






一、系统基础服务配置
| 主机名 | IP | 操作系统 | CPU | 内存 | 磁盘 |
| Hive01 | 10.86.102.104 | Centos 7.9.2009 | Xeon 4208 X16 | 192G | 46T |
| Hive02 | 10.86.102.102 | Centos 7.9.2009 | Xeon 4208 X16 | 192G | 46T |
| Hive03 | 10.86.102.105 | Centos 7.9.2009 | Xeon 8260 X48 | 256G | 11T |
最终组成的是一个双副本56T的集群,设置YARN内存共400GB(可调)
3台服务器安装CentOS Linux release 7.9操作系统,系统盘采用两个小容量的SSD组raid1(分区默认),数据盘使用整体raid5方式组成(raid0其实更好更快)。
1)用户:重置root用户密码,增加hadoop用户并设置密码
passwd root
useradd hadoop
passwd hadoop
2)网络:设置静态IP
修改BOOTPROTO="static"和ONBOOT="yes"
IPADDR="实际IP"
NETMASK="实际掩网子码"
GATEWAY="实际网关"
DNS1="实际DNS"
3)安全:关闭防火墙、关闭Selinux
systemctl status firewalld.service --查看防火墙状态
systemctl stop firewalld.service --关闭防火墙
systemctl disable firewalld.service --禁止防火墙开机自启动
setenforce 0 --临时关闭Selinux
/etc/selinux/config SELINUX=disabled --永久关闭SeLinux
4)互信:
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub Hive02
ssh-copy-id -i ~/.ssh/id_rsa.pub Hive03
5)主机:
修改主机名,增加三台服务器的ip和主机名
/etc/hostname
/etc/hosts
hostnamectl set-hostname --static Hive01、Hive02、Hive03
6)挂载数据盘:
格式化数据盘,整盘挂载
mkfs.xfs /dev/sdb 创建ext4文件系统
mkdir /data 创建数据目录
mount /dev/sdb /data 挂载
chown -R hadoop:hadoop /data 修改权限
修改/etc/fstab,mount -a确认是否挂载成功,df -h查看最新挂载情况
二、 应用安装
集群各服务规划如下:
| 服务名 | 服务器Hive01 | 服务器Hive02 | 服务器Hive03 |
| HDFS | NameNode DataNode | DataNode | NameNode DataNode |
| Yarn | NodeManager Resourcemanager | NodeManager Resourcemanager | NodeManager |
| Hive | Hive |
| 服务名称 | 版本 | 子服务 | 服务器 | ||
| Hive01 | Hive02 | Hive03 | |||
| HDFS | 3.3.1 | NameNode | √ | √ | |
| DataNode | √ | √ | √ | ||
| Yarn | 3.3.1 | NodeManager | √ | √ | √ |
| Resourcemanager | √ | √ |
| ||
| Hive | 3.1.2 | Hive | √ | ||
| Mariadb | 5.5.68 | Mariadb | √ | ||
2.1 常用安装包上传
上传所有安装包到指定一台服务器的opt目录
[hadoop@Hive01 ~]$ ll /opt
-rw-r--r--. 1 root root 605187279 Mar 8 13:59 hadoop-3.3.1.tar.gz
-rw-r--r--. 1 root root 1006904 Mar 20 10:09 mysql-connector-java-5.1.49.jar
-rw-r--r--. 1 root root 20795989 Apr 10 15:20 apache-hive-3.1.2-bin.tar.gz
-rw-r--r--. 1 root root 145520298 Mar 8 14:46 jdk-8u301-linux-x64.tar.gz
2.2 Zookeeper安装
1)解压至指定目录
[hadoop@Hive01 ~]$ cd /usr/local
[hadoop@Hive01 ~]$ mkdir zookeeper
[hadoop@Hive01 ~]$ cd zookeeper
[hadoop@Hive01 ~]$ tar -zxvf /opt/soft/apache-zookeeper-3.8.0-bin.tar.gz
2)配置
复制zoo_sample.cfg成zoo.cfg
[hadoop@Hive01 ~]$ cp zoo_sample.cfg zoo.cfg
更改zoo.cfg为以下内容
# The number of milliseconds of each tick
#tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
#initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
#syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
# the port at which the clients will connect
#clientPort=2181
# 客户端心跳时间(毫秒)
tickTime=2000
# 允许心跳间隔的最大时间
initLimit=10
# 同步时限
syncLimit=5
# 数据存储目录
dataDir=/data/zookeeper/data
# 数据日志存储目录
dataLogDir=/data/zookeeper/log
# 端口号
clientPort=2181
# 集群节点和服务端口配置
server.1=Hive01:2888:3888
server.2=Hive02:2888:3888
server.3=Hive03:2888:3888
#单个client与单台server之间的连接数的限制,是ip级别的,默认是60。假设设置为0。那么表明不作不论什么限制。请注意这个限制的使用范围,不过单台client机器
与单台ZKserver之间的连接数限制,不是针对指定clientIP,也不是ZK集群的连接数限制,也不是单台ZK对全部client的连接数限制。
maxClientCnxns=1200
#这个參数和上面的參数搭配使用,这个參数指定了须要保留的文件数目
autopurge.snapRetainCount=10
# 3.4.0及之后版本号,ZK提供了自己主动清理事务日志和快照文件的功能,这个參数指定了清理频率。单位是小时。须要配置一个1或更大的整数,默认是0。表不开启
自己主动清理功能
autopurge.purgeInterval=24 r
将此文件夹分发到其余的节点
[hadoop@Hive01 zookeeper]$ scp -r apache-zookeeper-3.8.0-bin hadoop@Hive02:/usr/local/zookeeper
[hadoop@Hive01 zookeeper]$ scp -r apache-zookeeper-3.8.0-bin hadoop@Hive03:/usr/local/zookeeper
在配置的dataDir这个参数的对应目录下手动创建节点标识文件myid,文件内容为序号(每一个节点都需要创建)。
![]()
3)验证
使用命令./bin/zkServer.sh start启动zookeeper服务
使用命令./bin/zkServer.sh status查看zookeeper服务状态

2.3 JDK安装
1)解压至指定目录
[hadoop@Hive01 ~]$ cd /usr/local
[hadoop@Hive01 ~]$ mkdir java
[hadoop@Hive01 ~]$ tar -zxvf jdk-8u301-linux-x64.tar.gz
[hadoop@Hive01 ~]$ mv jdk-8u301-linux-x64 jdk
2)配置profile和bashrc
以上两个文件末尾都加上以下部分内容
# jdk config
export JAVA_HOME=/usr/local/java/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
将此文件夹分发到其余的节点
[hadoop@Hive01 local]$ scp -r jdk hadoop@Hive02:/usr/local/java
[hadoop@Hive01 local]$ scp -r jdk hadoop@Hive03:/usr/local/java
配置完成后记得每个节点都需要source /etc/profile刷新配置文件
3)验证
使用命令java -version查看JDK版本

2.4 Hadoop安装
1)解压至指定目录
[hadoop@Hive01 ~]$ cd /usr/local
[hadoop@Hive01 ~]$ mkdir hadoop
[hadoop@Hive01 ~]$ cd hadoop
[hadoop@Hive01 ~]$ tar -zxvf hadoop-3.3.1.tar.gz
2)修改配置文件
主要修改以下配置文件:
hadoop-env.sh(三个节点都要改)
export JAVA_HOME=/usr/local/java/jdk
core-site.xml(三个节点都要改)
<configuration>
<!--默认HDFS文件系统地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<!--指定 hadoop 数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop</value>
</property>
<!--指定在Web UI和Servlet中使用的用户身份-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!--哪些主机可以通过代理用户(proxy user)访问Hadoop服务-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--哪些用户组可以通过代理用户(proxy user)访问Hadoop服务-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--副本的冗余数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--name路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/dfs/name</value>
</property>
<!--data路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/dfs/data</value>
</property>
<!--HDFS命名服务-->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!--所有NameNode节点的逻辑名称-->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1 web端访问地址-->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>Hive01:9870</value>
</property>
<!--nn1节点RPC协议地址-->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>Hive01:8020</value>
</property>
<!--nn2 web端访问地址-->
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>Hive03:9870</value>
</property>
<!--nn2节点RPC协议地址-->
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>Hive03:8020</value>
</property>
<!--指定NameNode的元数据 在JournalNode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Hive01:8485;Hive02:8485;Hive03:8485/cluster</value>
</property>
<!--JournalNode节点的通讯地址-->
<property>
<name>dfs.journalnode.rpc-address</name>
<value>Hive01:8485</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journalnode/cluster</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制,设置为sshfence表示使用SSH 22端口进行节点的隔离-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时,需要ssh免密登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--secondary namenode协议地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Hive02:9868</value>
</property>
<!--启用Web HDFS服务-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否启用HDFS的文件控制权限-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Hive01:2181,Hive02:2181,Hive03:2181</value>
</property>
<!--超时时间,单位 毫秒-->
<!--
<property>
<name>dfs.socket.timeout</name>
<value>240000</value>
</property>
-->
<!--指定用于在DataNode间传输block数据的最大线程数,默认4096 线上配置为40960-->
<!--
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
-->
<!--打开文件数量上限,不能超过系统打开文件数设置 线上配置40960-->
<!--
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
-->
<!--datanode同时处理客户端请求线程数,默认为10 线上配置500-->
<!--
<property>
<name>dfs.datanode.handler.count</name>
<value>50</value>
</property>
-->
<!--namenode线程数,越大消耗内存越大 线上配置500-->
<!--
<property>
<name>dfs.namenode.handler.count</name>
<value>50</value>
</property>
-->
<!--动态增删节点,下面两项配置,运行hadoop dfsadmin -refreshNodes 即可使其生效-->
<!--节点写在文件中-->
<!--
<property>
<name>dfs.hosts</name>
<value>/home/hadoop-3.3.1/etc/hadoop/slaves</value>
</property>
-->
<!-- 要删除的节点写在文件中 -->
<!--
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop-3.3.1/etc/hadoop/exclude-slaves</value>
</property>
-->
</configuration>
mapred-site.xml
<configuration>
<!--指定map reduce运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--指定mapreduce.jobhistory服务是否在yarn服务中运行-->
<!--如果将该参数设置为false,则表示mapreduce.jobhistory服务将在独立的进程中运行。-->
<property>
<name>mapreduce.jobhistory.server.embedded</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!--辅助服务,扩展自己的功能-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定资源计算器的类名-->
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
<!--指定MapReduce Shuffle服务的实现类-->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--指定ResourceManager高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--自动故障切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定rm的cluster集群id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!--nodemanager相关配置-->
<property>
<name>yarn.nodemanager.resourcemanager.connect.retry-interval.ms</name>
<value>3000</value>
</property>
<property>
<name>yarn.nodemanager.resourcemanager.connect.max-wait.ms</name>
<value>15000</value>
</property>
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.recovery.dir</name>
<value>/data/yarn/recovery</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>Hive03:8032</value>
</property>
<!--指定两个RM的名字-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--指定zk的部署的主机名和端口-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>Hive01:2181,Hive02:2181,Hive03:2181</value>
</property>
<!--指定rm1部署在的机器名-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>Hive01</value>
</property>
<!--指定rm1的RPC地址-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>Hive01:8032</value>
</property>
<!--指定rm1的管理RPC服务的地址-->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>Hive01:8033</value>
</property>
<!--指定rm1的web ui地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>Hive01:8088</value>
</property>
<!--指定rm1的web https ui地址-->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>Hive01:8090</value>
</property>
<!--指定rm2部署在的机器名-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>Hive02</value>
</property>
<!--指定rm2的RPC地址-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>Hive02:8032</value>
</property>
<!--指定rm2的管理RPC服务的地址-->
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>Hive02:8033</value>
</property>
<!--指定rm2的web ui地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>Hive02:8088</value>
</property>
<!--指定rm2的web https ui地址-->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>Hive02:8090</value>
</property>
<!--控制NodeManager上允许传递给应用程序的环境变量列表-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--指定ResourceManager最小的内存分配量-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>4096</value>
</property>
<!--指定ResourceManager最大的内存分配量-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<!--NodeManager在启动容器时虚拟内存和物理内存的比例-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!--控制MapReduce任务启动的Java虚拟机(JVM)的参数-->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx2048m</value>
</property>
<!--指定NodeManager上可用的物理内存总量-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>124928</value>
</property>
<!--指定NodeManager上可用的CPU核心数-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
<!--指定指定YARN日志聚合服务的地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://Hive01:19888/</value>
</property>
<!--指定应用程序的类路径-->
<property>
<name>yarn.application.classpath</name>
<value>hadoop classpath /usr/local/hadoop/hadoop-3.3.1/etc/hadoop:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/common/lib/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/common/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/hdfs:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/hdfs/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/mapreduce/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/yarn:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/yarn/lib/*:/usr/local/hadoop/hadoop-3.3.1/share/hadoop/yarn/*</value>
</property>
<!--控制是否启用YARN日志聚合服务-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--控制NodeManager上日志聚合的滚动监控时间间隔-->
<property>
<name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name>
<value>3600</value>
</property>
<!--mapreduce历史作业服务:端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>Hive01:10020</value>
</property>
<!--mapreduce历史作业web ui服务端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Hive01:19888</value>
</property>
<!--指定应用程序日志的保存目录-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
</configuration>
将此文件夹分发到其余的节点
[hadoop@Hive01 local]$ scp -r hadoop Hive02:/usr/local/hadoop
[hadoop@Hive01 local]$ scp -r hadoop Hive03:/usr/local/hadoop
3)验证
各节点/etc/profile、~/.bashrc文件末尾都加上以下部分内容
# hadoop config
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
配置完成后记得每个节点都需要source /etc/profile刷新配置文件
使用命令hadoop version查看hadoop版本

[hadoop@Hive01 local]$ whereis hdfs
[hadoop@Hive01 local]$ whereis start-all.sh
若能正常显示路径说明设置正确

4)格式化 namenode(此处有坑,不过别急)
使用命令hadoop namenode -format格式化第一个 namenode
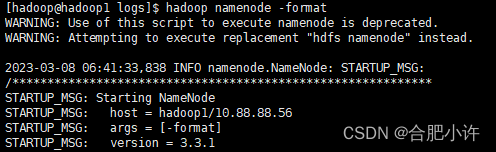
然后再到第二个namenode Hive03上执行格式化namenode操作(hdfs namenode -format),操作完成后进行引导(hdfs namenode -bootstrapStandby)
5)起服务,并验证服务是否正常起来
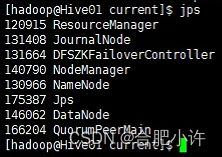
hdfs: namenode主节点 http://Hive01:9870/
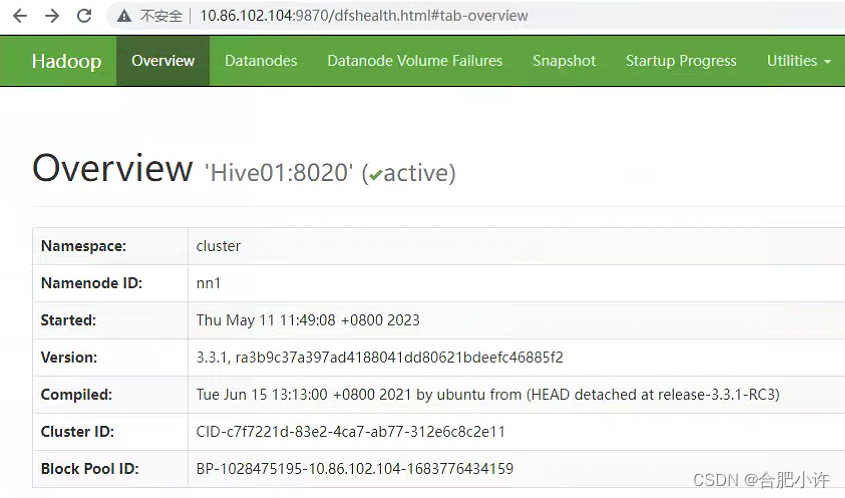
namenode备用节点 http://Hive03:9870/
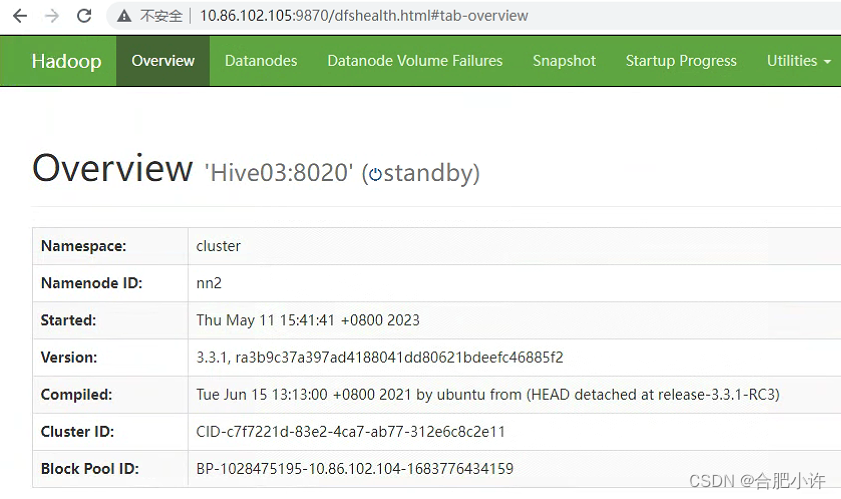
yarn: resourcemanager主节点 http://Hive02:8088/
resourcemanager备节点 http://Hive01:8088/ 输入后会自动跳转到主节点地址
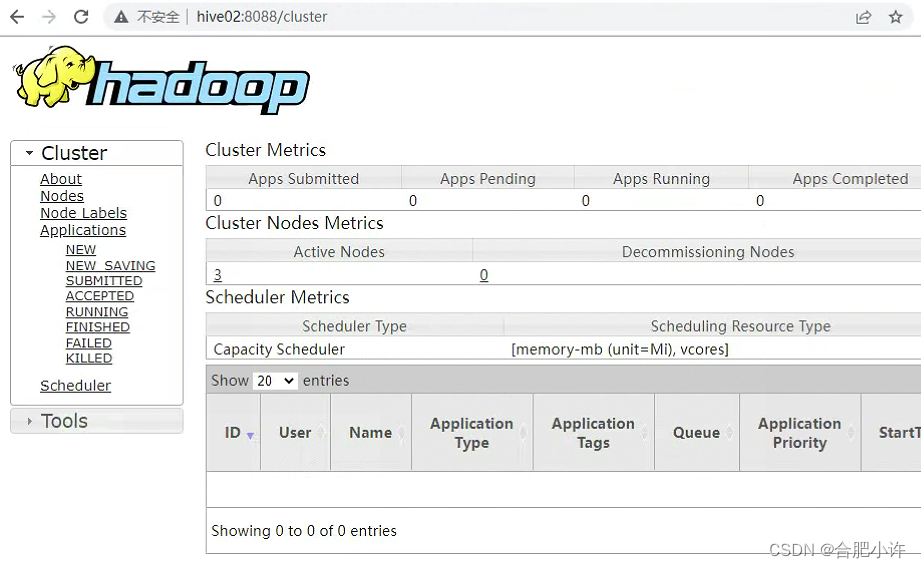
需要做数据仓库的继续往下看
2.5 Hive安装
1)解压至指定目录
[hadoop@Hive01 ~]$ cd /usr/local
[hadoop@Hive01 ~]$ mkdir hive
[hadoop@Hive01 ~]$ cd hive
[hadoop@Hive01 ~]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz
2)配置环境变量
/etc/profile和~/.bashrc两个文件末尾都加上以下部分内容
# hive config
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
新增完记得source 刷新配置文件。
3)修改配置文件
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Hive03:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/hive/</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://Hive03:9083</value>
</property>
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>Hive03</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
</configuration>
4)启动hive服务
复制mysql-connector-java-5.1.49.jar到Hive lib库
初始化Hive元存储的数据库架构schematool -dbType mysql -initSchema
启动元数据metastore服务
nohup hive --service metastore >> /home/hadoop/metastore.log 2>&1 &
启动hiveserver2服务
nohup hive --service hiveserver2 >> /home/hadoop/hiveserver.log 2>&1 &
5)测试beeline是否可以连接
beeline连接hive
beeline -u jdbc:hive2://Hve03:10000 -n root
2.6 Mariadb安装
1)yum方式安装启动mariadb服务
[hadoop@Hive01 ~]$ yum install mariadb* -y
2)mariadb服务配置
①安装完成后首先要把MariaDB服务开启,并设置为开机启动
[hadoop@Hive01 ~]# systemctl start mariadb # 开启服务
[hadoop@Hive01 ~]# systemctl enable mariadb # 设置为开机自启动服务
②首次安装需要进行数据库的配置,命令都和mysql的一样
[root@aaa]# mysql_secure_installation
③配置时出现的各个选项
Enter current password for root (enter for none): # 输入数据库超级管理员root的密码(注意不是系统root的密码),第一次进入还没有设置密码则直接回车
Set root password? [Y/n] # 设置密码,y
New password: # 新密码 password
Re-enter new password: # 再次输入密码 password
Remove anonymous users? [Y/n] # 移除匿名用户, y
Disallow root login remotely? [Y/n] # 拒绝root远程登录,n,不管y/n,都会拒绝root远程登录
Remove test database and access to it? [Y/n] # 删除test数据库,y:删除。n:不删除,数据库中会有一个test数据库,一般不需要
Reload privilege tables now? [Y/n] # 重新加载权限表,y。或者重启服务也许
④测试是否能够登录成功,出现 MariaDB [(none)]> 就表示已经能够正常登录使用MariaDB数据库了
[hadoop@Hive01 ~]# mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 8
Server version: 5.5.60-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
3)MariaDB字符集配置
①/etc/my.cnf 文件
在 [mysqld] 标签下添加
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
②/etc/my.cnf.d/client.cnf 文件
在 [client] 标签下添加
default-character-set=utf8
③/etc/my.cnf.d/mysql-clients.cnf 文件
在 [mysql] 标签下添加
default-character-set=utf8
④重启服务
[hadoop@Hive01 ~]# systemctl restart mariadb
⑤进入mariadb查看字符集
MariaDB [(none)]> show variables like "%character%";show variables like "%collation%";
4)创建用户,配置权限
[hadoop@Hive01 ~]# mysql -u root -p
CREATE USER 'hive'@'%' IDENTIFIED BY 'password';
GRANT ALL ON *.* TO 'hive'@'%';
flush privileges;
systemctl restart mariadb
5)hive数据库连接测试
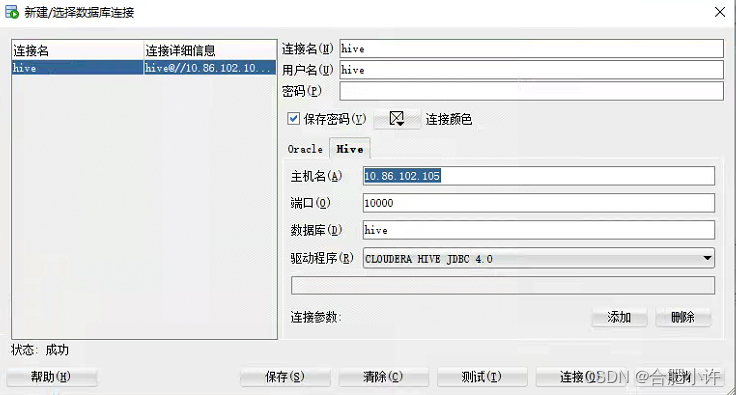
下载SQL Developer 4.1.5,和驱动Hive JDBC Driver for Oracle SQL Developer
添加后重启sqldeveloper。再次打开sqldeveloper后,点击”新建连接”之后,多了”Hive”数据库,点击测试,提示成功后即可连接;
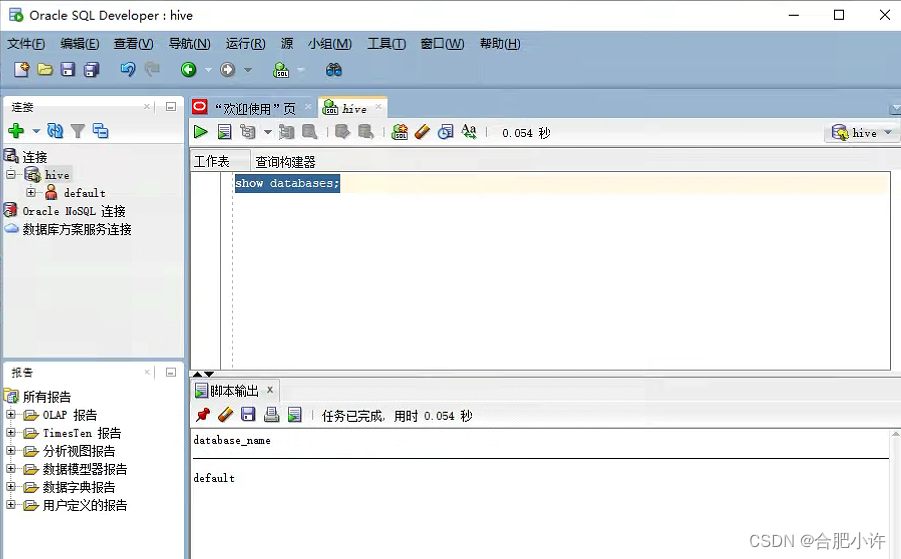
以下是连接后展示的数据库:
有错误请指正,有问题咨询请留言,知无不言,言无不尽~

















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









