




 本文介绍了一种高效的视频语义分割方法,该方法在训练过程中加入帧间时序一致性约束,并在推断阶段独立处理每一帧。通过运动引导的时序一致性及知识蒸馏策略,平衡了精确度与时序平滑性。
本文介绍了一种高效的视频语义分割方法,该方法在训练过程中加入帧间时序一致性约束,并在推断阶段独立处理每一帧。通过运动引导的时序一致性及知识蒸馏策略,平衡了精确度与时序平滑性。
《Efficient Semantic Video Segmentation with Per-frame Inference》论文阅读笔记
文章链接:https://arxiv.org/pdf/2002.11433
GitHub地址:https://github.com/irfanICMLL/ETC-Real-time-Per-frame-Semantic-video-segmentation/
GitHub项目地址暂时功能不全,代码没有实现知识蒸馏部分(截至2021/11/19前是这样)。我接下来可能会把这部分完成,如果达到作者文章中的实验结果我会放到GitHub上。
[摘要]视频语义分割任务中,大多数基于每一帧独立训练的实时分割的深度学习方法,在测试的视频序列中可能会有不一致的结果。有几种
方法考虑到了视频序列之间的相关性,例如使用光流信息传播相邻帧之间的结果,或者使用多帧信息提取当前帧的表示,但是这可能
会导致不精确的结果或者不平衡的延迟。
这篇论文明确在训练阶段考虑了帧之间的时序一致性作为额外的约束,并在inference阶段独立处理每一帧以减少处理时间。并使用
设计了时序知识蒸馏,权衡精确性、时序平滑和效率。
1.Methods
1.1 运动引导的时序一致性(Motion Guided Temporal Consistency)
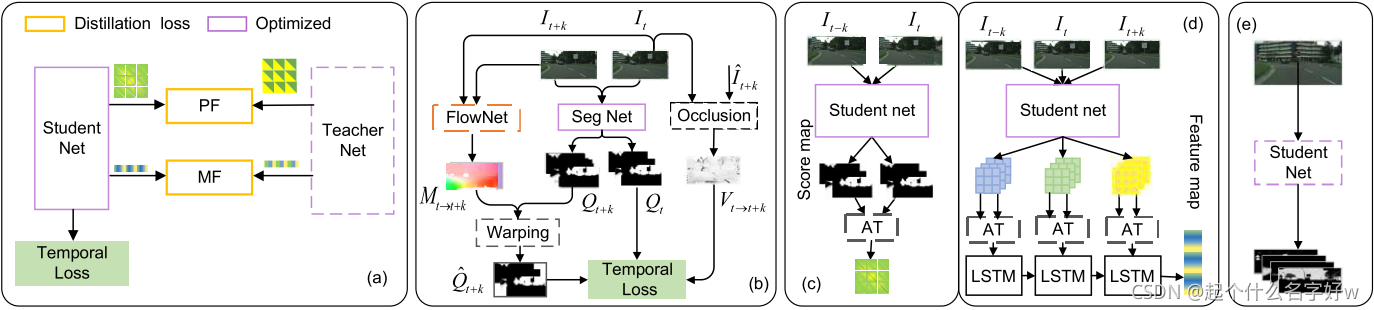
作者使用之前帧的预测结果作为当前帧的监督信号,沿时间轴为每个相应的像素分配一致的标签。如图2(b)所示,对应时间t和t+k的两个输入帧It和It+k,计算如下损失:

其中,qit代表分割图上在位置i的预测类别的概率,q^\hat{q}q^it+k=>t是通过使用运动估计网络(eg:flownet)得到的帧t+k到帧t扭曲类别的概率,Vt=>t+k用于移除扭曲类别概率错误产生的噪声。Vt=>t+k=exp(-|It - I^\hat{I}I^t+k|), I^\hat{I}I^t+k是通过扭曲的输入帧。作者直接使用预训练的光流预测网络作为运动估计网络。
1.2 时序一致性知识蒸馏(Temporal Consistency Knowledge Distillation)
文章使用蒸馏机制借助大型teacher(T)网络有效的训练得到一个轻量级student(S)网络,teacher网络是使用交叉熵损失和时序损失已经训练好的有着高时序一致性和分割精度的网络。不同于之前的单帧蒸馏方法,作者设计了两个新的蒸馏策略用于从T到S转换时序一致性:(1)成对帧依赖(pair-wise-frames dependency(PF));(2)多帧依赖(multi-frame dependency(MF)).
Pair-wise-Frames Dependency:使用一个注意力(AT)操作用于计算两个输入向量X1和X2之间的成对相似map(pair-wise similarity map)A,对应A中的一个像素点ai,j是通过计算对应X1和X2中位置Xi1和Xj2之间的余弦值得到的。
如图2©,通过使用AT操作编码两个相邻帧的预测结果之间的成对依赖关系,获得相似map AQt,Qt+k,其中Qt是第t帧的分割结果,并且AQt,Qt+k中的像素点ai,j表示第t帧中位置i和第t+k帧中位置j的类别概率的相似性。如果在帧t的位置i上的一个像素移动到帧t+k的位置j,相似度aij可能会更高。因此,成对依赖可以反映两帧之间的运动相关性。然后使用下面公式(2)对齐教师网络T和学生网络S之间的成对帧(PF)依赖关系:

Multi-Frame Dependency:将上述相邻帧的操作扩展到视频序列,如图2(d),并引入ConvLSTM单元编码自相似map AFt,Ft序列到编码空间E∈\in %∈R\mathbb{R}R1xDe,其中De是embedding空间的长度。对于每个时间步长,ConvLSTM单元以AFt,Ft和包含前t1帧信息的隐藏状态作为输入,并给出一个随当前时间步长隐藏状态embedding Et的输出。对齐在最后的时间步输出的来自T和S的embedding ET和ES。输出embedding编码整个输入序列的关系,称为多帧依赖(MF)。基于多帧依赖的蒸馏损失如下:

ConvLSTM单元的参数与student网络一起优化。为了提取多帧依赖关系,教师网和学生网共享ConvLSTM单元的权重。当ConvLSTM中的权重和偏差都等于零时,存在一个模型崩溃点。为了防止模型崩溃,作者将ConvLSTM的权值控制在一定范围内,并将ET增大作为正则化,防止模型崩溃。
网络的总损失:
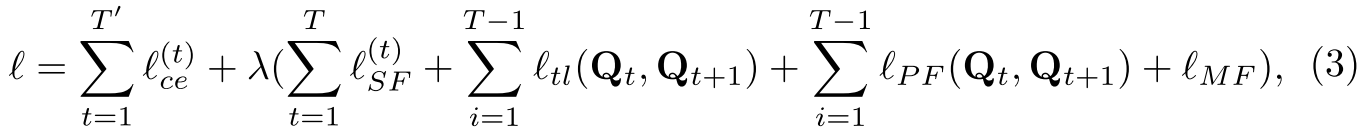
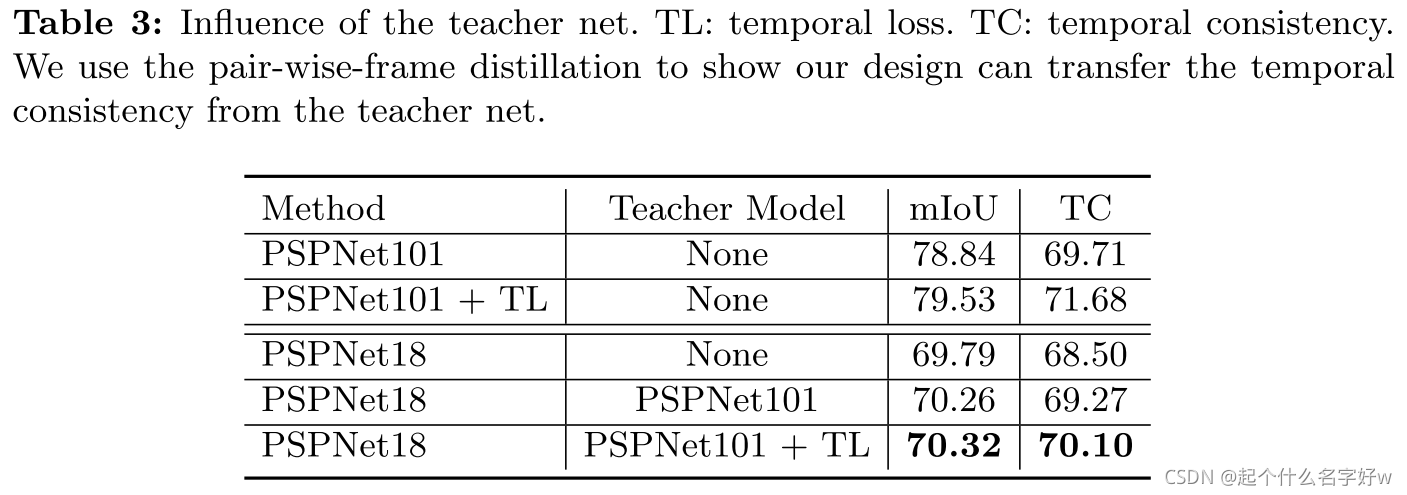
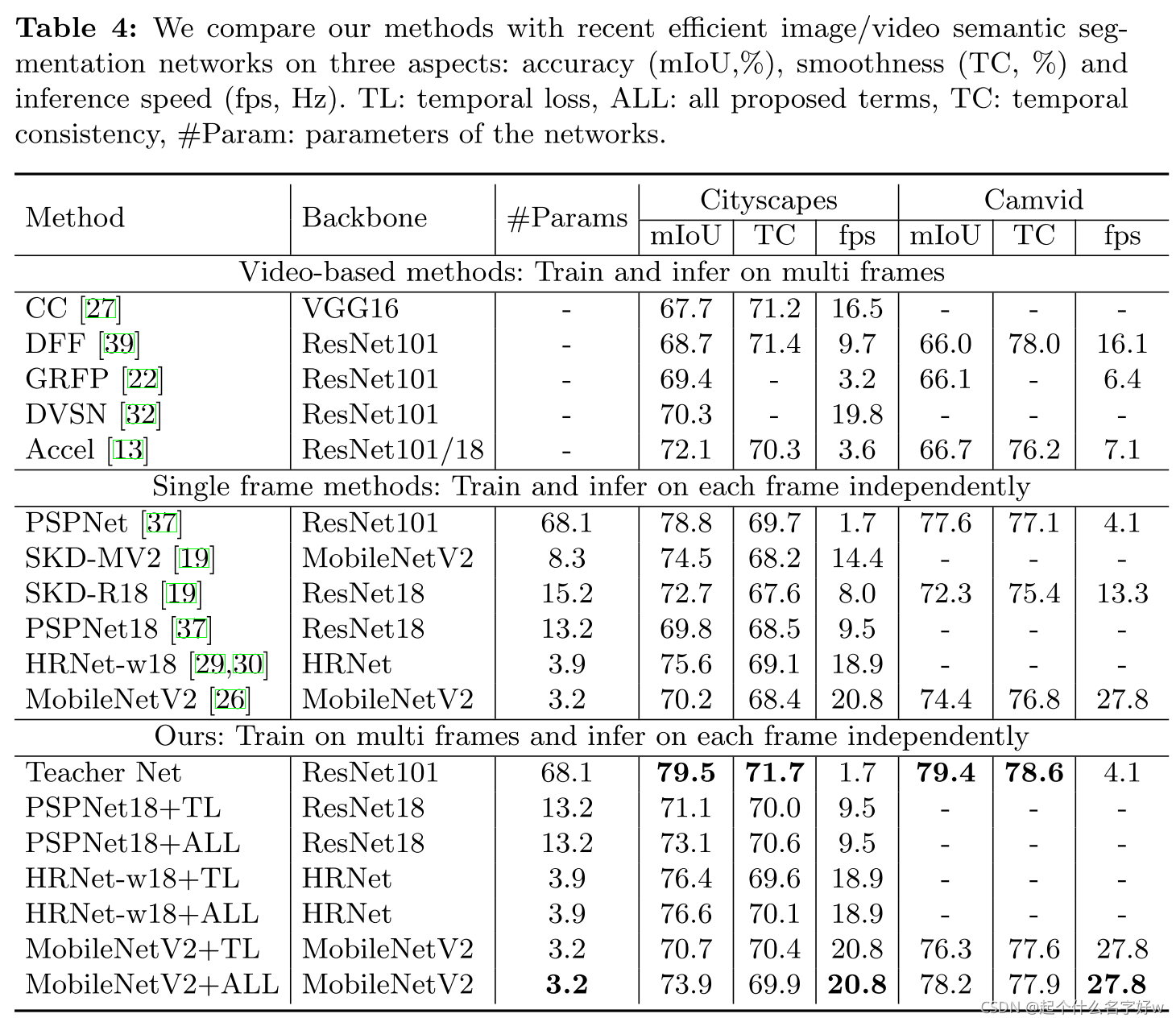
文章的主要思想就是上面这些,具体实验细节文章也有描述。下面再贴一下部分实验结果。
实验
数据
1.cityscapes
cityscapes的视频数据(数据下载地址https://www.cityscapes-dataset.com/downloads/,页面中的leftImg8bit_sequence_trainvaltest.zip (324GB) [md5]是视频序列数据)
2.CamVid
原网址好像没有下载链接,可以之间通过这个链接下载:https://s3.amazonaws.com/fast-ai-imagelocal/camvid.tgz
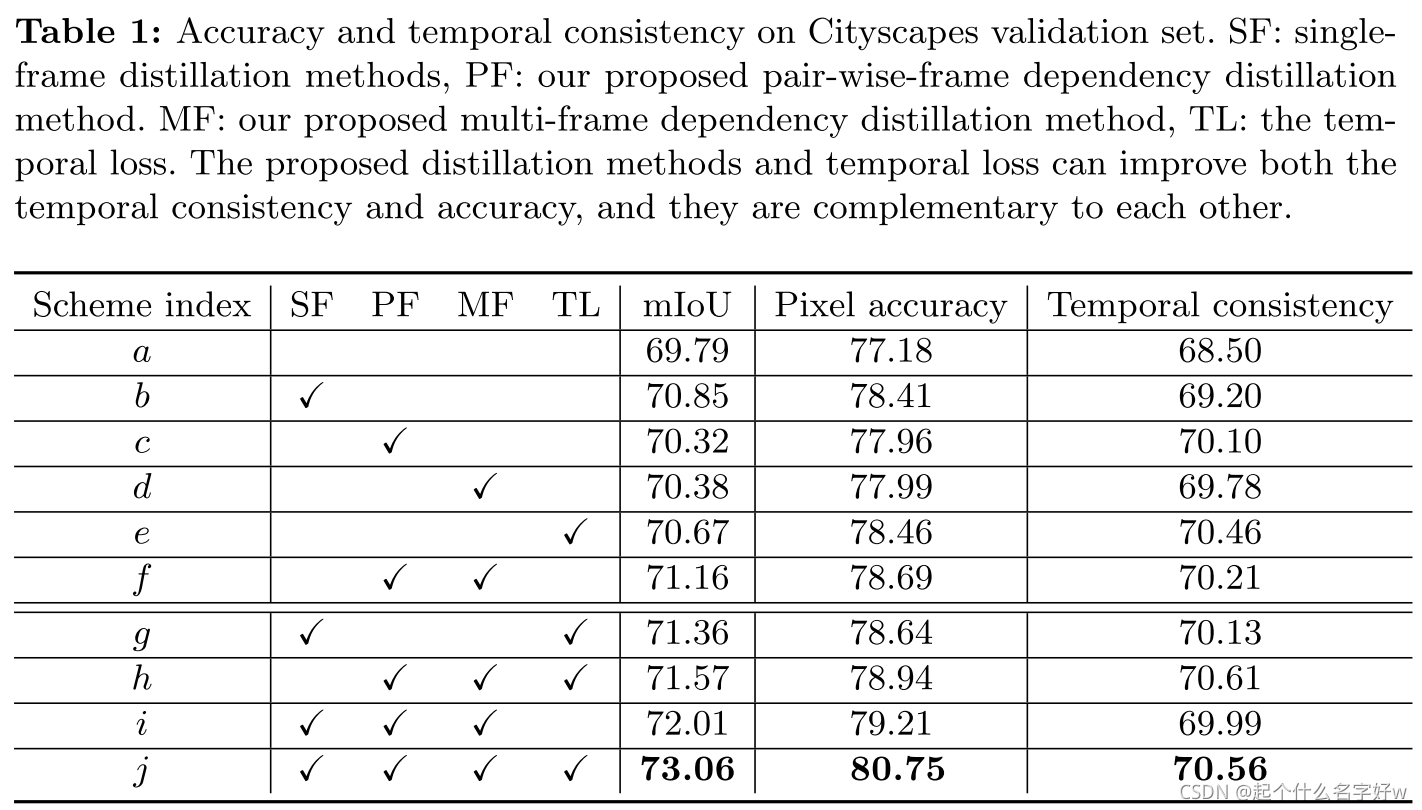
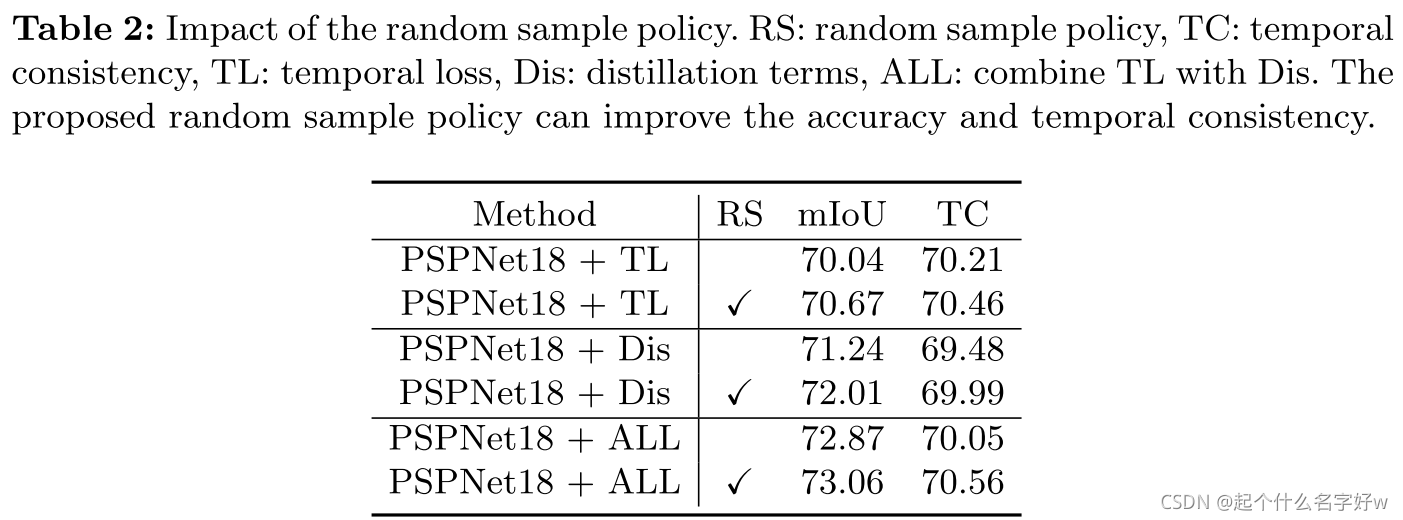
部分实验结果


















 3435
3435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











