









学习目标
掌握集成学习中bagging 、随机森林、决策树算法的推导过程以及实现方法
1.bagging
上一篇中提到,按照基学习器的组合方式,集成学习可以划分为boosting 和 bagging 两种形式,boosting的基本原理和使用方法详见上一篇
1.1 基本原理
bagging 和 boosting 不同12,它按照并行的方式组合基学习器,各个基学习器学习和训练的过程是独立的。在组合基学习器时采用了平均的决策策略(如投票法、平均法等)
为了强调基学习器的多样性,使得基学习器好而不同,bagging采用了自助采样法(bootstrap sampling)来获取数据
因此,可以总结出Bagging 和 Boosting 的不同;
1.基分类器的组合策略不同(并行 or 串行)
2.强分类器的决策策略不同(平均 or 加权求和)
3.基分类器数据的采样方法不同 (自助采样法 or 仅打乱采样数据的分布)
《机器学习》一书中提到,boosting和bagging还有一点不同在于:boosting 侧重于降低偏差, bagging 侧重于降低方差
一开始没有太理解bagging 是如何降低方差的,之后查阅资料3:
以平均法求最终的预测值为例
E ( x ) E(x) E(x)= E ( 1 n ∑ i n X i ) E(\frac{1}{n}\sum _i^nX_i) E(n1∑inXi)= 1 n ∗ n ∗ E ( X i ) = u \frac{1}{n}*n*E(X_i)=u n1∗n∗E(Xi)=u
强学习器的期望近似于单个基学习器的期望
D ( x ) D(x) D(x)=D( 1 n ∑ i n X i \frac{1}{n}\sum _i^nX_i n1∑inXi)= 1 n 2 \frac{1}{n^2} n21D( ∑ i n X i \sum _i^nX_i ∑inXi)= 1 n \frac{1}{n} n1 σ 2 σ^2 σ2(在样本独立分布的情况下)
因为bagging中的基学习器不是独立同分布的,随机采样后存在相互交叠的样本,所以并不满足独立性假设
因此,其方差可以表示为 (其中 0 < p < 1 0<p<1 0<p<1):
D ( x ) D(x) D(x)= σ 2 n + n − 1 n ∗ p ∗ σ 2 \frac{σ^2}{n}+\frac{n-1}{n}*p*σ^2 nσ2+nn−1∗p∗σ2
当 n(基学习器数目)比较大时,上式趋近于 p σ 2 pσ^2 pσ2,相当于对基原学习器的方差进行了缩小
1.2 自助采样法
对于数据集 D D D,我们每次随机抽取一个样本 D i D_i Di( D i D_i Di ∈ D \in D ∈D ),将其加入基学习器 L i L_i Li的训练数据集,之后将其放回至数据集 D D D。若训练集的集合为 D t D_t Dt={ D 1 , D 2 , D 3 . . {D_1,D_2,D_3..} D1,D2,D3..},最终测试集为 D / D t D/D_t D/Dt
从上看出,自助采样法是一种有放回的采样方式。
这种采样方法肯定会造成训练数据中有一部分重叠,那么为什么要选择这种采样方法呢?
1.对于小样本数据而言,如果每个基分类器的训练数据都是不同的,相当于每个分类器都只学到了一小部分数据,这样无法保证基学习器的有效性
2.与交叉验证相比,自助采样法更适合小样本数据
3.与留出法相比,自主采样法避免了小样本无法很好的选择出有代表性的训练样本的缺陷
设采样次数为m,则某样本经过m次都没有被采到的概率为
(
1
−
1
m
)
m
(1-\frac{1}{m})^m
(1−m1)m
对m取极限可以得到;
l i m ( ( 1 − 1 m ) m ) ) = 1 e = 0.368 lim ((1-\frac{1}{m})^m))=\frac {1}{e}=0.368 lim((1−m1)m))=e1=0.368
也就是说数据集中有36.8%的数据没有被采到,可以看作是测试集,对模型的泛化性能进行包外估计
1.3 基分类器——决策树
实验中将决策树作为了基分类器,决策树 顾名思义是一个树状结构,其节点 按照 一定的规则 进行划分(这个规则主要包括信息增益、基尼系数和信息增益率的大小)
1.3.1 信息熵
在分类时,我们侧重于选择 包含的样本类别不是很多 的特征进行划分,这样会加快建树的速度。
用纯度这个概念可以比较贴切的来描述被选特征:包含样本类别不是很多的特征,它的纯度高;相反,纯度低。
信息熵就是用来形容纯度高低的变量:
信息熵高,样本比较混乱,纯度低
信息熵低,样本混乱度低,纯度高
建树过程中,我们会优先选择信息熵低的特征作为划分特征
信息熵= − ∑ k V p k ∗ l o g 2 ( p k ) -\sum_k^V p_k*log_2(p_k) −∑kVpk∗log2(pk)
其中, p k p_k pk为第 k k k类样本的出现概率
1.3.2 信息增益
信息增益 G a i n Gain Gain是用来描述信息熵下降程度的变量
设当前以特征V作为划分特征,则
G a i n = E n t 1 − ∑ v V ( ∣ D v ∣ ∣ D ∣ ∗ E n t v ) Gain=Ent_1-\sum_v^V(\frac{|D_v|}{|D|}*Ent_v) Gain=Ent1−∑vV(∣D∣∣Dv∣∗Entv)
上面提到,在建树过程中,我们会优先选择信息熵较低的特征,也就是选择信息增益最大的特征
以《机器学习》中的西瓜数据集为例:
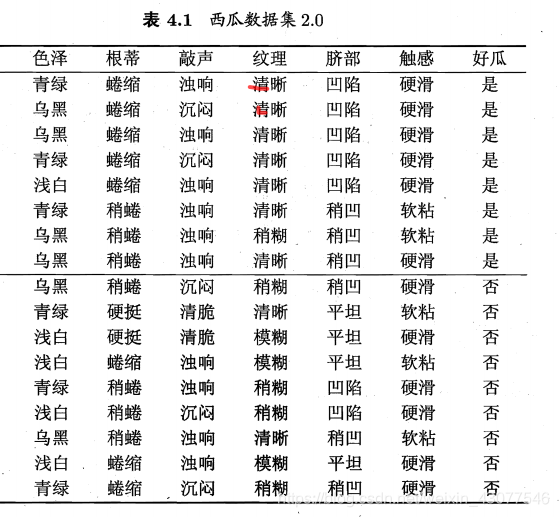
以色泽为例,
v
∈
v \in
v∈{青绿、乌黑、浅白}
∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (青绿)= 6 17 \frac{6}{17} 176* ( − 3 6 ∗ l o g 2 3 6 − 3 6 ∗ l o g 2 3 6 ) (-\frac{3}{6}*log_2\frac{3}{6}-\frac{3}{6}*log_2\frac{3}{6}) (−63∗log263−63∗log263)= 6 17 \frac{6}{17} 176
∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (乌黑)= 6 17 \frac{6}{17} 176* ( − 4 6 ∗ l o g 2 4 6 − 2 6 ∗ l o g 2 2 6 ) (-\frac{4}{6}*log_2\frac{4}{6}-\frac{2}{6}*log_2\frac{2}{6}) (−64∗log264−62∗log262)=0.918 * 6 17 \frac{6}{17} 176
∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (浅白)= 5 17 \frac{5}{17} 175* ( − 1 5 ∗ l o g 2 1 5 − 4 5 ∗ l o g 2 4 5 ) (-\frac{1}{5}*log_2\frac{1}{5}-\frac{4}{5}*log_2\frac{4}{5}) (−51∗log251−54∗log254)=0.722 * 5 17 \frac{5}{17} 175
E n t 1 Ent_1 Ent1= − 8 17 ∗ l o g 2 ( 8 17 ) − 9 17 ∗ l o g 2 ( 9 17 ) -\frac{8}{17}*log_2(\frac{8}{17})-\frac{9}{17}*log_2(\frac{9}{17}) −178∗log2(178)−179∗log2(179)
G a i n Gain Gain= E n t 1 Ent_1 Ent1-( ∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (青绿)+ ∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (乌黑)+ ∣ D v ∣ ∣ D ∣ \frac{|D_v|}{|D|} ∣D∣∣Dv∣Ent (浅白))
带入计算即可
1.3.3 基尼系数
基尼系数是描述两个样本不同属于一类事件的发生概率
g i n i ( D ) gini(D) gini(D)= ∑ i ∣ y ∣ p i ∑ j ≠ i p j \sum_i^{|y|}p_i\sum_{j\neq i}p_j ∑i∣y∣pi∑j=ipj
= ∑ i ∣ y ∣ p i ( 1 − p i ) \sum_i^{|y|}p_i(1-p_i) ∑i∣y∣pi(1−pi)
基尼指数定义为:
g i n i n d e x ( D ) ginindex(D) ginindex(D)= ∣ D v ∣ ∣ D ∣ \frac {|D_v|}{|D|} ∣D∣∣Dv∣ ∑ i ∣ y ∣ p i ( 1 − p i ) \sum_i^{|y|}p_i(1-p_i) ∑i∣y∣pi(1−pi)
同理,在建树的时候优先选择基尼指数小
1.3.4 决策树实战
1.求解信息熵
def Ent(data):#求解信息熵
count_label={}#用于记录每个标签的个数
length=len(data)
for i in range(0,length):
item=data.iloc[i,-1]
if item not in count_label.keys():#如果说标签不在label_count里面,就将其加入,相当于是初始化操作
count_label[item]=0
count_label[item]+=1
ent=0.0
for value in count_label.values():
p=value/length
ent+=-p*np.log2(p)
return ent
2.求解信息增益
#计算信息增益
def gain(data,column):
ent2=data.groupby(column).apply(lambda x:(len(x)/len(data))*Ent(x)).sum()
ent1=Ent(data)
return ent1-ent2
寻找第一层的特征时,各个备选特征的信息增益如下:
print('色泽:',gain(data,'色泽'))
print('根蒂:',gain(data,'根蒂'))
print('纹理:',gain(data,'纹理'))
print('触感:',gain(data,'触感'))
print('敲声:',gain(data,'敲声'))
#色泽: 0.10812516526536531
#根蒂: 0.14267495956679288
#纹理: 0.3805918973682686
#触感: 0.006046489176565584
#敲声: 0.14078143361499584
3.建树 4
伪代码:

def buildtree(data):
label=data.iloc[:,-1]#标签
feature=data.columns[:-1]#特征
if len(np.unique(label))==1: ##如果D中样本全部属于一类,则将其看作叶节点
return data.iloc[0,-1]#返回叶节点的值
if len(feature)==0 or len(data.loc[:,feature].drop_duplicates())==1:#如果说没有可以分割的特征了,或者说特征的标签都是相同的
return Counter(label).most_common(1)[0][0] #返回数目最多的那个特征,将其作为叶节点
best_column=get_max_gain(data) #获得信息增益最大的特征
tree={best_column:{}}
for col,gb_data in data.groupby(by=best_column):
if len(gb_data) == 0:
tree[best_attr][col] = Counter(label).most_common(1)[0][0]
else:
#在data中去掉已划分的属性
new_data = gb_data.drop(best_column,axis=1)
#递归构造决策树
tree[best_column][col] = buildtree(new_data)
return tree
#结果:
#{'纹理': {'模糊': '否',
# '清晰': {'根蒂': {'硬挺': '否',
# '稍蜷': {'色泽': {'乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}, '青绿': '是'}},
# '蜷缩': '是'}},
# '稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}}}
1.4 随机森林
随机森林是bagging的扩展变体
bagging的基学习器一般是决策树,而决策树是在样本中的所有特征中选择一个最佳的分割特征
而随机森林是在当前样本所有的特征中首先随机挑选
k
k
k个特征,其次再从这
k
k
k个特征中选择一个最佳的分割特征
可以说,RF在原有bagging的基础上增加了特征选择的随机性。原本bagging的多样性仅来自样本扰动,RF在此基础上增加了属性扰动
k
=
1
k=1
k=1时,相当于在特征集合中随机选择一个特征
k
=
d
k=d
k=d时,相当于传统的决策树,通过计算在特征集合选择一个特征
一般k取
l
o
g
2
d
log_2d
log2d
RF在很多现实任务中展现出强大的性能,被誉为"代表集成学习技术水平的方法"
一般学习器较多时,RF要强于bagging
1.4 bagging 实战
- 自助采样
#自助采样
class bootstrapsample():
def __init__(self,n_samples):#一共要采样几次
self.n_samples=n_samples
def sampling(self,length,nonindex):#对其进行采样
index=[]
for i in range(self.n_samples):
number=int(np.random.randint(0,length-1,1))
index.append(number)
if number in nonindex:
nonindex.remove(number) #nonindex 用于记录测试集的下标
return index,nonindex
2.基分类器进行预测
def predict(data,tree):
feature=list(tree.keys())[0]
label=data[feature]
iter_tree=tree[feature][label]
if type(iter_tree)==str:
return iter_tree
else:
return predict(data,iter_tree)
3.采用投票法选择最终预测结果
def vote(predict_label,weakClassifier):
x=list(predict_label.keys())
result=[]
for i in range(0,len(predict_label[x[0]])):
y=[]
for j in x:
y.append(predict_label[j][i])
result.append(Counter(y).most_common(1)[0][0])
return result
4.计算准确率
def caculate(list1,list2):
sum_error=0
for i in range(0,len(list1)):
if list1[i]!=list2[i]:
sum_error+=1
return sum_error/len(list1)
5.利用随机采样法获取训练集与数据集
data=pd.read_excel('watermelon20.xlsx')
sample=bootstrapsample(10)#每次采10个样本
nonindex=list(np.arange(0,len(data)))
sample_number=3#使用3个基分类器
X_train,Y_train={},{}
for i in range(sample_number):
index,nonindex=sample.sampling(len(data),nonindex)#对其进行采样
X_train[i],Y_train[i]=data.iloc[index,1:-1],data.iloc[index,-1]
X_test,Y_test=data.iloc[nonindex,1:-1],data.iloc[nonindex,-1]
6.训练基分类器
weakClassifier=[]
for i in range(sample_number):
train=pd.concat([X_train[i],Y_train[i]],axis=1)
tree=buildtree(train)
weakClassifier.append(tree)
7.获得每个基分类器的预测序列
predict_label={}
for i in range(0,len(weakClassifier)):
predict_label[i]=list(X_test.apply(lambda x:predict(x,weakClassifier[i]),axis=1))
8.采用投票法获得最终的标记序列,并计算错误率
predict_label=vote(predict_label,weakClassifier)
error_rate=caculate(list(Y_test),predict_label)
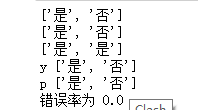
print('y',list(Y_test))
print('p',predict_label)
print('错误率为',error_rate)
最终结果如下('y’是真实标签,'p‘是预测标签):

















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









