






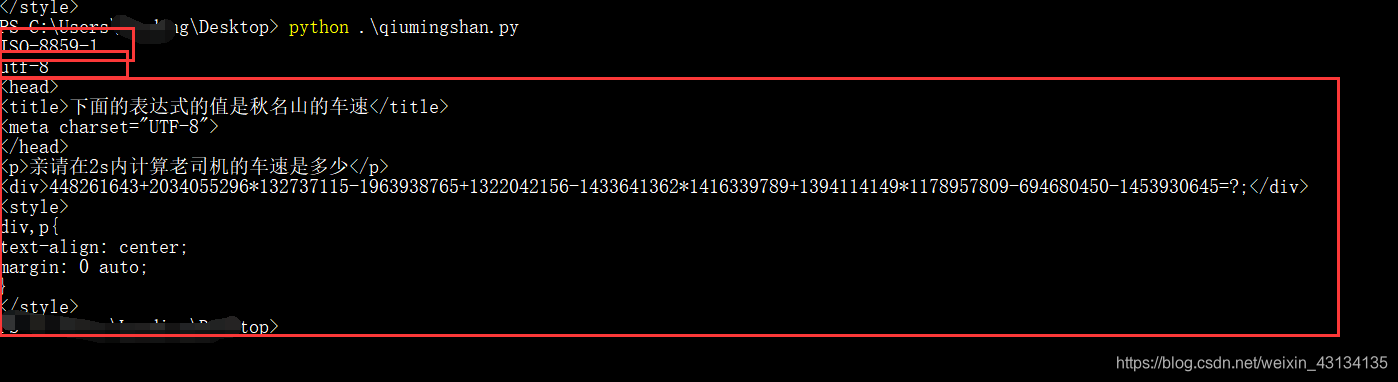
 博主为解决BUGKU一套题中Python爬取网页的中文乱码问题,尝试诸多方法后,借鉴大佬方法解决。通过查看Python编码环境(ISO - 8859 - 1)和网页编码(UTF - 8),将res.encoding改为res.apparent_encoding,重新输出解决编码问题。
博主为解决BUGKU一套题中Python爬取网页的中文乱码问题,尝试诸多方法后,借鉴大佬方法解决。通过查看Python编码环境(ISO - 8859 - 1)和网页编码(UTF - 8),将res.encoding改为res.apparent_encoding,重新输出解决编码问题。
python爬取网页中文乱码完美解决(简单) python2.7/3.7 2.x/3.x requetst
弄了差不多一个下午 使用了很多网上查的乱七八糟的方法 我觉得都是大佬- -…后来
借用真正膜拜大佬(简单明了)
http://www.cnblogs.com/bw13/p/6549248.html
我是为了BUGKU的一套题,python爬取
# -*- coding:utf-8 -*- #
import requests
url="http://123.206.87.240:8002/qiumingshan/"
res=requests.post(url)
print(res.encoding) #输出ISO-8859-1 当前系统编码
print(res.apparent_encoding) # 当前网页编码
res.encoding=res.apparent_encoding #重新编码
print(res.text)
首先 是post一个url 拿到res 相应
然后利用res.encoding来查看当前系统 就是我们自己的python的编码环境 会是ISO-8859-1
然后利用res.apparent_encoding 来查看一下当前爬取网页的编码 我的是UTF-8
然后改一下
res.encoding=res.apparent_encoding
再重新输出print(res.text)
短短几行
解决编码问题

















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









