







回想一下,我们搭建kafka集群是如何搭建?修改kafka得配置文件,多个Kafka服务注册到同一个zookeeper集群上的节点,会自动组成集群。
学习服务端原理,通常我们是去读服务端的那些抽象的代码,但是Kafka为了保证高吞吐,高性能,高可扩展的三高架构,很多具体设计都是相当复杂的。如果直接跳进去学习研究,估计我们很快就会晕头转向。那么有没有一些可见的东西让我们更具体的理解Kafka的Broker运行机制呢?
kafka依赖于zookeeper,Kafka会将每个服务的不同之处,也就是状态信息,保存到Zookeeper中。通过Zookeeper中的数据,指导每个Kafka进行与其他Kafka节点不同的业务逻辑。而将状态信息抽离后,剩下的数据,就可以直接存在Kafka本地,所有Kafka服务都以相同的逻辑运行。这种状态信息分离的设计,让Kafka有非常好的集群扩展性。
zk中存的kafka的数据:
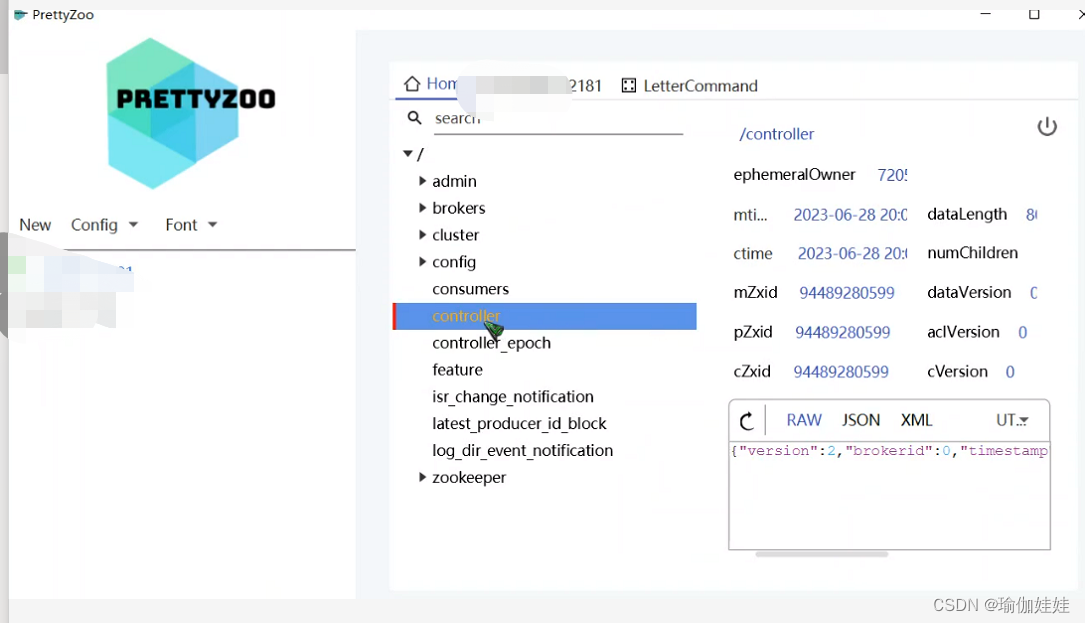
既然kafka依赖这么多的存储数据,那么我们就从可见的存储数据的角度来理解分析一下Kafka的Broker运行机制。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











