






7. 概率最大的路径
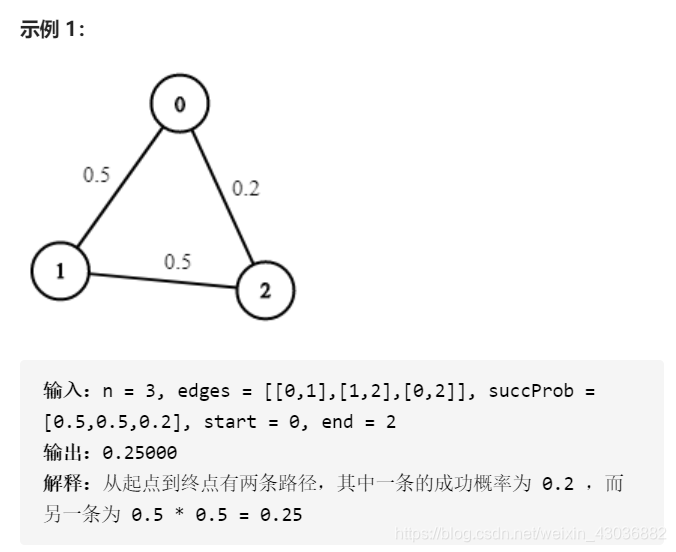
问题的解: 最大概率路径的概率,因此都不用使用向量作为解,直接给结果就可以
搜索策略: 深度优先,其实使用广度优先可能更好一点,因为每条边的概率都小于1.0,意味着路径越长概率越容易变得很小。而我们知道深度优先搜索树的深度是最大的,而广度优先得到的深度是最小的也就是路径长度更倾向于短,则得到的概率更大
约束条件: 已经搜索过的结点就不应该再次出现在路径上,不然就形成环路了。比如我们已经搜了
<
x
1
,
x
2
,
x
3
,
x
4
,
.
.
.
,
x
i
>
,
x
i
<x_1, x_2, x_3, x_4, ..., x_i>,x_i
<x1,x2,x3,x4,...,xi>,xi的邻居有三个,它们之间的边分别是0.2,0.4,0.7,那么下一次沿着哪一条路径继续搜呢?理论上来说沿着0.7继续搜得到的概率会更大。也就是说使用贪心策略,每一次搜索的时候都沿着一条概率最大的边往下走。但是这样会有一个问题,每次找最大的概率边可能路径会变得越来越长但是却搜不到目标点。而且找最大还要浪费一些时间。但是转念一想,就算不是每次找概率最大的边,也不一定能找到目标点啊。每次找概率最大的边和随机找一条边其实都还是随机的往下走,就何时能够找到目标点这个问题来说这两种方法是没有什么区别的。如果初始化时就按照边的权重大小给邻接表中的邻居排好序,那么每次找一个最大的邻居也并不费时间,最终我们是所有的邻居都要遍历的。这一段是我在写的时候突然脑子里想的过程,所以就记录了下来。
界: 目前已经得到的最优的解。这里是当前已经求得的可行解中概率最大的那个。
代价: 代价 = 目前已得到的 + 未来可能得到的最好的。在这里就是目前已经求得的路径上的概率。因为边的权值不大于1.0,所以越往后概率只会越小(因为是累乘的关系),所以未来可能得到的最大就是假设后面遇到的所有的边的权重都为1.0。因此如果这时代价都还不大于界,那可以放弃这条路径了,即剪枝。
接下来就是实现了,不过在实现之前还要对题目给的数据进行一个处理,因为我们知道图的表示方法有很多种,每一种都有各自的适用场景。这里我们使用矩阵表示法用于获得边的权重,用邻接表用于获取结点的邻居。使用了两个结构保存一个图。于是提交的时候就内存超出限制了。没关系权当熟悉数据结构了,主要是矩阵存储太浪费空间了。
想了想,改为了邻接表,但是邻接表中同时还存了边的权重信息,结构为:
v
e
x
i
:
<
<
v
e
x
j
,
w
e
i
g
h
t
>
,
<
v
e
x
k
,
w
e
i
g
h
t
>
,
<
v
e
x
l
,
w
e
i
g
h
t
>
,
.
.
.
>
vex_i:<<vex_j, weight>,<vex_k, weight>, <vex_l, weight>,...>
vexi:<<vexj,weight>,<vexk,weight>,<vexl,weight>,...>,使用一个map存储,邻居结点附带了与该结点边上的权重信息,并且按照权重大小降序排列。
代码(未经优化过的代码):
public class MaxProPath {
double maxP = 0.0;
/**
* 深度优先+分支限界搜索全图
* 界就是要求的最大路径概率值
* 代价函数f(cur) = curP * 1.0,表示将cur以后的路径概率全看成是1.0时,可以取得的最优值,显然如果该最优值小于当前已经得到的最
* 优解,那就没有必要继续搜索,该搜索子树可以剪枝了。
* @param adjacent 该图的邻接表,用于加速求某个结点的所有邻居
* @param graph 该图的带权矩阵表示法
* @param cur 当前搜到的结点,如果等于end说明搜到了一个解
* @param end 终点
* @param curP 当前的概率值
* @param visited 标记结点是否访问
* @param path 解的路径向量
*/
public void dfs(Map<Integer, List<Integer>> adjacent, double[][] graph, int cur, int end, double curP,
boolean[] visited, List<Integer> path)
{
if (cur == end) {//当搜到目标时
maxP = Math.max(maxP, curP);//最优解更新
System.out.println("end... " + maxP);
System.out.println(path);
return;
}
//从当前点cur继续搜
for (int near: adjacent.get(cur)) {//遍历所有邻居
// System.out.println(cur + ", " +near + ": pro-" + curP);
if (!visited[near]) {//如果该邻居没有访问过
visited[near] = true;//访问它
path.add(near);//放入路径中
curP *= graph[cur][near];//计算路径概率
// System.out.println(near + ": " + curP);
//剪枝步是非常重要的
if (curP < maxP) {
//恢复状态
visited[near] = false;
curP /= graph[cur][near];
path.remove(path.size()-1);
continue;//如果当前路径已经小于所得最大值,那就剪枝了
}
dfs(adjacent, graph, near, end, curP, visited, path);
//恢复状态
visited[near] = false;
curP /= graph[cur][near];
path.remove(path.size()-1);
}
}
}
public double maxProbability(int n, int[][] edges, double[] succProb, int start, int end) {
//处理一下边的数据结构使找到邻边更容易
//使用矩阵存储边上的权重信息
double[][] graph = new double[n][n];
//额外使用一个邻接表用于取某结点的邻居,否则需要遍历矩阵的一行来判断是否存在边
Map<Integer, List<Integer>> adjacent = new HashMap<>();
for (int i = 0; i < n; i++) {
List<Integer> neighbors = new ArrayList<>();
adjacent.put(i, neighbors);
}
//构建矩阵和邻接表
for (int i = 0; i < succProb.length; i++) {
int node1 = edges[i][0];
int node2 = edges[i][1];
graph[node1][node2] = succProb[i];
graph[node2][node1] = succProb[i];
adjacent.get(node1).add(node2);
adjacent.get(node2).add(node1);
}
// System.out.println(adjacent);
//记录结点是否访问过
boolean[] visited = new boolean[n];
//源节点访问
visited[start] = true;
//记录路径
List<Integer> path = new ArrayList<>();
//源节点永远为开头
path.add(start);
//深度优先遍历
dfs(adjacent, graph, start, end, 1.0, visited, path);
return maxP;
}
public static void main(String[] args) {
int n = 1000;
int[][] edges = new int[][]{...测试例..};
double[] succPro = new double[]{...测试例...};
int start = 112;
int end = 493;
MaxProPath pp = new MaxProPath();
System.out.println(pp.maxProbability(n, edges, succPro, start, end));
}
}
经过空间和搜索策略优化过的代码:
import java.util.*;
public class MaxProPath {
double maxP = 0.0;
/**
* 深度优先+分支限界搜索全图
* 界就是要求的最大路径概率值
* 代价函数f(cur) = curP * 1.0,表示将cur以后的路径概率全看成是1.0时,可以取得的最优值,显然如果该最优值小于当前已经得到的最
* 优解,那就没有必要继续搜索,该搜索子树可以剪枝了。
* @param adjacent 该图的邻接表,用于加速求某个结点的所有邻居
* @param graph 该图的带权矩阵表示法
* @param cur 当前搜到的结点,如果等于end说明搜到了一个解
* @param end 终点
* @param curP 当前的概率值
* @param visited 标记结点是否访问
* @param path 解的路径向量
*/
public void dfs(Map<Integer, PriorityQueue<Node>> adjacent, int cur, int end, double curP,
boolean[] visited, List<Integer> path)
{
if (cur == end) {//当搜到目标时
maxP = Math.max(maxP, curP);//最优解更新
System.out.println("end... " + maxP);
System.out.println(path);
return;
}
//从当前点cur继续搜
for (Node near: adjacent.get(cur)) {//遍历所有邻居
// System.out.println(cur + ", " +near + ": pro-" + curP);
if (!visited[near.vex]) {//如果该邻居没有访问过
visited[near.vex] = true;//访问它
path.add(near.vex);//放入路径中
curP *= near.weight;//计算路径概率
// System.out.println(near + ": " + curP);
//剪枝步是非常重要的
if (curP < maxP) {
//恢复状态
visited[near.vex] = false;
curP /= near.weight;
path.remove(path.size()-1);
continue;//如果当前路径已经小于所得最大值,那就剪枝了
}
dfs(adjacent, near.vex, end, curP, visited, path);
//恢复状态
visited[near.vex] = false;
curP /= near.weight;
path.remove(path.size()-1);
}
}
}
public double maxProbability(int n, int[][] edges, double[] succProb, int start, int end) {
//处理一下边的数据结构使找到邻边更容易
//使用矩阵存储边上的权重信息
// double[][] graph = new double[n][n];
//额外使用一个邻接表用于取某结点的邻居,否则需要遍历矩阵的一行来判断是否存在边
Map<Integer, PriorityQueue<Node>> adjacent = new HashMap<>();
for (int i = 0; i < n; i++) {
PriorityQueue<Node> neighbors = new PriorityQueue<>((o1, o2) -> {
if (o1.weight < o2.weight) return 1;
if (o1.weight > o2.weight) return -1;
return 0;
});
adjacent.put(i, neighbors);
}
//构建矩阵和邻接表
for (int i = 0; i < succProb.length; i++) {
int node1 = edges[i][0];
int node2 = edges[i][1];
// graph[node1][node2] = succProb[i];
// graph[node2][node1] = succProb[i];
adjacent.get(node1).add(new Node(node2, succProb[i]));
adjacent.get(node2).add(new Node(node1, succProb[i]));
}
// System.out.println(adjacent);
//记录结点是否访问过
boolean[] visited = new boolean[n];
//源节点访问
visited[start] = true;
//记录路径
List<Integer> path = new ArrayList<>();
//源节点永远为开头
path.add(start);
//深度优先遍历
dfs(adjacent, start, end, 1.0, visited, path);
return maxP;
}
public static void main(String[] args) {
int n = 1000;
int[][] edges = new int[][]{测试例见上面的代码};
double[] succPro = new double[]{测试例见上面的代码};
int start = 112;
int end = 493;
MaxProPath pp = new MaxProPath();
System.out.println(pp.maxProbability(n, edges, succPro, start, end));
}
}
class Node implements Comparator<Node> {
int vex;
double weight;
Node(int vex, double weight) {
this.vex = vex;
this.weight = weight;
}
//实现比较接口,以便于进行排序,这里的实现是逆序的
@Override
public int compare(Node o1, Node o2) {
if (o1.weight < o2.weight) return 1;
if (o1.weight > o2.weight) return -1;
return 0;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("(").append(vex).append(", ").append(weight).append(")");
return sb.toString();
}
}
广度优先代码:
广度优先可以使得先搜到的目标路径最短,因此更容易得到最大值。但是还是超时了,不过这次通过了全部的16个测试例。之前的都卡在了前面就直接超时了。

/**
*广度优先加+分支限界求解
* @param adjacent 邻接表
* @param start 起始节点
* @param end 目标结点
*/
public void bfs(Map<Integer, PriorityQueue<Node>> adjacent, int start, int end) {
//
// 这里node结点的weight不再是自己的权重而是自己这条路径上的累积值
Queue<BFSNode> queue = new LinkedList<>();
Set<Integer> set = new HashSet<>();
set.add(start);
queue.offer(new BFSNode(start, 1.0, set));
while (!queue.isEmpty()) {
BFSNode node = queue.poll();
int vex = node.vex;
double w = node.pathWeight;
Set<Integer> path = node.path;
//找到目标结点
if (vex == end) {
System.out.println(w);
System.out.println(path);
System.out.println("end....");
maxP = Math.max(maxP, w);
continue;
}
//剪枝
if (w < maxP) continue;//剪枝
//遍历所有的邻居
for (Node near: adjacent.get(vex)) {
//如果路径上没有该邻居,将邻居当成自己的孩子,放入队列
if (!path.contains(near.vex)) {
Set<Integer> newPath = new HashSet<>();
newPath.addAll(path);
newPath.add(near.vex);
queue.offer(new BFSNode(near.vex, near.weight * w, newPath));
}
}
}
}
BFSNode类的实现:
class BFSNode {
int vex;
double pathWeight;
//这里不使用list,是因为不需要真的求出这条路径,而这个路径更重要的是判断谁已经在路径中了,也就是被访问过
//其所有的祖先结点都在里面
Set<Integer> path;
BFSNode(int vex, double pathWeight, Set<Integer> path) {
this.vex = vex;
this.pathWeight = pathWeight;
this.path = path;
}
}
又加了一个优化条件,终于通过了,而且双百。

优化的点主要有三个:
- 在遍历结点的邻居的时候,按照权重的大小顺序来进行,这样保证了权重大的更先被遍历到;
- 如果遍历到某个结点发现已得路径的概率小于目前求得的最优解,则再往下搜也没啥用了,因为每条边的权重都不超过1.0,所以越搜路径的概率只会越小,不会超过这个最优解;
- 如果从start到end的某条路径概率最大,则该路径上任意两点间的路径概率也必定是最大的,根据这个性质,如果我们遍历到某点,发现路径概率没有从start出发到该点的当前最优路径概率大,则该子树显然没有继续搜索的必要了要利用这条性质进一步剪枝,这里是设了一个数组用于保存从起始点到该结点的当前最大路径概率,如果搜到一个更大的路径概率就更新它,否则就放弃这条路径的搜索。
前面已经使用了前两个优化方法,现在我们再添加一个优化条件,就是上面的3.
代码:
/**
*广度优先加+分支限界求解
* @param adjacent 邻接表
* @param start 起始节点
* @param end 目标结点
*/
public void bfs(Map<Integer, PriorityQueue<Node>> adjacent, int start, int end) {
//
// 这里node结点的weight不再是自己的权重而是自己这条路径上的累积值
Queue<BFSNode> queue = new LinkedList<>();
Set<Integer> set = new HashSet<>();
set.add(start);
queue.offer(new BFSNode(start, 1.0, set));
//如果从start到end的某条路径概率最大,则该路径上任意两点间的路径概率也必定是最大的
//根据这个性质,如果我们遍历到某点,发现路径概率没有从start出发到该点的另一条路径概率大,则
//该子树显然没有继续搜索的必要了
//要利用这条性质进一步剪枝
double[] maxPath = new double[adjacent.size()];
while (!queue.isEmpty()) {
BFSNode node = queue.poll();
int vex = node.vex;
double w = node.pathWeight;
Set<Integer> path = node.path;
//找到目标结点
if (vex == end) {
maxP = Math.max(maxP, w);
continue;
}
//剪枝,综合了条件2和3
if (w < maxP || w < maxPath[vex]) continue;//剪枝
//更新到结点vex的最大路径概率
maxPath[vex] = w;
//遍历所有的邻居
for (Node near: adjacent.get(vex)) {
//如果路径上没有该邻居,将邻居当成自己的孩子,放入队列
if (!path.contains(near.vex)) {
Set<Integer> newPath = new HashSet<>();
newPath.addAll(path);
newPath.add(near.vex);
queue.offer(new BFSNode(near.vex, near.weight * w, newPath));
}
}
}
}
使用第三个优化条件再次对深度优先进行优化,但是最终还是超时了,很显然,这道题不适合深度优先。
代码:
class Solution {
double maxP = 0.0;
public void dfs(Map<Integer, PriorityQueue<Node>> adjacent, int cur, int end, double curP, boolean[] visited, double[] maxPath)
{
if (cur == end) {//当搜到目标时
maxP = Math.max(maxP, curP);//最优解更新
return;
}
//从当前点cur继续搜
for (Node near: adjacent.get(cur)) {//遍历所有邻居
if (!visited[near.vex]) {//如果该邻居没有访问过
visited[near.vex] = true;//访问它
curP *= near.weight;//计算路径概率
//剪枝步是非常重要的
if (curP < maxP || curP < maxPath[near.vex]) {
//恢复状态
visited[near.vex] = false;
curP /= near.weight;
continue;//如果当前路径已经小于所得最大值,那就剪枝了
}
maxPath[near.vex] = curP;
dfs(adjacent, near.vex, end, curP, visited, maxPath);
//恢复状态
visited[near.vex] = false;
curP /= near.weight;
}
}
}
public double maxProbability(int n, int[][] edges, double[] succProb, int start, int end) {
//处理一下边的数据结构使找到邻边更容易
//使用一个邻接表用于取某结点的邻居
Map<Integer, PriorityQueue<Node>> adjacent = new HashMap<>();
for (int i = 0; i < n; i++) {
PriorityQueue<Node> neighbors = new PriorityQueue<>();
adjacent.put(i, neighbors);
}
//构建矩阵和邻接表
for (int i = 0; i < succProb.length; i++) {
int node1 = edges[i][0];
int node2 = edges[i][1];
adjacent.get(node1).add(new Node(node2, succProb[i]));
adjacent.get(node2).add(new Node(node1, succProb[i]));
}
//记录结点是否访问过
boolean[] visited = new boolean[n];
//源节点访问
visited[start] = true;
//记录从start到每个结点的路径最大概率
double[] maxPath = new double[n];
//深度优先遍历
dfs(adjacent, start, end, 1.0, visited, maxPath);
return maxP;
}
}
class Node implements Comparable<Node> {
int vex;
double weight;
Node(int vex, double weight) {
this.vex = vex;
this.weight = weight;
}
//实现比较接口,以便于进行排序,这里的实现是逆序的
//如果是实现的本接口,则在使用时可以不用传参
@Override
public int compareTo(Node o) {
if (this.weight < o.weight) return 1;
if (this.weight > o.weight) return -1;
return 0;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("(").append(vex).append(", ").append(weight).append(")");
return sb.toString();
}
}
8. 总结
尽管分支限界算法中,使用深度优先策略进行求解是很常见的,但是也有一些地方是不适用的,比如说第7小节里面的那个例子。
深度优先搜索树是尽可能的深但是树的宽度小,分支少;而广度优先则恰恰相反。
因此如果遇到像第7节中的例子这种问题,要利用广度搜索树尽可能浅的特点加速求解。如果这道题改为概率相加而不是相乘,则使用深度优先就是必要的了。
所以,我们在选用搜索策略的时候,不要盲目,最好是分析一下解的特点。

















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









