






循环神经网络
-
RNN :循环神经网络,处理的是后续的输出与之前的内容有关联的任务。
-
RNN引入“记忆”的概念
-
“循环”2字来源于其每个源于都执行相同的任务,但是输出依赖于输入和“记忆”。NMT: neural machine translation
一.场景与多种应用:模仿生成论文(生成序列)
二.层级结构
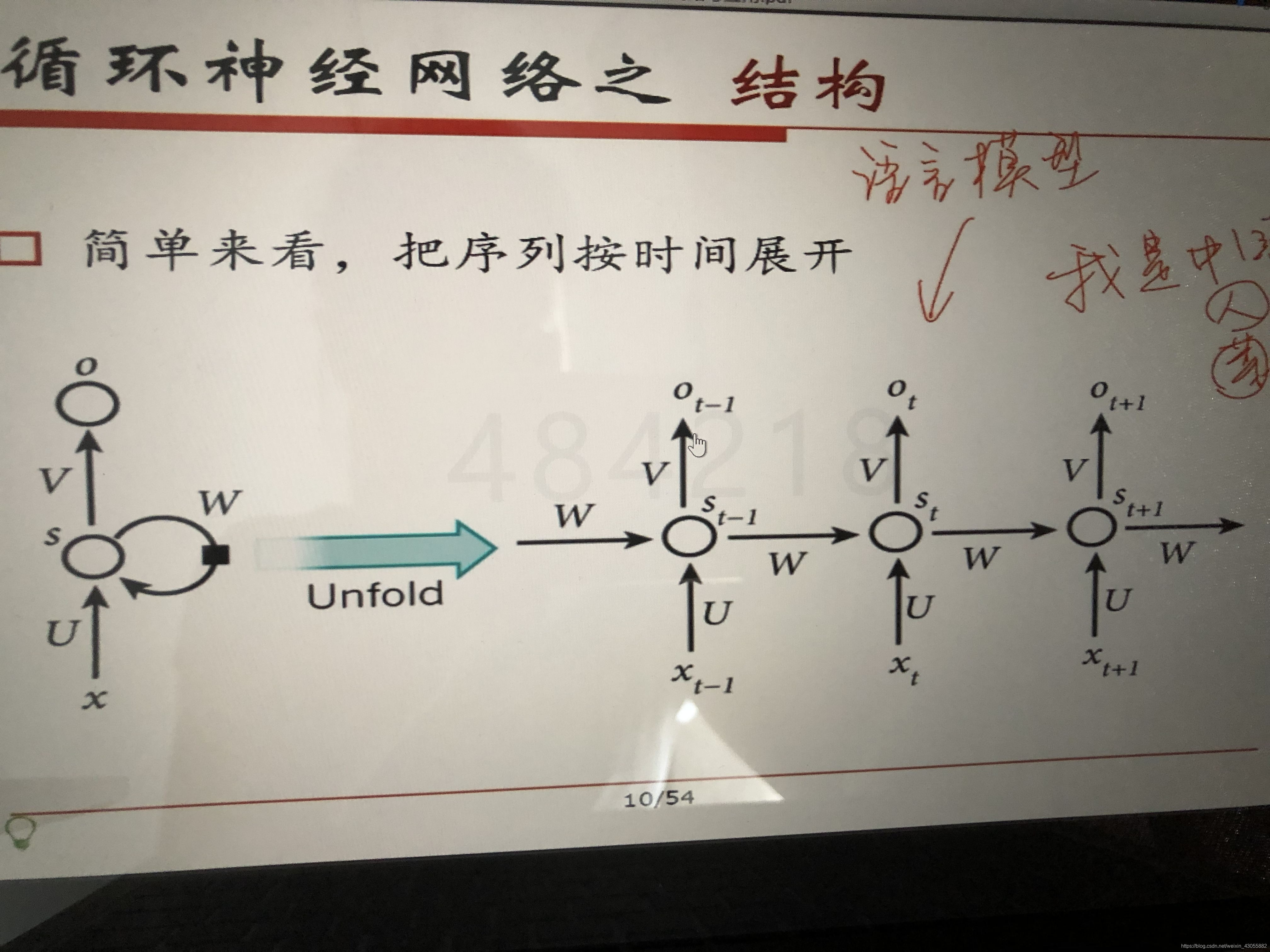
- xtx_{t}xt是时间ttt处 的输入
- StS_tSt是时间ttt处的“记忆”,St=f(UXt+WSt−1)S_t=f(UX_t+WS_{t-1})St=f(UXt+WSt−1), fff可以是tanhtanhtanh等
- OtO_tOt是时间ttt处的输出,如果是预测下个词的话,可能是softmaxsoftmaxsoftmax输出的属于每个候选词的概率,Ot=softmax(VSt)O_t=softmax(VS_t)Ot=softmax(VSt)
WWW 和UUU是参数的矩阵
- 参数复用:每个时间点上用的UUU,VVV,WWW都是同一个参数
- OtO_tOt只与StS_tSt有关系
结构细节: - 1.可以把因状态StS_tSt视作“记忆体”,捕捉了之前时间点上的信息;
- 2.输出OtO_tOt由当前时间及之前所有的“记忆”共同计算得到;
- 3.实际应用中,StS_tSt并不能捕捉和保留之前所有的信息;
- 4.不同于CNN,这里的RNN其实整个神经网络都共享一组参数(WWW,UUU,VVV),极大减小了需要训练和预估的参数量;
- 5.图中的OtO_tOt在有些任务下是不存在的,比如文本情感分析,其实只需要最后的output结果就行。
三.多种RNN
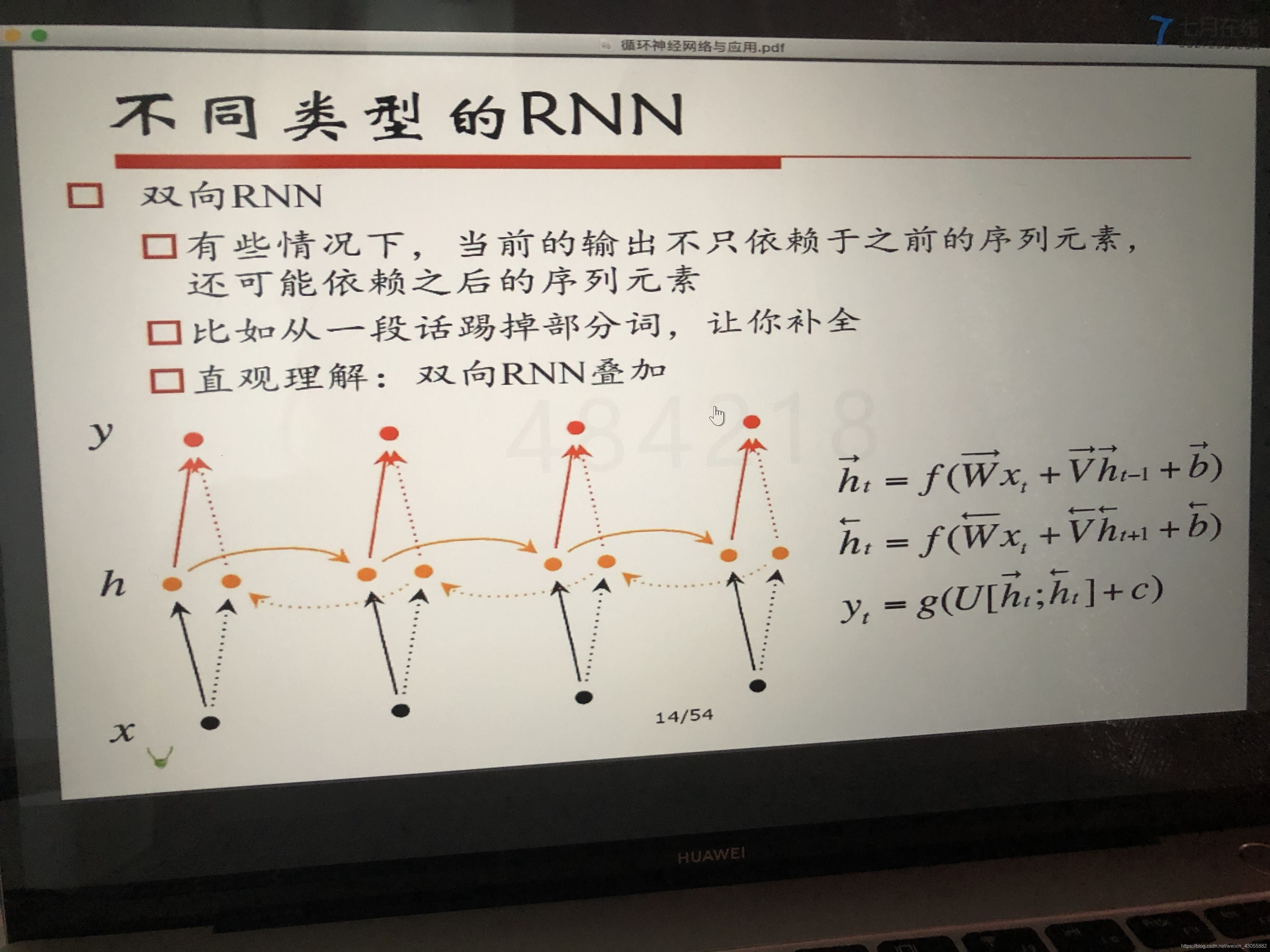
双向RNN:1.有些情况下,当前的输出不只依赖于之前的序列元素,还可能依赖之后的序列元素。比如从一段话踢掉部分词,让你补全。
直观理解:双向RNN叠加
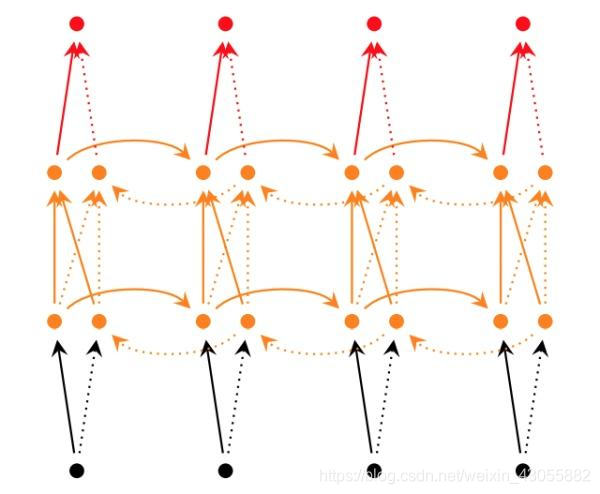
深层双向RNN和双向RNN的区别是每一步/每个时间点我们设定多层结构
4.BPTT算法
MLP(DNN)与CNN用BP算法求偏导
BPTT和BP是一个思路,不过既然有step,就和时间t有关系
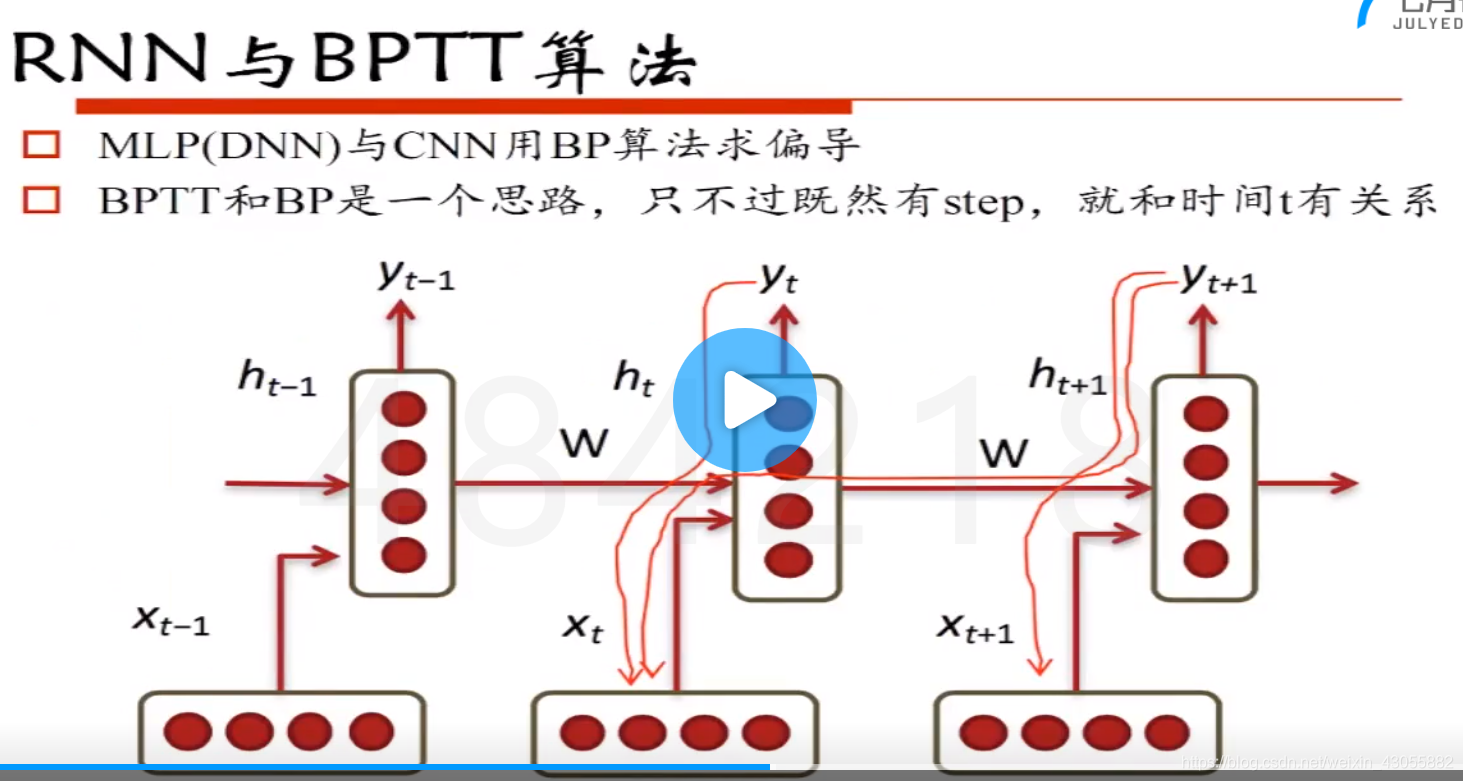
1:16:12处
5.生成模型与图像描述
LSTM
1.长时依赖问题
(Long short-term Memory)
LSTM 是RNN的一种,大体结构几乎一样,区别是:1.它的“记忆细胞”被改造过;2.该记的信息会一直传递,不该记的会被“门”截断。
LSTM关键:“细胞状态”
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易
LSTM怎么控制“细胞状态”
通过“门”让信息选择性通过,来去除或者增加信息到细胞状态
包含一个sigmoid神经网络曾和一个pointwise乘法操作
sigmoid层输出0到1之间的概率值,描述每个部分有多少量可以通过。0代表“不允许任何量通过”,1就指“允许任何量通过”
LSTM的几个关键“门”与操作
第一步:决定从“细胞状态”中丢弃什么信息 =→=\rightarrow=→ “忘记门”
ft=δ(Wt.[ht−1,xt]+bf)f_t=\delta(W_t.[h_{t-1},x_t]+b_f)ft=δ(Wt.[ht−1,xt]+bf)
第二步:决定放什么新信息到“细胞状态”中
SigmoidSigmoidSigmoid 层决定什么值需要更新
TanhTanhTanh层创建一个新的候选值向量Ct^\hat{C_t}Ct^
上述2步是为状态更新做准备
it=δ(Wi.[Ht−1,xt]+bi)i_t=\delta(W_i.[H_{t-1},x_t]+b_i)it=δ(Wi.[Ht−1,xt]+bi)
Ct^=tanh(Wc.[ht−1,xt]+bC)\hat{C_t}=tanh(W_c.[h_{t-1},x_t]+bC)Ct^=tanh(Wc.[ht−1,xt]+bC)
第三步:更新“细胞状态”
1.更新Ct−1C_{t-1}Ct−1为CtC_tCt
2.把旧状态与ftf_tft 相乘,丢弃掉我们确定需要丢弃的信息
3.加上it∗Ct^i_t*\hat{C_t}it∗Ct^ 。这就是新的候选值,根据我们决定更新每个状态的程度进行变化
第四步:基于“细胞状态”得到输出
1.首先运行一个sigmoid层来确定细胞状态的哪个部分得到输出
2.接着用tanh处理细胞状态(得到一个在-1到1之间的值),再将它和sigmoid门的输出相乘,输出我们确定要输出的那部分。
3.比如我们可能需要单复数信息来确定输出“他”还是“他们”。
Ot=δ(Wo[ht−1,xt],bo)O_t=\delta (W_o[h_{t-1},x_t],b_o)Ot=δ(Wo[ht−1,xt],bo)
ht=Ot∗tanh(Ct)h_t=O_t*tanh(C_t)ht=Ot∗tanh(Ct)
LSTM相较于RNN会较少猪队友的影响,本质是前者求导是加法方式,后者是乘法方式。
变种1:
- 增加“peephole connection”
- 让门层也会接受细胞状态的输入
变种2:
- 通过使用coupled忘记和输入门
- 之前是分开确定需要忘记和添加的信息,这里是一同做出决定。
Ct=ft∗Ct−1+(1−ft)∗Ct^C_t=f_t*C_{t-1}+(1-f_t)*\hat{C_t}Ct=ft∗Ct−1+(1−ft)∗Ct^
四.GRU(Gated Recurrent Unit)
- 将忘记门和输入门合成来一个单一的更新门
- 同样还混合来细胞状态和隐藏状态,和其他一些改动
- 比标准LSTM简单
Zt=δ(Wz.[ht−1,xt])Z_t=\delta(W_z.[h_{t-1,x_t}])Zt=δ(Wz.[ht−1,xt])
rt=δ(Wr.[ht−1,xt])r_t=\delta(W_r.[h_{t-1},x_t])rt=δ(Wr.[ht−1,xt])
ht^=tanh(W.[rt∗ht−1,xt])\hat{h_t}=tanh(W.[rt*h_{t-1},x_t])ht^=tanh(W.[rt∗ht−1,xt])
ht=(1−zt)∗ht−1+zt∗yt^h_t=(1-z_t)*h_{t-1}+z_t*\hat{y_t}ht=(1−zt)∗ht−1+zt∗yt^

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









