






EAGLE v2 前向推理 流程分析
论文链接:EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
代码链接:EAGLE-2
前向推理的接口函数:EaModel.eagenerate(),该函数内经过一系列 kv cache、tree_mode 等初始化操作后,调用函数utils.initialize_tree() 执行前向推理(prefill+decode),生成的 draft token 经过 base model 的一次前向推理,调用utils.evaluate_posterior() 决定是否接受,utils.update_inference_inputs 函数对于接受的tokens进行拼接等后处理。
流程分析
| 步骤 | 代码位置 | inputs |
|---|---|---|
| base model forward | eagle/model/utils.py initialize_tree() | |
| draft model forward | eagle/model/cnets.py topK_generate() | hidden_states(仅上一轮输出,维度 [bs, 8, 4096]) input_ids(仅上一轮输出,维度 [bs, 8]) past_key_values attention_mask=None position_ids(e.g. [173, 173, 173, 173, 173, 173, 173, 173]) |
| base model verification | eagle/model/utils.py tree_decoding() | tree_candidates(维度 [1, 60]) past_key_values(不包含draft token信息) input_ids tree_position_ids(维度 [60]) retrieve_indices (tree_mask不作为forward参数传递) |
draft model forward流程:
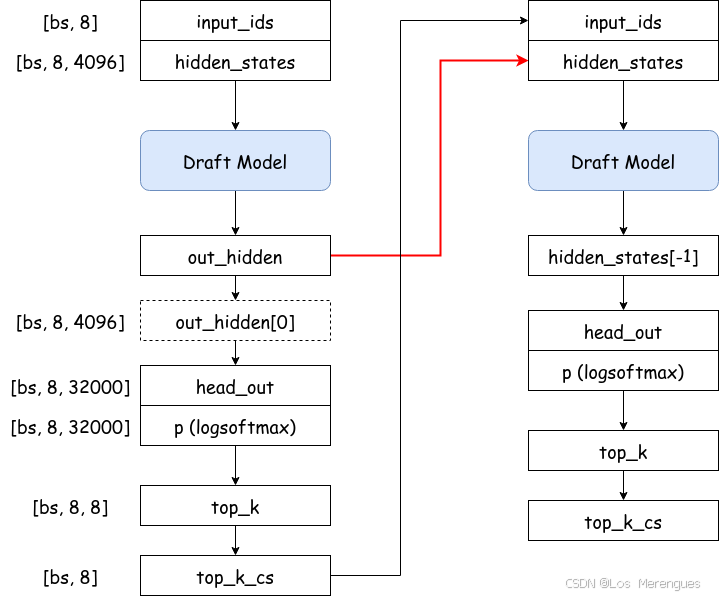
hidden_state传递示意
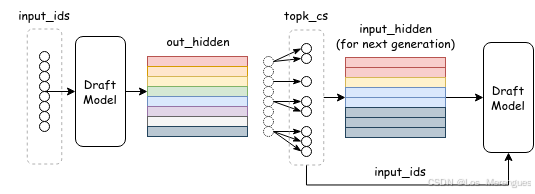
代码分析
initialize_tree()
该函数执行一次 base model 的前向推理(prefill),保留得分最高的 token 拼接到 input_ids 中;
调用 cnets.Model.topK_generate() 执行 decode 阶段后续推理
def initialize_tree(input_ids, model, past_key_values, logits_processor):
# base model forward once
outputs, orig, hidden_states = model(input_ids, past_key_values=past_key_values, output_orig=True)
print(f'input_ids={input_ids.shape}')
# select top-1 token
if logits_processor is not None:
logits = orig[:, -1]
logits = logits_processor(None, logits)
probabilities = torch.nn.functional.softmax(logits, dim=1)
token = torch.multinomial(probabilities, 1)
else:
token = torch.argmax(orig[:, -1])
token = token[None, None]
# cat input_ids with 1st token
input_ids = torch.cat((input_ids, token.to(input_ids.device)), dim=1)
draft_tokens, retrieve_indices,tree_mask,tree_position_ids = model.ea_layer.topK_genrate(hidden_states, input_ids, model.base_model.lm_head, logits_processor)
return draft_tokens, retrieve_indices,tree_mask,tree_position_ids, orig, hidden_states, token
topK_generate()
该函数先执行一次 base model 的前向推理,保留置信度最高的 top-k 个 token;
再执行 depth 次 draft model 的前向推理,每次都保留 top-k 个 token 拼接到 input_ids 中作为下一轮输入;depth次推理结束后,会得到一个包含 top-k + depth * top-k * top-k 个节点的 draft tree,再从中筛选 top-total_tokens 个 token 作为本轮前向推理的最终 draft token 输出;
对于 top-total_tokens 个 draft token 进行后续处理,整理其祖先节点并生成 tree_mask,根据从属关系构建所有可能的路径,存储在变量 retrieve_indices 中,维度 [ leaf_num, max_depth ];
@torch.no_grad()
def topK_genrate(self, hidden_states, input_ids, head, logits_processor):
input_ids = input_ids.to(hidden_states.device)
total_tokens = self.total_tokens
depth = self.depth
top_k = self.top_k
sample_token = input_ids[:, -1]
scores_list = []
parents_list = []
ss_token = []
input_ids = input_ids[:, 1:]
input_ids = input_ids.to(hidden_states.device)
len_posi = input_ids.shape[1]
self.reset()
# base model docode
if hasattr(self, "stable_kv") and self.stable_kv is not None:
kv_len = self.stable_kv[0][0].shape[2]
out_hidden, past_key_values = self(hidden_states, input_ids=input_ids[:, kv_len:],
past_key_values=self.stable_kv, use_cache=True)
else:
out_hidden, past_key_values = self(hidden_states, input_ids=input_ids, use_cache=True)
self.stable_kv = past_key_values
last_hidden = out_hidden[:, -1]
last_headout = head(last_hidden)
last_p = self.logsoftmax(last_headout)
top = torch.topk(last_p, top_k, dim=-1) # 当前轮次输出中 保留k个得分最高的token
topk_index, topk_p = top.indices, top.values
scores = topk_p[0]
scores_list.append(scores[None]) # 存储得分
parents_list.append(torch.zeros(1, dtype=torch.long, device=scores.device)) # 存储父节点index
ss_token.append(topk_index) # 存储top-k token的index
# 准备下一轮decode
input_ids = topk_index
input_hidden = last_hidden[None].repeat(1, top_k, 1)
tree_mask = self.tree_mask_init
topk_cs_index = torch.arange(top_k, device=self.embed_tokens.weight.device)
# draft model decode
for i in range(depth):
self.tree_mask = tree_mask
position_ids = len_posi + self.position_ids
# draft model forward
out_hidden, past_key_values = self(input_hidden, input_ids=input_ids, past_key_values=past_key_values, position_ids=position_ids, use_cache=True)
len_posi += 1
# 计算 parent node index
bias1 = top_k if i > 0 else 0
bias2 = max(0, i - 1)
bias = 1 + top_k ** 2 * bias2 + bias1
parents = (topk_cs_index + bias)
parents_list.append(parents)
last_headout = head(out_hidden[0])
last_p = self.logsoftmax(last_headout)
# 上一轮最终top_k个token的输出,都按照置信度保存top-k个token [top_k, top_k]
top = torch.topk(last_p, top_k, dim=-1)
topk_index, topk_p = top.indices, top.values
# 置信度处理后保留top-k个token,用于下一轮推理 [top_k]
cu_scores = topk_p + scores[:, None] # 与父节点得分相加
topk_cs = torch.topk(cu_scores.view(-1), top_k, dim=-1)
topk_cs_index, topk_cs_p = topk_cs.indices, topk_cs.values
scores = topk_cs_p
out_ids = topk_cs_index // top_k
input_hidden = out_hidden[:, out_ids]
input_ids = topk_index.view(-1)[topk_cs_index][None] # [top_k]
ss_token.append(topk_index)
scores_list.append(cu_scores) # [top_k, top_k]
tree_mask = torch.cat((tree_mask[:, :, out_ids], self.tree_mask_init), dim=3)
# tree里的节点数:top_k + top_k * top_k * 5 = 328
scores_list = torch.cat(scores_list, dim=0).view(-1)
ss_token_list = torch.cat(ss_token, dim=0).view(-1)
# 整个tree中保留Top-total_tokens(60)个节点
top_scores = torch.topk(scores_list, total_tokens, dim=-1)
top_scores_index = top_scores.indices
top_scores_index = torch.sort(top_scores_index).values
# decide the final draft tokens (Top-total_tokens)
draft_tokens = ss_token_list[top_scores_index] # 最终 draft token
draft_tokens = torch.cat((sample_token, draft_tokens), dim=0) # input + draft-token-generated
draft_parents = torch.cat(parents_list, dim=0)[top_scores_index // top_k].long() # 找到Top-60的父节点index
mask_index = torch.searchsorted(top_scores_index, draft_parents - 1, right=False) # 根据父节点位置生成mask,确保只能看到祖先节点
mask_index[draft_parents == 0] = -1
mask_index = mask_index + 1
mask_index_list = mask_index.tolist()
tree_mask = torch.eye(total_tokens + 1).bool() # 对角线 True
tree_mask[:, 0] = True # 都能看到 preflil 生成的第一个 token
# 遍历所有保留的Top-60 tokens,把他和他的父节点mask进行合并
# 由于mask_index_list中节点按照index顺序排列,因此能够保证每个Token看到其所有的祖先节点
for i in range(total_tokens):
tree_mask[i + 1].add_(tree_mask[mask_index_list[i]]) # 和其他行相加(保留true)
tree_position_ids = torch.sum(tree_mask, dim=1) - 1
tree_mask = tree_mask.float()[None, None]
draft_tokens = draft_tokens[None]
del parents_list, scores_list, ss_token, ss_token_list, draft_parents
max_depth = torch.max(tree_position_ids) + 1
noleaf_index = torch.unique(mask_index).tolist() # 父节点数量(能够成为父节点说明他不是叶子节点)
noleaf_num = len(noleaf_index) - 1
leaf_num = total_tokens - noleaf_num # 叶子节点数量(路径结束) => 决定了Top-60 tokens中存在多少条路径
# 存储路径
retrieve_indices = torch.zeros(leaf_num, max_depth.item(), dtype=torch.long) - 1
retrieve_indices = retrieve_indices.tolist()
rid = 0
position_ids_list = tree_position_ids.tolist()
# 根据父节点和祖先节点的 mask 关系构建路径
for i in range(total_tokens + 1):
if i not in noleaf_index: # 遍历叶子节点
cid = i
depth = position_ids_list[i]
for j in reversed(range(depth + 1)): # 从叶子结点回溯 depth
retrieve_indices[rid][j] = cid
cid = mask_index_list[cid - 1]
rid += 1 # 一条路径遍历结束,下一行记录一条新路径
if logits_processor is not None:
maxitem = total_tokens + 5
def custom_sort(lst):
sort_keys = []
for i in range(len(lst)):
sort_keys.append(lst[i] if lst[i] >= 0 else maxitem)
return sort_keys
retrieve_indices = sorted(retrieve_indices, key=custom_sort)
retrieve_indices = torch.tensor(retrieve_indices, dtype=torch.long)
del mask_index, mask_index_list, noleaf_index, noleaf_num, leaf_num, max_depth, rid
tree_position_ids = tree_position_ids.to(hidden_states.device)
return draft_tokens, retrieve_indices, tree_mask, tree_position_ids
tree_decoding
def tree_decoding(
model,
tree_candidates, # input_ids + draft token
past_key_values,
tree_position_ids,
input_ids,
retrieve_indices,
):
position_ids = tree_position_ids + input_ids.shape[1]
# base model forward
outputs, tree_logits, hidden_state = model(
tree_candidates,
output_orig=True,
past_key_values=past_key_values,
position_ids=position_ids,
)
logits = tree_logits[0, retrieve_indices] # 路径上每个元素的词表概率分布 维度 [leaf_num, max_depth, 32000]
return logits, hidden_state, outputs
evaluate_posterior()
只在 draft token 恰好为 base model 在该位置概率最大的 token 时 accept,否则都被拒绝,结果保存在 posterior_mask 中;
统计 posterior_mask 每行从左至右最长连续1的数量即为该路径的 accept_length;
def evaluate_posterior(
logits: torch.Tensor, # 路径上的概率分布
candidates: torch.Tensor, # draft model 生成的token路径
logits_processor, # 筛选参数
):
if logits_processor is None:
# 该位置的draft token恰好为base model输出分布中概率最大的token
posterior_mask = (candidates[:, 1:].to(logits.device) == torch.argmax(logits[:, :-1], dim=-1)).int()
candidates_accept_length = (torch.cumprod(posterior_mask, dim=1)).sum(dim=1)
accept_length = candidates_accept_length.max()
# Choose the best candidate
if accept_length == 0:
# Default to the first candidate if none are accepted
best_candidate = torch.tensor(0, dtype=torch.long, device=candidates.device)
else:
best_candidate = torch.argmax(candidates_accept_length).to(torch.long)
return best_candidate, accept_length, logits[best_candidate, accept_length]

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









