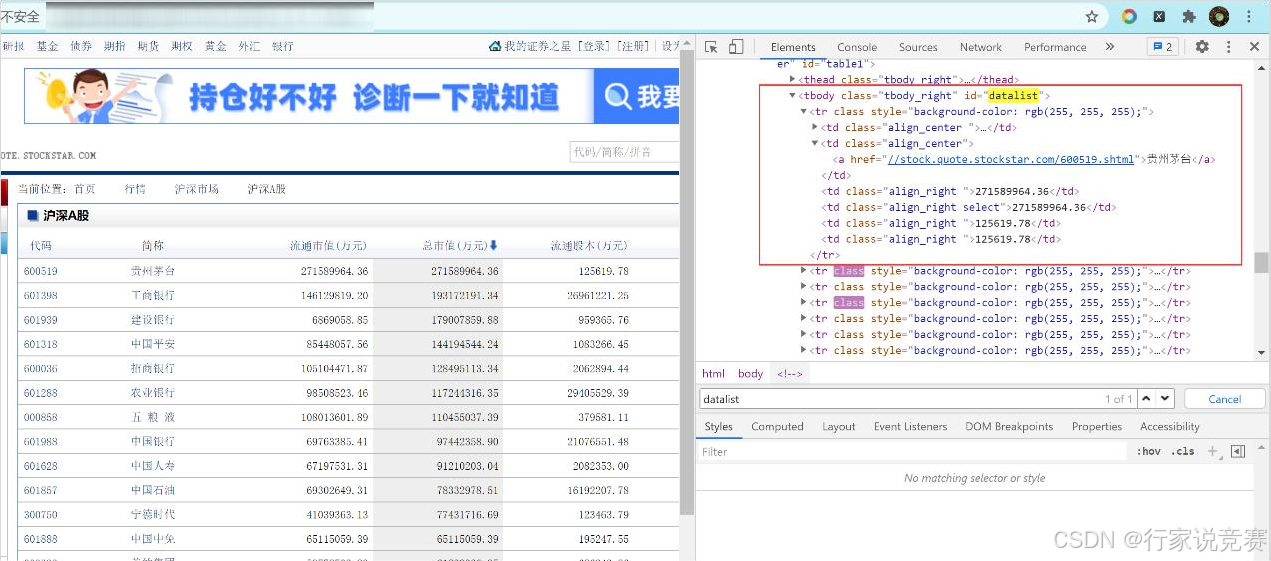
使用 Spider 提取数据,在提取数据之前还需要分析一下页面结构。如果找到相应网页地址“httpAddr-014”, 进而想爬取沪深 A 股各支股票的代码、简称、流通市值等信息,可以在浏览器中按 F12 进入 Elements 后查看网页结构信息。
找到 id=“datalist“的表格,各列的信息可以看作表格每列的列值,而这些列值可以分别看做 td 的 6 个子节点,如图所示。分析至此,开始撰写爬虫文件。
stock.py 中的代码如下。
#-*- coding: utf-8 -*-
import scrapy
from stockstar.items import StockstarItem, StockstarItemLoader
class StockSpider(scrapy.Spider):
74
75
name = 'stock'
allowed_domains = ['quote.stockstar.com']
start_urls = ['httpAddr-014']
def parse(self, response):
page = int(response.url.split("_")[-1].split(".")[0]) # 抓取页码
item_nodes = response.css('# datalist tr')
for item_node in item_nodes:
根据 item 文件所定义的字段内容,进行字段内容的抓取
item_loader = StockstarItemLoader(item=StockstarItem(),
selector=item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
item_loader.add_css("Circulation_market_value", "td:nth-child
(3)::text")
item_loader.add_css("Total_market_value", "td:nth-child
(4)::text")
item_loader.add_css("Circulating_share_capital", "td:nth-child
(5)::text")
item_loader.add_css("Total_share_capital", "td:nth-child
(6)::text")
stock_item = item_loader.load_item()
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace("{0}.html".format(page),
"{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
前几行代码相对比较熟悉,在代码的后半部分,def parse(self, response)函数中的for item_node in item_nodes 的循环中,根据 item 文件所定义的字段内容,进行字段内容的抓取。其中第一行中 StockstarItem ()为在 items.py 中声明的实例,response 为返回的响应,这属于固定写法。add_css()中第一个值为 items.py 中定义的值,第二个值为 css选择器规则。这个表格分了许多页,还需要先进行分页处理获取 page(页码)数,使用 for循环进行页面的翻页,直到页码最终为止。接着通过items.py 处理数据。
#-*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader(ItemLoader):
""" 自定义 itemloader,用于存储爬虫所爬取的字段内容
"""
default_output_processor = TakeFirst()
class StockstarItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
Circulation_market_value = scrapy.Field() # 流通市值
Total_market_value = scrapy.Field() # 总市值
Circulating_share_capital = scrapy.Field() # 流通股本
Total_share_capital = scrapy.Field() # 总股本
Item 本身是是存储爬取数据的容器,对所要爬取的网页数据进行分析,并定义所爬取的数据结构。本案例中使用的 pipelines.py 和 middlewares.py 使用默认生成的即可。
最后为了运行案例,还需要对 setting.py 文件进行编写。
settings.py(关键代码)
from scrapy.exporters import JsonItemExporter
# 默认显示的中文是阅读性较差的 Unicode 字符
# 需定义子类显示出原来的字符集(将父类的 ensure - ascii 属性设置为 False 即可)
class CustomJsonLinesItemExporter(JsonItemExporter):
def __init__(self,file,**kwargs):
super(CustomJsonLinesItemExporter,self).__init__(file,ensure_ascii=False,**kwar
gs)
BOT_NAME = 'stockstar'
SPIDER_MODULES = ['stockstar.spiders']
NEWSPIDER_MODULE = 'stockstar.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 启用新定义的 Exporter 类
FEED_EXPORTERS = {
'json':'stockstar.settings.CustomJsonLinesItemExporter',
}
DOWNLOAD_DELAY = 0.2
设置不遵守 Robot 协议,先修改 ROBOTSTXT_OBEY 为 False。此外,由于爬取的文件中有中文,为了确保显示准确,进行了相关文件的转换。再设置下载延迟为 0.2s,避免爬虫运行太快而被封。
运行 stock 爬虫并保存到相关文件中图,在 CMD 切换到项目目录执行,如图所示,运行 stock 爬虫并保存到相关文件。

stock 爬虫运行过程如图所示:
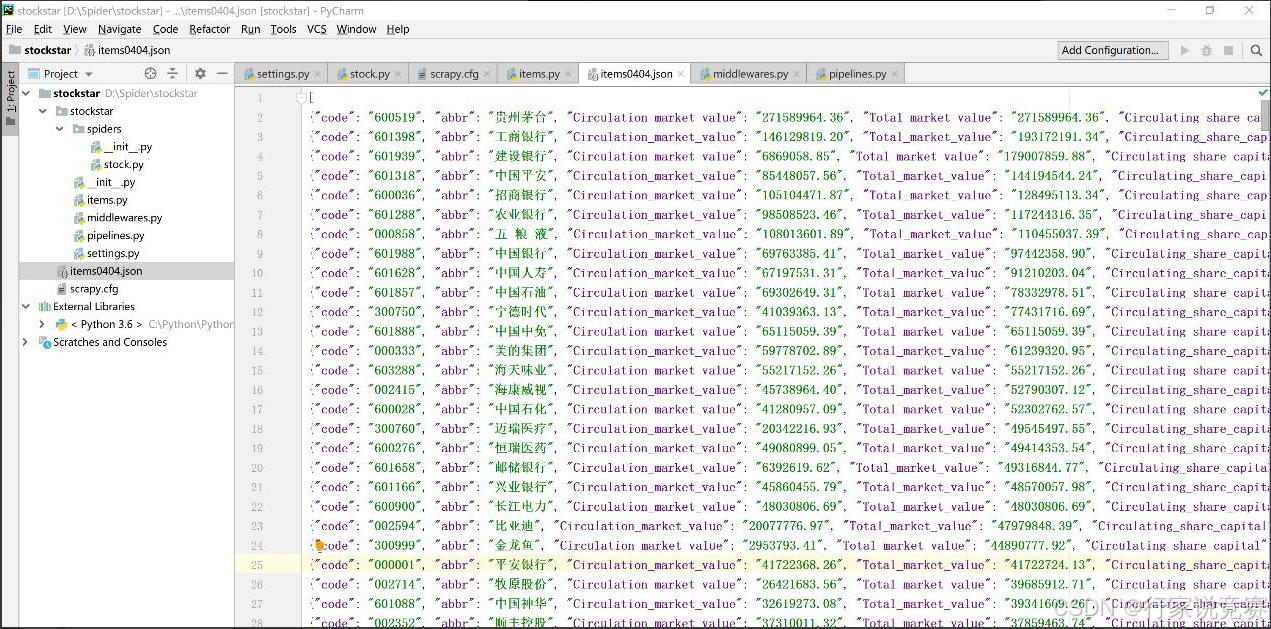
运行一会之后左侧则会出现 items0404.json 的文件,单击文件查看内容,如图所示:
总结
scrapy 是 Python 开发的一个快速、高层次的屏幕抓取和 web 抓取框架,用于抓取 web站点并从页面中提取结构化的数据。Scrapy 用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 内部帮我们实现了很多基础功能,比如调度器、下载器等,可以大大节省我们的工作,提升我们的开发效率,此外任何人都可以根据自己需求自定义相应的功能。总体来说,它是一个功能强大又不失灵活性的爬虫框架。通过这一章的学习,我们应要着重掌握Scrapy 框架各组件的使用方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









