




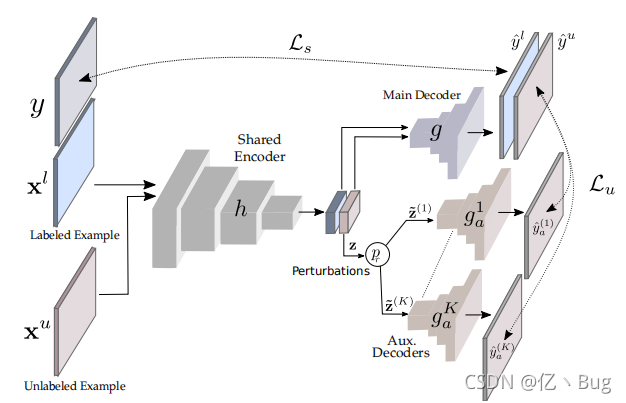
 本文介绍了Semi-Supervised Semantic Segmentation with Cross-Consistency Training算法,探讨了在标签获取成本高的语义分割领域,如何利用未标记数据训练分割网络。该方法采用一个共享编码器和多个辅助解码器,通过扰动输入以增强模型预测的一致性,减少过拟合,提升模型性能。
本文介绍了Semi-Supervised Semantic Segmentation with Cross-Consistency Training算法,探讨了在标签获取成本高的语义分割领域,如何利用未标记数据训练分割网络。该方法采用一个共享编码器和多个辅助解码器,通过扰动输入以增强模型预测的一致性,减少过拟合,提升模型性能。
文章标题:Semi-Supervised Semantic Segmentation with Cross-Consistency Training
文章地址:https://arxiv.org/abs/2003.09005
文章代码: https://github.com/yassouali/CCT
领域:半监督语义分割
小白入坑笔记,有理解不对的地方,欢迎各位大佬指正

一、Cross-Consistency Training提出的原因

在语义分割领域标签获得成本较高,作者希望利用更多的未标记例子来训练分割网络,从而有效处理与训练数据分布相同的测试数据
从上图可以看出,低密度区域在隐藏表示中比在输入中更明显。在Input level 中,低密度区域无法与类别边界对齐,因此聚类假设不适用;在Hidden representations level 各个类别更紧凑,与其他类别界限明显。因此,就想到利用编码器的输出来增强模型不同形式的扰动的一致性
二、算法流程及特点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









