







 本文详细介绍了MapReduce的工作流程,包括InputFormat阶段如何获取输入分片,MapTask阶段的业务处理,以及Map-Shuffle阶段涉及的分区、溢写、排序等关键步骤。此外,还解释了ReduceTask的处理流程。
本文详细介绍了MapReduce的工作流程,包括InputFormat阶段如何获取输入分片,MapTask阶段的业务处理,以及Map-Shuffle阶段涉及的分区、溢写、排序等关键步骤。此外,还解释了ReduceTask的处理流程。
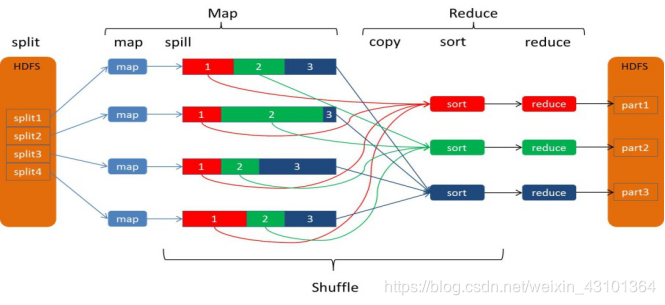
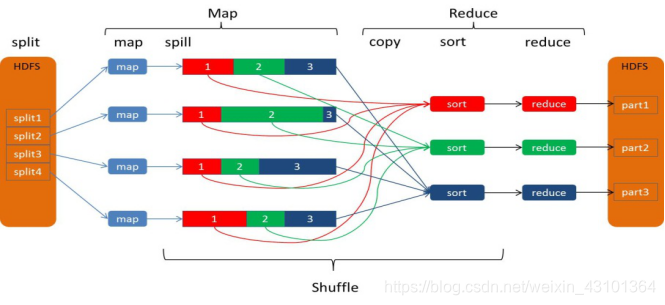
Mapreduce的过程整体上分为四个阶段:InputFormat 、MapTask 、ReduceTask 、OutPutFormat
InputFormat :
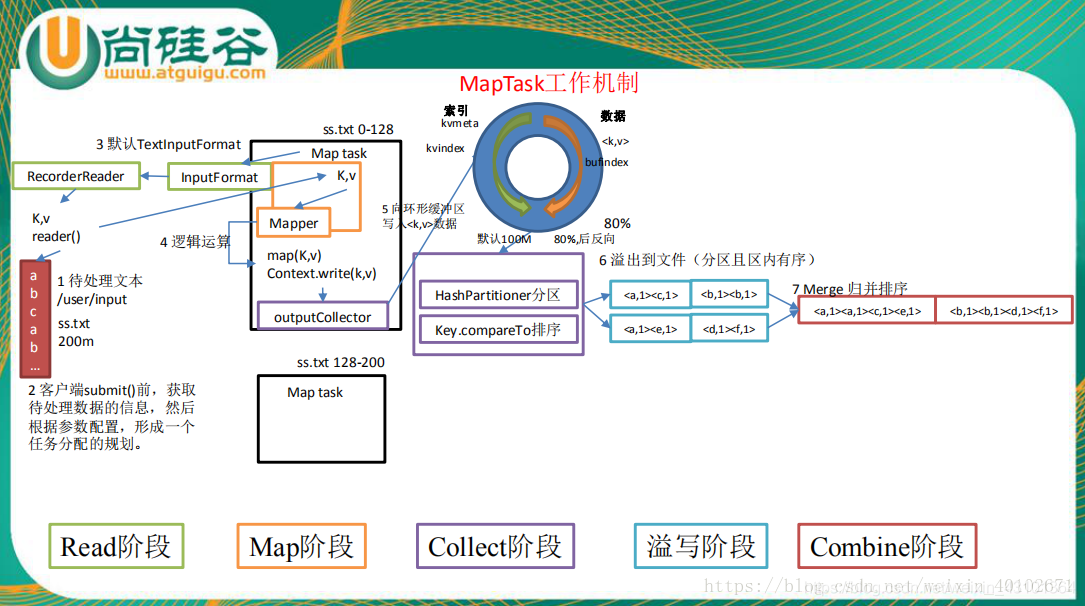
默认是FileInputFormat中的TextInputFormat类,获取输入分片,使用默认的RecordReader:LineRecordReader将一个输入分片中的每一行按\n分割成key-value key是偏移量 value是每一行的内容。调用一次map()方法。一个输入分片对应一个Maptask任务,项目中使用了TableMapReduceUtil(hbase和Mapreduce的整合类)来设置的输入目录。
MapTask:
每一个key-value经过map()方法业务处理之后开始开始shuffle阶段
Map-Shuffle:
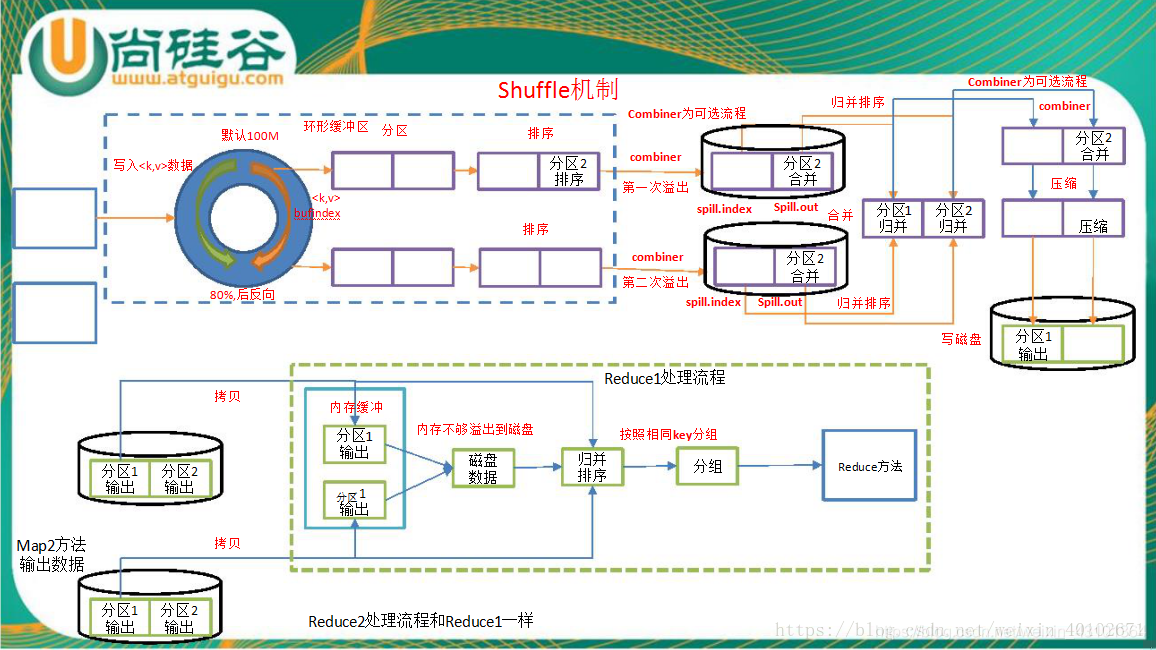
- 写入之前先进行分区Partition(Collect )
- 默认分区
对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理 - 自定义分区
继承Partitioner类,然后定制到job上
-
写入缓冲区(Spill)
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存—>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
溢写spill线程启动后,开始对key进行排序(Sort)默认的是自然排序,也是对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序)。 -
Combiner (可选)
相当于map阶段的reduce,将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量(Combiner使用一定得慎重,适用于输入key/value和输出key/value类型完全一致,而且不影响最终的结果) -
Merge(合并成一个文件)
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做Merge,最终结果就是一个group({“aaa”,[5,8,3]})。集合里面的值是从不同的溢写文件中读取来的。这时候Map-Shuffle就算是完成了。
一个MapTask端生成一个结果文件。
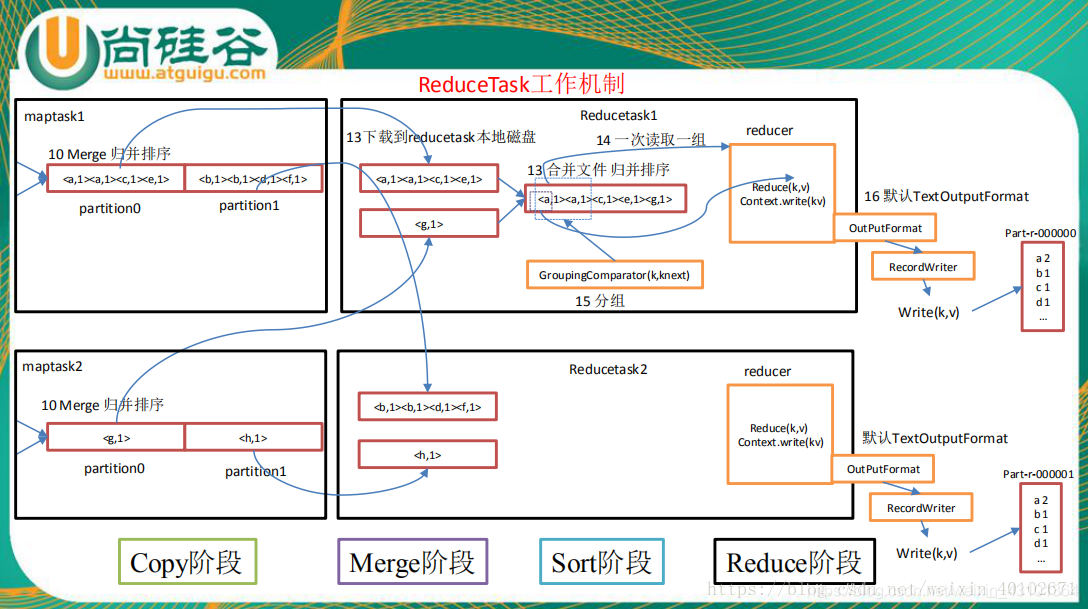
ReduceTask
Reduce-Shuffle
-
Copy(复制MapTask的数据)
当MapTask完成任务数超过总数的5%后,开始调度执行ReduceTask任务,然后ReduceTask默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。 -
Spill(溢出)
将复制的数据先保存在内存缓冲区中,当达到一定阈值的时候,开始从内存到磁盘,一直运行到map端没有数据生成。 -
Merge-Reduce(合并)
将2中生成的文件合并成最终的文件,
所谓Reduce端的sort过程就是这个合并的过程,采取的排序方法跟map阶段不同,因为每个map端传过来的数据是排好序的,因此众多排好序的map输出文件在reduce端进行合并时采用的是归并排序,针对键进行归并排序。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
然后就开始reduceTask就会将这个文件交给reduced()方法进行处理,执行相应的业务逻辑。
OutputFormat
默认输出到HDFS上,文件名称是part-00001
当我们输出需要指定到不同于HDFS时,需要自定义输出类继承OutputFormat类
hadoop一个节点默认起两个map slot,这两个slot是多线程吗?
综合上面看, slots 只是一个逻辑值 ( org.apache.hadoop.mapred.TaskTracker.TaskLauncher.numFreeSlots ),而不是对应着一个线程或者进程。TaskLauncher 会维护这个值,以保证资源使用在控制范围内。 slots 有点类似 “令牌” 的感觉:申请资源,先获得令牌;释放资源,交还令牌。
mapper 和 reducer 都是单独的进程
作者:ASN_forever
来源:优快云
原文:https://blog.youkuaiyun.com/asn_forever/article/details/81233547
版权声明:本文为博主原创文章,转载请附上博文链接!
参考地址:
https://blog.youkuaiyun.com/weixin_40102671/article/details/80628736

















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









