







 本文介绍了在【Datawhale】任务中,如何进行数据挖掘的初步探索,包括EDA步骤、代码示例及遇到的问题。作者强调了Pandas数据排序问题、pandas_profiling的导入错误,并分享了使用Seaborn进行数据分布分析和缺失值处理的经验。总结中提到,要关注数据的偏度和峰度,并指出Python3中分号的作用。同时,推荐了Seaborn的Pairplot用于多变量关系可视化。
本文介绍了在【Datawhale】任务中,如何进行数据挖掘的初步探索,包括EDA步骤、代码示例及遇到的问题。作者强调了Pandas数据排序问题、pandas_profiling的导入错误,并分享了使用Seaborn进行数据分布分析和缺失值处理的经验。总结中提到,要关注数据的偏度和峰度,并指出Python3中分号的作用。同时,推荐了Seaborn的Pairplot用于多变量关系可视化。
一、EDA
EDA(Exploratory Data Analysis):
也即我们常称的数据探索
是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
框架

二、task2代码-EDA
三、问题
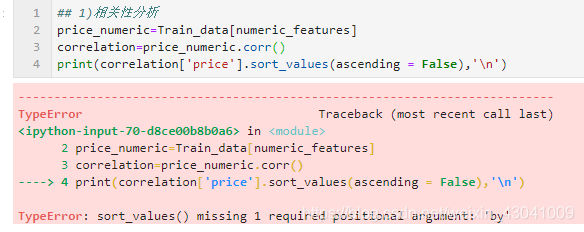
1、Pandas: TypeError: sort_values() missing 1 required positional argument: ‘by’
这个问题我还没解决,主要是需要解决相关性的数值大小排序
## 1)相关性分析
price_numeric=Train_data[numeric_features]
correlation=price_numeric.corr()
correlation
print(correlation['price'])
报错如下:
2、pandas_profiling导入出现问题,待解决
四、总结
1、同时现实数据首尾的head,利用append
Train_data.head().append(Train_data.tail())
2、缺失值可视化处理–missingno
3、在判断Train_data['price]的分布情况时,为什么用sns.distplot()?
答:需要了解一下Seaborn;
Seaborn是基于matplotlib的Python可视化库。 它提供了一个高级界面来绘制有吸引力的统计图形。Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致。
4、Python3里的“;”只是表示语句的结束,无他意。
5、关于skew、kurt的解释说明:
数据的偏度和峰度——df.skew()、df.kurt()
6、多变量之间的关系可视化文章参考
Seaborn-05-Pairplot多变量图
感受:
- 文章可视化的图很漂亮,但前提要理解这么做的含义,这一部分自身还有待加强
五、Ref.
[Datawhale 零基础入门数据挖掘-Task1 赛题理解 — By: AI蜗牛车]
知乎: https://www.zhihu.com/people/seu-aigua-niu-che
github: https://github.com/chehongshu
公众号: AI蜗牛车

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









