前言
当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴。
本文主要讨论的是以公司名称或地址为主的字符串的模糊匹配。
使用编辑距离算法进行模糊匹配
进行模糊匹配的基本思路就是,计算每个字符串与目标字符串的相似度,取相似度最高的字符串作为与目标字符串的模糊匹配结果。
对于计算字符串之间的相似度,最常见的思路便是使用编辑距离算法。
下面我们有28条名称需要从数据库(390条数据)中找出最相似的名称:
| 1 2 3 4 5 6 7 8 9 |
import pandas as pd
excel = pd.ExcelFile("所有客户.xlsx")
data = excel.parse(0)
find = excel.parse(1)
display(data.head())
print(data.shape)
display(find.head())
print(find.shape)
|

编辑距离算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
一般来说,编辑距离越小,表示操作次数越少,两个字符串的相似度越大。
创建计算编辑距离的函数:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
def minDistance(word1: str, word2: str):
'编辑距离的计算函数'
n = len(word1)
m = len(word2)
# 有一个字符串为空串
if n * m == 0:
return n + m
# DP 数组
D = [[0] * (m + 1) for _ in range(n + 1)]
# 边界状态初始化
for i in range(n + 1):
D[i][0] = i
for j in range(m + 1):
D[0][j] = j
# 计算所有 DP 值
for i in range(1, n + 1):
for j in range(1, m + 1):
left = D[i - 1][j] + 1
down = D[i][j - 1] + 1
left_down = D[i - 1][j - 1]
if word1[i - 1] != word2[j - 1]:
left_down += 1
D[i][j] = min(left, down, left_down)
return D[n][m]
|
关于上述代码的解析可参考力扣题解:https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
遍历每个被查找的名称,计算它与数据库所有客户名称的编辑距离,并取编辑距离最小的客户名称:
| 1 2 3 4 5 6 7 |
result = []
for name in find.name.values:
a = data.user.apply(lambda user: minDistance(user, name))
user = data.user[a.argmin()]
result.append(user)
find["result"] = result
find
|
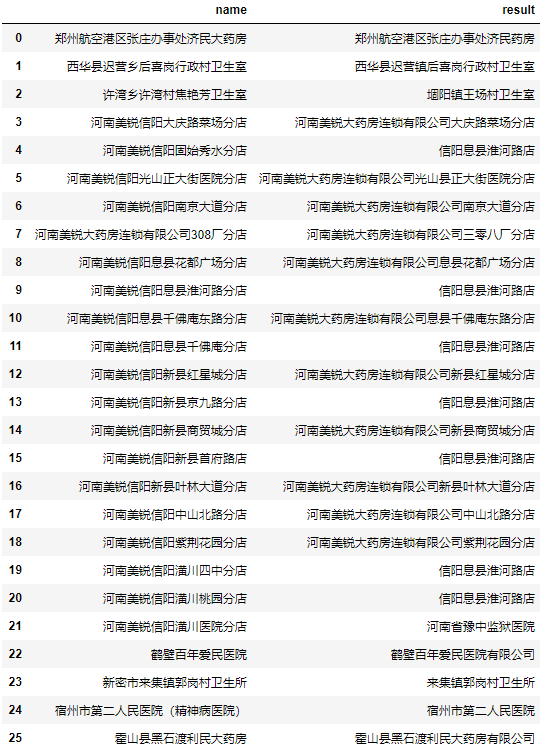
测试后发现部分地址的效果不佳。
我们任取2个结果为信阳息县淮河路店地址看看编辑距离最小的前10个地址和编辑距离:
<








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1640
1640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









