



一、数组(Array)
-
数组的特点是什么?
1. 结构特性
- 固定长度:数组一旦创建,长度不可改变(静态数组);动态数组可扩容,但底层仍是固定大小的块。
- 元素类型一致:数组中的所有元素类型相同,便于统一管理和计算。
- 有序存储:元素按索引顺序存储,索引从
0开始。
2. 存储特性
- 连续内存空间:数组在内存中占用一段连续的地址区域。
- 随机访问:可以通过索引直接访问任意元素,时间复杂度为 O(1)。
- 内存效率高:连续存储减少了额外的指针或结构开销。
3. 操作特性
- 访问速度快:索引访问是常数时间复杂度。
- 插入/删除效率低:在中间位置插入或删除元素需要移动大量数据,时间复杂度为 O(n)。
- 遍历方便:可以通过循环快速遍历所有元素。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 访问速度快 | 插入/删除慢 |
| 结构简单 | 长度固定(静态数组) |
| 内存利用率高 | 可能浪费空间(预留容量) |
✅ 总结一句话:
数组是用连续内存存储同类型数据的线性结构,支持快速随机访问,但插入和删除效率较低。
-
数组的时间复杂度分析(查找、插入、删除)?
1. 时间复杂度分析
| 操作类型 | 平均时间复杂度 | 最坏时间复杂度 | 原理解释 |
|---|---|---|---|
| 查找(按索引) | 数组是连续内存存储,索引访问直接通过地址计算得到元素 | ||
| 查找(按值) | 需要遍历数组逐个比较,直到找到目标值 | ||
| 插入(末尾) | 在末尾添加元素无需移动其他元素(动态数组可能触发扩容) | ||
| 插入(中间) | 需要将插入位置后的所有元素向后移动一位 | ||
| 删除(末尾) | 删除末尾元素只需减少长度计数 | ||
| 删除(中间) | 需要将删除位置后的所有元素向前移动一位 |
2. 原理解释
-
查找(按索引)快
- 数组在内存中是连续存储的
- 元素地址计算公式:
地址=基地址+(索引×元素大小)地址=基地址+(索引×元素大小)
- 所以按索引访问是常数时间复杂度
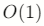
-
插入/删除(中间位置)慢
- 因为需要移动大量元素来保持连续存储结构
- 移动元素的数量与数组长度成正比,所以是
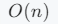
-
末尾操作快
- 在末尾添加或删除元素不需要移动其他元素,时间复杂度是
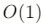
- 在末尾添加或删除元素不需要移动其他元素,时间复杂度是
3. 面试高分回答模板
数组的按索引查找是
,因为它是连续内存存储,可以直接通过地址计算访问;按值查找是
插入和删除在末尾是,在中间是
-
如何实现动态数组?
1. 动态数组的定义
动态数组是一种长度可变的数组结构,它在底层仍然使用连续内存存储数据,但可以在需要时自动扩容或缩容。
常见实现:
- Java 的
ArrayList - C++ 的
std::vector - Python 的
list(底层也是动态数组)
2. 核心原理
- 初始分配:创建时分配一个固定大小的连续内存块(如容量为 4)
- 扩容机制:当元素数量超过当前容量时:
- 分配一个更大的连续内存块(通常是原容量的 2 倍)
- 将旧数据复制到新内存块
- 释放旧内存
- 缩容机制(可选):当元素数量远小于容量时,减少内存占用
- 索引访问:与普通数组一样,支持
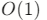 的按索引访问
的按索引访问
3. 实现步骤(伪代码)
例:
class DynamicArray {
private:
int* data; // 指向数组的指针
int size; // 当前元素数量
int capacity; // 当前容量
void resize(int newCapacity) {
int* newData = new int[newCapacity];
for (int i = 0; i < size; i++) {
newData[i] = data[i]; // 复制旧数据
}
delete[] data; // 释放旧内存
data = newData;
capacity = newCapacity;
}
public:
DynamicArray() {
capacity = 4; // 初始容量
size = 0;
data = new int[capacity];
}
void push_back(int value) {
if (size == capacity) {
resize(capacity * 2); // 扩容
}
data[size++] = value;
}
void pop_back() {
if (size > 0) {
size--;
}
}
int get(int index) {
return data[index];
}
};
4. 时间复杂度分析
- 按索引访问:
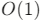
- 末尾插入:平均
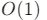 (摊销分析,扩容时为
(摊销分析,扩容时为 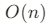 )
) - 中间插入/删除:
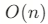 (需要移动元素)
(需要移动元素) - 扩容:
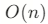 (复制所有元素)
(复制所有元素)
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 支持自动扩容 | 扩容时性能波动(复制数据) |
| 按索引访问快 | 中间插入/删除慢 |
| 内存利用率高 | 可能浪费部分预留空间 |
✅ 一句话总结:
动态数组通过在容量不足时成倍扩容,保证了平均 ![]() 的末尾插入性能,同时保留了普通数组的快速随机访问特性。
的末尾插入性能,同时保留了普通数组的快速随机访问特性。
-
如何在数组中查找重复元素?
1. 方法一:暴力双循环
原理:用两层循环比较每一对元素,看是否相等。
public static void findDuplicatesBruteForce(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] == arr[j]) {
System.out.println("重复元素: " + arr[i]);
}
}
}
}
- 时间复杂度:O(n2)
- 空间复杂度:O(1)
- 优点:实现简单
- 缺点:效率低,不适合大数据量
2. 方法二:排序 + 相邻比较
原理:先排序数组,然后只需比较相邻元素是否相等。
import java.util.Arrays;
public static void findDuplicatesSort(int[] arr) {
Arrays.sort(arr);
for (int i = 0; i < arr.length - 1; i++) {
if (arr[i] == arr[i + 1]) {
System.out.println("重复元素: " + arr[i]);
}
}
}
- 时间复杂度:O(nlogn)(排序)
- 空间复杂度:取决于排序算法(快速排序为 O(1))
- 优点:比暴力法快
- 缺点:会改变原数组顺序
3. 方法三:HashSet 检查
原理:用 HashSet 存储已访问的元素,如果发现元素已存在,则是重复。
import java.util.HashSet;
public static void findDuplicatesHashSet(int[] arr) {
HashSet<Integer> seen = new HashSet<>();
for (int num : arr) {
if (!seen.add(num)) {
System.out.println("重复元素: " + num);
}
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
- 优点:速度快,不改变原数组
- 缺点:需要额外空间
4. 方法四:计数数组(适用于元素范围已知且较小)
原理:用一个计数数组记录每个元素出现次数。
public static void findDuplicatesCountArray(int[] arr, int maxValue) {
int[] count = new int[maxValue + 1];
for (int num : arr) {
count[num]++;
if (count[num] == 2) {
System.out.println("重复元素: " + num);
}
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(k)(k 为最大元素值)
- 优点:速度快
- 缺点:只能用于元素范围已知且较小的情况
方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 是否改变原数组 | 适用场景 |
|---|---|---|---|---|
| 暴力双循环 | O(n2) | O(1) | 否 | 数据量小 |
| 排序+相邻比较 | O(nlogn) | O(1) | 是 | 中等数据量 |
| HashSet 检查 | O(n) | O(n) | 否 | 大数据量 |
| 计数数组 | O(n) | O(k) | 否 | 元素范围已知且较小 |
✅ 一句话总结:
如果数据量大且不关心额外空间,用 HashSet;如果数据量中等且能改变数组顺序,用排序法;数据量小可以用暴力法。
-
如何在有序数组中查找元素?
1. 原理
- 有序数组的特点:元素按升序或降序排列
- 二分查找的思路:
- 取数组中间元素
mid - 如果
target == arr[mid],找到目标 - 如果
target < arr[mid],在左半部分继续查找 - 如果
target > arr[mid],在右半部分继续查找 - 重复以上步骤,直到找到或区间为空
- 取数组中间元素
2. Java 实现
public class BinarySearchExample {
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2; // 防止溢出
if (arr[mid] == target) {
return mid; // 找到返回索引
} else if (arr[mid] < target) {
left = mid + 1; // 去右半部分
} else {
right = mid - 1; // 去左半部分
}
}
return -1; // 未找到
}
public static void main(String[] args) {
int[] arr = {1, 3, 5, 7, 9, 11, 13};
int target = 7;
int index = binarySearch(arr, target);
if (index != -1) {
System.out.println("元素 " + target + " 在索引 " + index);
} else {
System.out.println("未找到元素 " + target);
}
}
}
3. 时间复杂度分析
- 最佳情况:O(1)(第一次就找到)
- 平均情况:O(logn)
- 最坏情况:O(logn)(查找直到区间为空)
- 空间复杂度:O(1)(迭代实现)
4. 注意事项
- 数组必须有序(升序或降序)
- 如果数组中有重复元素,二分查找返回的是任意一个匹配位置,如果需要第一个或最后一个匹配位置,需要做额外处理
- 防止溢出:
mid = left + (right - left) / 2而不是(left + right) / 2
5. 方法对比
| 方法 | 时间复杂度 | 是否需要有序 | 适用场景 |
|---|---|---|---|
| 顺序查找 | O(n) | 否 | 小数据量或无序数组 |
| 二分查找 | O(logn) | 是 | 大数据量且有序数组 |
✅ 一句话总结:
在有序数组中查找元素,首选二分查找,时间复杂度 O(logn),比顺序查找快得多。
-
如何旋转数组?
1. 问题定义
旋转数组:将数组中的元素按指定的步数 k 向左或向右移动,超出边界的元素会循环到另一端。
例如:
原数组: [1, 2, 3, 4, 5, 6, 7] 右旋 k=3 → [5, 6, 7, 1, 2, 3, 4] 左旋 k=2 → [3, 4, 5, 6, 7, 1, 2]
2. 方法一:额外数组法
原理:创建一个新数组,把旋转后的元素按位置放入新数组,再复制回原数组。
public static void rotateExtraArray(int[] arr, int k) {
int n = arr.length;
k = k % n; // 防止 k > n
int[] temp = new int[n];
for (int i = 0; i < n; i++) {
temp[(i + k) % n] = arr[i]; // 右旋
}
// 复制回原数组
for (int i = 0; i < n; i++) {
arr[i] = temp[i];
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
- 优点:简单易懂
- 缺点:需要额外空间
3. 方法二:数组反转法(原地旋转)
原理:
- 反转整个数组
- 反转前 k 个元素
- 反转剩余 n−k 个元素
public static void rotateReverse(int[] arr, int k) {
int n = arr.length;
k = k % n;
reverse(arr, 0, n - 1);
reverse(arr, 0, k - 1);
reverse(arr, k, n - 1);
}
private static void reverse(int[] arr, int start, int end) {
while (start < end) {
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
start++;
end--;
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:不需要额外空间
- 缺点:逻辑稍复杂
4. 方法三:循环替换法
原理:从一个位置开始,把元素放到它旋转后的位置,直到回到起点,然后从下一个未处理位置继续。
public static void rotateCycle(int[] arr, int k) {
int n = arr.length;
k = k % n;
int count = 0; // 已移动元素数量
for (int start = 0; count < n; start++) {
int current = start;
int prev = arr[start];
do {
int next = (current + k) % n;
int temp = arr[next];
arr[next] = prev;
prev = temp;
current = next;
count++;
} while (start != current);
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:原地旋转
- 缺点:实现稍复杂
5. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 是否原地旋转 | 难度 |
|---|---|---|---|---|
| 额外数组法 | O(n) | O(n) | 否 | 简单 |
| 数组反转法 | O(n) | O(1) | 是 | 中等 |
| 循环替换法 | O(n) | O(1) | 是 | 较难 |
✅ 一句话总结:
如果想简单实现,用额外数组法;如果想节省空间,用数组反转法;如果追求算法技巧,可以用循环替换法。
-
如何合并两个有序数组?
1. 问题定义
给定两个升序数组 arr1 和 arr2,将它们合并成一个新的升序数组。
例如:
arr1 = [1, 3, 5] arr2 = [2, 4, 6] 合并结果 → [1, 2, 3, 4, 5, 6]
2. 方法一:双指针法(最常用)
原理:
- 用两个指针
i和j分别指向arr1和arr2的起始位置 - 比较两个指针指向的元素,将较小的放入结果数组,并移动该指针
- 当一个数组遍历完后,将另一个数组剩余元素直接加入结果数组
public static int[] mergeTwoSortedArrays(int[] arr1, int[] arr2) {
int n1 = arr1.length;
int n2 = arr2.length;
int[] result = new int[n1 + n2];
int i = 0, j = 0, k = 0;
while (i < n1 && j < n2) {
if (arr1[i] <= arr2[j]) {
result[k++] = arr1[i++];
} else {
result[k++] = arr2[j++];
}
}
// 复制剩余元素
while (i < n1) {
result[k++] = arr1[i++];
}
while (j < n2) {
result[k++] = arr2[j++];
}
return result;
}
public static void main(String[] args) {
int[] arr1 = {1, 3, 5};
int[] arr2 = {2, 4, 6};
int[] merged = mergeTwoSortedArrays(arr1, arr2);
System.out.print("合并结果: ");
for (int num : merged) {
System.out.print(num + " ");
}
}
3. 方法二:直接合并后排序
原理:
- 将两个数组合并成一个大数组
- 使用
Arrays.sort()排序
import java.util.Arrays;
public static int[] mergeAndSort(int[] arr1, int[] arr2) {
int[] result = new int[arr1.length + arr2.length];
System.arraycopy(arr1, 0, result, 0, arr1.length);
System.arraycopy(arr2, 0, result, arr1.length, arr2.length);
Arrays.sort(result);
return result;
}
- 时间复杂度:O((n+m)log(n+m))
- 空间复杂度:O(n+m)
- 优点:实现简单
- 缺点:效率不如双指针法
4. 方法三:原地合并(适用于有足够空间的 arr1)
原理:
- 从两个数组的末尾开始比较,将较大的元素放到
arr1的末尾(从后往前填充) - 适用于
arr1已有足够空间容纳arr2
public static void mergeInPlace(int[] arr1, int m, int[] arr2, int n) {
int i = m - 1; // arr1有效元素末尾
int j = n - 1; // arr2末尾
int k = m + n - 1; // arr1总末尾
while (i >= 0 && j >= 0) {
if (arr1[i] > arr2[j]) {
arr1[k--] = arr1[i--];
} else {
arr1[k--] = arr2[j--];
}
}
// 复制剩余 arr2 元素
while (j >= 0) {
arr1[k--] = arr2[j--];
}
}
- 时间复杂度:O(n+m)
- 空间复杂度:O(1)
- 优点:节省空间
- 缺点:只能在有足够空间的情况下使用
5. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 是否改变原数组 | 适用场景 |
|---|---|---|---|---|
| 双指针法 | O(n+m) | O(n+m) | 否 | 最常用 |
| 合并后排序 | O((n+m)log(n+m)) | O(n+m) | 否 | 简单实现 |
| 原地合并 | O(n+m) | O(1) | 是 | arr1 有足够空间 |
✅ 一句话总结:
如果两个数组都是有序的,首选双指针法;如果需要节省空间且 arr1 有足够容量,可以用原地合并。
-
如何找到数组中的最大/最小值?
1. 方法一:一次遍历法(最常用)
原理:
- 初始化
max和min为数组第一个元素 - 遍历数组,逐个比较更新最大值和最小值
public static void findMaxMin(int[] arr) {
if (arr == null || arr.length == 0) {
System.out.println("数组为空");
return;
}
int max = arr[0];
int min = arr[0];
for (int num : arr) {
if (num > max) {
max = num;
}
if (num < min) {
min = num;
}
}
System.out.println("最大值: " + max);
System.out.println("最小值: " + min);
}
public static void main(String[] args) {
int[] arr = {3, 7, 2, 9, 4, 1};
findMaxMin(arr);
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:高效、简单
- 缺点:无
2. 方法二:排序法
原理:
- 对数组进行排序
- 最大值是最后一个元素,最小值是第一个元素
import java.util.Arrays;
public static void findMaxMinBySort(int[] arr) {
Arrays.sort(arr);
System.out.println("最小值: " + arr[0]);
System.out.println("最大值: " + arr[arr.length - 1]);
}
- 时间复杂度:O(nlogn)
- 空间复杂度:取决于排序算法
- 优点:简单实现
- 缺点:效率低,不适合只找最大/最小值的情况
3. 方法三:分治法(适用于并行计算)
原理:
- 将数组分成两半,分别找最大值和最小值
- 合并结果得到全局最大值和最小值
public static int[] findMaxMinDivide(int[] arr, int left, int right) {
if (left == right) {
return new int[]{arr[left], arr[left]}; // {max, min}
}
int mid = (left + right) / 2;
int[] leftResult = findMaxMinDivide(arr, left, mid);
int[] rightResult = findMaxMinDivide(arr, mid + 1, right);
int max = Math.max(leftResult[0], rightResult[0]);
int min = Math.min(leftResult[1], rightResult[1]);
return new int[]{max, min};
}
- 时间复杂度:O(n)
- 空间复杂度:递归栈空间 O(logn)
- 优点:可并行化处理
- 缺点:实现复杂
4. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 是否改变原数组 | 适用场景 |
|---|---|---|---|---|
| 一次遍历法 | O(n) | O(1) | 否 | 最常用 |
| 排序法 | O(nlogn) | 取决于排序算法 | 是 | 不推荐 |
| 分治法 | O(n) | O(logn) | 否 | 并行计算 |
✅ 一句话总结:
找最大/最小值时,首选一次遍历法,既快又省空间;如果需要并行处理,可以用分治法。
-
如何找到数组的中位数?
1. 中位数定义
- 中位数:将数组排序后,位于中间位置的数值
- 如果数组长度是奇数:中位数是中间的那个元素
- 如果数组长度是偶数:中位数是中间两个元素的平均值
例如:
[3, 1, 4] → 排序后 [1, 3, 4] → 中位数 = 3 [3, 1, 4, 2] → 排序后 [1, 2, 3, 4] → 中位数 = (2 + 3) / 2 = 2.5
2. 方法一:排序法(最简单)
原理:
- 对数组进行排序
- 根据长度奇偶性取中位数
import java.util.Arrays;
public static double findMedianBySort(int[] arr) {
Arrays.sort(arr);
int n = arr.length;
if (n % 2 == 1) {
return arr[n / 2]; // 奇数长度
} else {
return (arr[n / 2 - 1] + arr[n / 2]) / 2.0; // 偶数长度
}
}
public static void main(String[] args) {
int[] arr1 = {3, 1, 4};
int[] arr2 = {3, 1, 4, 2};
System.out.println("中位数1: " + findMedianBySort(arr1));
System.out.println("中位数2: " + findMedianBySort(arr2));
}
- 时间复杂度:O(nlogn)
- 空间复杂度:取决于排序算法
- 优点:实现简单
- 缺点:效率不高
3. 方法二:快速选择(QuickSelect)
原理:
- 类似快速排序的分区过程,但只递归需要的部分
- 找到第 k 小的元素(中位数位置)
public static int quickSelect(int[] arr, int left, int right, int k) {
int pivot = arr[right];
int p = left;
for (int i = left; i < right; i++) {
if (arr[i] <= pivot) {
int temp = arr[i];
arr[i] = arr[p];
arr[p] = temp;
p++;
}
}
int temp = arr[p];
arr[p] = arr[right];
arr[right] = temp;
if (p == k) return arr[p];
else if (p < k) return quickSelect(arr, p + 1, right, k);
else return quickSelect(arr, left, p - 1, k);
}
public static double findMedianQuickSelect(int[] arr) {
int n = arr.length;
if (n % 2 == 1) {
return quickSelect(arr, 0, n - 1, n / 2);
} else {
int leftMid = quickSelect(arr.clone(), 0, n - 1, n / 2 - 1);
int rightMid = quickSelect(arr.clone(), 0, n - 1, n / 2);
return (leftMid + rightMid) / 2.0;
}
}
- 时间复杂度:平均O(n)
- 空间复杂度:O(1)
- 优点:比排序法快
- 缺点:实现复杂
4. 方法三:双堆法(适用于数据流)
原理:
- 用一个最大堆存储较小的一半元素
- 用一个最小堆存储较大的一半元素
- 保持两个堆的大小平衡,中位数在堆顶
import java.util.PriorityQueue;
public class MedianFinder {
private PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
private PriorityQueue<Integer> minHeap = new PriorityQueue<>();
public void addNum(int num) {
maxHeap.offer(num);
minHeap.offer(maxHeap.poll());
if (maxHeap.size() < minHeap.size()) {
maxHeap.offer(minHeap.poll());
}
}
public double findMedian() {
if (maxHeap.size() == minHeap.size()) {
return (maxHeap.peek() + minHeap.peek()) / 2.0;
} else {
return maxHeap.peek();
}
}
}
- 时间复杂度:每次插入 O(logn)
- 空间复杂度:O(n)
- 优点:适合实时计算中位数
- 缺点:实现复杂
5. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 是否适合数据流 | 难度 |
|---|---|---|---|---|
| 排序法 | O(nlogn) | 取决于排序算法 | 否 | 简单 |
| 快速选择 | 平均 O(n) | O(1) | 否 | 中等 |
| 双堆法 | O(logn)(每次插入) | O(n) | 是 | 较难 |
✅ 一句话总结:
一次性计算中位数用快速选择法最快;实时计算中位数用双堆法最优;简单场景用排序法即可。
-
稀疏数组的存储与应用场景?
1. 什么是稀疏数组
- 稀疏数组:在一个二维数组中,大部分元素为零或相同值,只有少量元素是非零值。
- 如果直接存储,会浪费大量空间。
- 例如:
原二维数组(11×11): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ...
只有少数位置有非零值。
2. 存储方式
核心思想:只记录非零元素的行、列、值。
2.1 转换为稀疏数组
- 第一行记录:原数组行数、列数、非零元素个数
- 后续每行记录:非零元素的行、列、值
例如:
原二维数组 → 稀疏数组: [11, 11, 2] // 11行,11列,2个非零元素 [2, 3, 1] // 第2行第3列的值为1 [5, 7, 2] // 第5行第7列的值为2
2.2 Java 示例代码
public static int[][] toSparseArray(int[][] array) {
int rows = array.length;
int cols = array[0].length;
int count = 0;
// 统计非零元素个数
for (int[] row : array) {
for (int val : row) {
if (val != 0) count++;
}
}
// 创建稀疏数组
int[][] sparse = new int[count + 1][3];
sparse[0][0] = rows;
sparse[0][1] = cols;
sparse[0][2] = count;
int index = 1;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (array[i][j] != 0) {
sparse[index][0] = i;
sparse[index][1] = j;
sparse[index][2] = array[i][j];
index++;
}
}
}
return sparse;
}
2.3 从稀疏数组还原
public static int[][] toOriginalArray(int[][] sparse) {
int rows = sparse[0][0];
int cols = sparse[0][1];
int[][] array = new int[rows][cols];
for (int i = 1; i < sparse.length; i++) {
array[sparse[i][0]][sparse[i][1]] = sparse[i][2];
}
return array;
}
3. 应用场景
-
棋盘类游戏(如五子棋、围棋)
- 棋盘大部分位置为空,只有少数位置有棋子
- 用稀疏数组存储可以节省空间,并方便保存和读取棋局
-
地图存储(如迷宫、路径规划)
- 地图中大部分区域是空地,只有少数障碍物或特殊点
- 稀疏数组可以快速记录这些特殊点的位置和类型
-
矩阵计算(如机器学习中的稀疏矩阵)
- 特征矩阵中很多值为零
- 稀疏存储可以减少内存占用,并加快计算速度
-
数据压缩与持久化
- 将稀疏数组保存到文件中,减少存储空间
- 读取时再还原成原二维数组
4. 方法对比表
| 存储方式 | 空间占用 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 普通二维数组 | 高 | 数据密集 | 访问速度快 | 占用空间大 |
| 稀疏数组 | 低 | 数据稀疏 | 节省空间、易保存 | 访问速度略慢 |
✅ 一句话总结:
稀疏数组通过只记录非零元素的位置和值,大幅节省空间,适用于棋盘、地图、稀疏矩阵等场景。
二、链表(Linked List)
-
单链表与双链表的区别?
1. 基本定义
-
单链表(Singly Linked List)
每个节点包含 数据域 和 指向下一个节点的指针,只能单向遍历。 -
双链表(Doubly Linked List)
每个节点包含 数据域、指向下一个节点的指针 和 指向上一个节点的指针,可以双向遍历。
2. 结构示意
单链表节点结构:
[Data] → [Next] → [Data] → [Next] → null
双链表节点结构:
null ← [Prev] [Data] [Next] → [Prev] [Data] [Next] → null
3. 主要区别
| 特性 | 单链表 | 双链表 |
|---|---|---|
| 指针数量 | 1(只指向下一个节点) | 2(指向前一个和后一个节点) |
| 遍历方向 | 只能从头到尾 | 可从头到尾,也可从尾到头 |
| 插入/删除效率 | 删除节点时需找到前驱节点,效率较低 | 可直接通过前驱指针删除,效率较高 |
| 空间占用 | 较小(少一个指针) | 较大(多一个指针) |
| 实现复杂度 | 较简单 | 较复杂 |
| 适用场景 | 只需单向遍历的场景,如队列 | 需要频繁双向遍历或删除的场景,如浏览器历史记录、LRU缓存 |
4. Java 节点定义示例
单链表节点:
[Data] → [Next] → [Data] → [Next] → null
双链表节点:
null ← [Prev] [Data] [Next] → [Prev] [Data] [Next] → null
5. 适用场景总结
-
单链表:
- 内存紧张
- 只需单向遍历
- 插入/删除主要在链表头或尾
-
双链表:
- 需要频繁双向遍历
- 删除节点时不想遍历找前驱
- 需要在中间位置频繁插入/删除
✅ 一句话总结:
单链表结构简单、占用空间少,但只能单向遍历;双链表可双向遍历,插入删除更高效,但占用空间多、实现复杂。
-
链表的时间复杂度分析?
1. 链表的基本操作
链表常见的操作包括:
- 访问(查找)某个节点
- 在头部插入/删除节点
- 在尾部插入/删除节点
- 在中间插入/删除节点(已知位置或已知节点引用)
2. 时间复杂度分析
| 操作 | 单链表 | 双链表 | 说明 |
|---|---|---|---|
| 访问第 k 个节点 | O(n) | O(n) | 需要从头(或尾)遍历,无法随机访问 |
| 在头部插入 | O(1) | O(1) | 直接修改头指针 |
| 在头部删除 | O(1) | O(1) | 直接修改头指针 |
| 在尾部插入 | O(n)(无尾指针) / O(1)(有尾指针) | O(1) | 双链表可直接通过尾指针插入 |
| 在尾部删除 | O(n)(无尾指针) | O(1) | 双链表可直接通过尾指针删除 |
| 在中间插入(已知节点) | O(1) | O(1) | 修改指针即可 |
| 在中间删除(已知节点) | O(n)(需找前驱) | O(1) | 双链表可直接通过 prev 找前驱 |
3. 关键结论
- 查找节点:链表不支持随机访问,必须遍历 →O(n)
- 插入/删除已知节点:指针操作即可 → O(1)
- 双链表在删除节点时更快,因为它有
prev指针,不需要遍历找前驱节点 - 如果需要频繁在尾部操作,维护尾指针可以让单链表尾部插入变为 O(1)
4. 对比数组
| 操作 | 数组 | 链表 |
|---|---|---|
| 随机访问 | O(1) | O(n) |
| 头部插入/删除 | O(n) | O(1) |
| 尾部插入/删除 | O(1) | O(1)(有尾指针) |
| 中间插入/删除 | O(n) | O(1)(已知节点) |
✅ 一句话总结:
链表在插入/删除已知节点时效率高,但查找效率低;双链表在删除节点和尾部操作上比单链表更优。
-
如何反转链表?
1. 问题描述
给定一个单链表,将其反转,使得链表的指针方向完全反转。
例如:
原链表:1 → 2 → 3 → 4 → null
反转后:4 → 3 → 2 → 1 → null
2. 方法一:迭代法(最常用)
原理:
- 用三个指针
prev、curr、next - 遍历链表时,逐个反转
next指针的方向
Java 代码:
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}
public static ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next; // 暂存下一个节点
curr.next = prev; // 反转指针
prev = curr; // prev 前进
curr = next; // curr 前进
}
return prev; // 新的头节点
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:高效、简单
- 缺点:无
3. 方法二:递归法
原理:
- 递归到链表末尾,然后逐层反转指针
Java 代码:
public static ListNode reverseListRecursive(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode newHead = reverseListRecursive(head.next);
head.next.next = head;
head.next = null;
return newHead;
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)(递归栈)
- 优点:代码简洁
- 缺点:递归深度大时可能栈溢出
4. 方法三:头插法(构建新链表)
原理:
- 创建一个新链表
- 遍历原链表,将每个节点插入新链表的头部
Java 代码:
public static ListNode reverseListHeadInsert(ListNode head) {
ListNode newHead = null;
while (head != null) {
ListNode next = head.next;
head.next = newHead;
newHead = head;
head = next;
}
return newHead;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:逻辑清晰
- 缺点:与迭代法类似,但多了一个新链表变量
5. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 迭代法 | O(n) | O(1) | 高效、稳定 | 无 |
| 递归法 | O(n) | O(n) | 代码简洁 | 栈溢出风险 |
| 头插法 | O(n) | O(1) | 思路直观 | 与迭代法类似 |
✅ 一句话总结:
反转链表首选迭代法,既快又省空间;递归法代码短但有栈溢出风险;头插法适合构建新链表时使用。
-
如何合并两个有序链表?
1. 问题描述
给定两个 升序 的单链表 l1 和 l2,将它们合并成一个新的升序链表,并返回新链表的头节点。
示例:
l1: 1 → 3 → 5 l2: 2 → 4 → 6 合并后: 1 → 2 → 3 → 4 → 5 → 6
2. 方法一:迭代法(推荐)
原理:
- 创建一个 虚拟头节点(dummy),用
tail指针指向新链表的末尾 - 比较
l1和l2当前节点的值,将较小的节点接到tail后面 - 移动对应链表的指针,直到某个链表为空
- 最后将剩余的链表直接接到
tail后面
Java 代码:
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}
public static ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
tail.next = l1;
l1 = l1.next;
} else {
tail.next = l2;
l2 = l2.next;
}
tail = tail.next;
}
// 接上剩余部分
if (l1 != null) tail.next = l1;
if (l2 != null) tail.next = l2;
return dummy.next;
}
- 时间复杂度:O(m+n)(m、n 为两个链表长度)
- 空间复杂度:O(1)
- 优点:高效、稳定
3. 方法二:递归法
原理:
- 比较两个链表的头节点
- 将较小的节点作为新链表的头,并递归合并剩余部分
Java 代码:
public static ListNode mergeTwoListsRecursive(ListNode l1, ListNode l2) {
if (l1 == null) return l2;
if (l2 == null) return l1;
if (l1.val <= l2.val) {
l1.next = mergeTwoListsRecursive(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoListsRecursive(l1, l2.next);
return l2;
}
}
- 时间复杂度:O(m+n)
- 空间复杂度:O(m+n)(递归栈)
- 优点:代码简洁
- 缺点:递归深度大时可能栈溢出
4. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 迭代法 | O(m+n) | O(1) | 高效、稳定 | 代码稍长 |
| 递归法 | O(m+n) | O(m+n) | 代码简洁 | 栈溢出风险 |
✅ 一句话总结:
合并两个有序链表首选迭代法,既快又省空间;递归法更简洁,但在链表很长时可能会栈溢出。
-
如何检测链表是否有环?
1. 问题描述
给定一个单链表,判断它是否存在环(即某个节点的 next 指针指向了之前的某个节点)。
示例:
1 → 2 → 3 → 4 → 5 ↑ ↓ ← ← ← ← ←
这里节点 5 的 next 指向了节点 3,形成了环。
2. 方法一:快慢指针(Floyd 判圈法,推荐)
原理:
- 使用两个指针
slow和fast slow每次走一步,fast每次走两步- 如果链表有环,
fast会在环内追上slow - 如果链表无环,
fast会先到达null
Java 代码:
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}
public static boolean hasCycle(ListNode head) {
if (head == null || head.next == null) return false;
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) return true; // 相遇说明有环
}
return false;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:高效、无需额外空间
3. 方法二:哈希表法
原理:
- 使用
HashSet存储访问过的节点 - 遍历链表时,如果某个节点已经在集合中出现过,则说明有环
Java 代码:
import java.util.HashSet;
public static boolean hasCycleHash(ListNode head) {
HashSet<ListNode> visited = new HashSet<>();
while (head != null) {
if (visited.contains(head)) return true;
visited.add(head);
head = head.next;
}
return false;
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
- 优点:实现简单
- 缺点:需要额外空间
4. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 快慢指针 | O(n) | O(1) | 高效、节省空间 | 逻辑稍难理解 |
| 哈希表法 | O(n) | O(n) | 实现简单 | 占用额外空间 |
✅ 一句话总结:
检测链表是否有环首选快慢指针法,既快又省空间;哈希表法更直观,但需要额外内存。
-
如何找到链表的中间节点?
1. 问题描述
给定一个单链表,返回它的中间节点。
- 如果链表长度为奇数,返回正中间的节点
- 如果链表长度为偶数,通常返回第二个中间节点(LeetCode 默认规则)
示例:
1 → 2 → 3 → 4 → 5 中间节点:3 1 → 2 → 3 → 4 → 5 → 6 中间节点:4(第二个中间节点)
2. 方法一:快慢指针法(推荐)
原理:
- 使用两个指针
slow和fast slow每次走一步,fast每次走两步- 当
fast到达链表末尾时,slow就在中间位置
Java 代码:
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}
public static ListNode middleNode(ListNode head) {
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:一次遍历即可找到中间节点
3. 方法二:两次遍历法
原理:
- 第一次遍历计算链表长度
len - 第二次遍历到第
len/2个节点并返回
Java 代码:
public static ListNode middleNodeTwoPass(ListNode head) {
int len = 0;
ListNode curr = head;
while (curr != null) {
len++;
curr = curr.next;
}
curr = head;
for (int i = 0; i < len / 2; i++) {
curr = curr.next;
}
return curr;
}
- 时间复杂度:O(n)(两次遍历)
- 空间复杂度:O(1)
- 优点:逻辑简单
- 缺点:需要两次遍历
4. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 快慢指针法 | O(n) | O(1) | 一次遍历即可 | 逻辑稍难理解 |
| 两次遍历法 | O(n) | O(1) | 实现简单 | 遍历两次,效率稍低 |
✅ 一句话总结:
找链表中间节点首选快慢指针法,一次遍历即可完成;两次遍历法更直观但效率稍低。
-
如何删除链表的倒数第 N 个节点?
1. 问题描述
给定一个单链表,删除它的倒数第 N 个节点,并返回链表的头节点。
示例:
输入:1 → 2 → 3 → 4 → 5, N = 2 输出:1 → 2 → 3 → 5 (删除倒数第 2 个节点,即节点 4)
2. 方法一:快慢指针法(推荐)
原理:
- 创建一个 虚拟头节点(dummy),指向链表头,方便处理删除头节点的情况
- 使用两个指针
fast和slow - 先让
fast前进 N+1 步(保证slow停在待删除节点的前一个位置) - 同时移动
fast和slow,直到fast到达链表末尾 - 删除
slow.next节点
Java 代码:
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}
public static ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode fast = dummy;
ListNode slow = dummy;
// fast 先走 n+1 步
for (int i = 0; i <= n; i++) {
fast = fast.next;
}
// fast 和 slow 一起走
while (fast != null) {
fast = fast.next;
slow = slow.next;
}
// 删除 slow.next
slow.next = slow.next.next;
return dummy.next;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 优点:一次遍历即可完成删除
3. 方法二:两次遍历法
原理:
- 第一次遍历计算链表长度
len - 找到第
len - n个节点(即待删除节点的前一个节点) - 删除该节点的
next
Java 代码:
public static ListNode removeNthFromEndTwoPass(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
int len = 0;
ListNode curr = head;
// 计算长度
while (curr != null) {
len++;
curr = curr.next;
}
// 找到待删除节点的前一个节点
curr = dummy;
for (int i = 0; i < len - n; i++) {
curr = curr.next;
}
// 删除节点
curr.next = curr.next.next;
return dummy.next;
}
- 时间复杂度:O(n)(两次遍历)
- 空间复杂度:O(1)
- 优点:逻辑简单
- 缺点:需要两次遍历
4. 方法对比表
| 方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 快慢指针法 | O(n) | O(1) | 一次遍历即可 | 逻辑稍难理解 |
| 两次遍历法 | O(n) | O(1) | 实现简单 | 效率稍低 |
✅ 一句话总结:
删除链表倒数第 N 个节点首选快慢指针法,一次遍历即可完成;两次遍历法更直观但效率稍低。
-
如何在链表中实现插入与删除?
1. 链表插入操作
链表插入分为几种情况:
- 在头部插入(头插法)
- 在尾部插入(尾插法)
- 在指定位置插入
1.1 在头部插入
原理:
- 创建新节点
newNode - 将
newNode.next指向原头节点 - 更新头节点为
newNode
Java 代码:
public static ListNode insertAtHead(ListNode head, int val) {
ListNode newNode = new ListNode(val);
newNode.next = head;
return newNode; // 新的头节点
}
- 时间复杂度:O(1)
- 空间复杂度:O(1)
1.2 在尾部插入
原理:
- 遍历到链表末尾
- 将末尾节点的
next指向新节点
Java 代码:
public static ListNode insertAtTail(ListNode head, int val) {
ListNode newNode = new ListNode(val);
if (head == null) return newNode;
ListNode curr = head;
while (curr.next != null) {
curr = curr.next;
}
curr.next = newNode;
return head;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
1.3 在指定位置插入
原理:
- 遍历到指定位置的前一个节点
- 将新节点插入到该位置
Java 代码:
public static ListNode insertAtPosition(ListNode head, int val, int pos) {
ListNode newNode = new ListNode(val);
if (pos == 0) {
newNode.next = head;
return newNode;
}
ListNode curr = head;
for (int i = 0; i < pos - 1 && curr != null; i++) {
curr = curr.next;
}
if (curr != null) {
newNode.next = curr.next;
curr.next = newNode;
}
return head;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
2. 链表删除操作
链表删除也分几种情况:
- 删除头节点
- 删除尾节点
- 删除指定位置节点
- 按值删除节点
2.1 删除头节点
原理:
- 将头节点指向
head.next
Java 代码:
public static ListNode deleteHead(ListNode head) {
if (head == null) return null;
return head.next;
}
- 时间复杂度:O(1)
- 空间复杂度:O(1)
2.2 删除尾节点
原理:
- 遍历到倒数第二个节点
- 将其
next置为null
Java 代码:
public static ListNode deleteTail(ListNode head) {
if (head == null || head.next == null) return null;
ListNode curr = head;
while (curr.next.next != null) {
curr = curr.next;
}
curr.next = null;
return head;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
2.3 删除指定位置节点
原理:
- 遍历到指定位置的前一个节点
- 跳过该位置节点
Java 代码:
public static ListNode deleteAtPosition(ListNode head, int pos) {
if (pos == 0) return head.next;
ListNode curr = head;
for (int i = 0; i < pos - 1 && curr != null; i++) {
curr = curr.next;
}
if (curr != null && curr.next != null) {
curr.next = curr.next.next;
}
return head;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
2.4 按值删除节点
原理:
- 找到值匹配的节点的前一个节点
- 跳过该节点
Java 代码:
public static ListNode deleteByValue(ListNode head, int val) {
if (head == null) return null;
if (head.val == val) return head.next;
ListNode curr = head;
while (curr.next != null && curr.next.val != val) {
curr = curr.next;
}
if (curr.next != null) {
curr.next = curr.next.next;
}
return head;
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
3. 方法对比表
| 操作类型 | 时间复杂度 | 空间复杂度 | 说明 |
|---|---|---|---|
| 头插法 | O(1) | O(1) | 直接修改头指针 |
| 尾插法 | O(n) | O(1) | 需遍历到末尾 |
| 指定位置插入 | O(n) | O(1) | 需遍历到位置前 |
| 删除头节点 | O(1) | O(1) | 直接修改头指针 |
| 删除尾节点 | O(n) | O(1) | 需遍历到倒数第二个节点 |
| 删除指定位置 | O(n) | O(1) | 需遍历到位置前 |
| 按值删除 | O(n) | O(1) | 需遍历查找值 |
✅ 一句话总结:
链表插入与删除的核心是找到目标位置的前一个节点,然后修改 next 指针。头部操作最快,尾部和中间操作需要遍历。
-
跳表的原理与应用场景?
1. 跳表的原理
跳表是一种 基于多层有序链表 的数据结构,用来实现 快速查找、插入、删除。
它的核心思想是:
- 在普通有序链表的基础上,增加多层“索引”链表
- 每一层都是下一层的子集,节点数逐层减少
- 通过高层索引快速跳过大量节点,从而降低查找时间复杂度
结构示意:
Level 3: 1 --------- 9 --------- 17 Level 2: 1 ---- 5 ---- 9 ---- 13 ---- 17 Level 1: 1 - 3 - 5 - 7 - 9 - 11 - 13 - 15 - 17
查找时:
- 从最高层开始,沿着索引链表向右移动
- 如果下一个节点的值大于目标值,则向下一层移动
- 重复直到到达最底层,找到目标节点
2. 跳表的时间复杂度
- 查找:O(logn)
- 插入:O(logn)(需要更新多层索引)
- 删除:O(logn)
- 空间复杂度:O(n)(多层索引占用额外空间)
3. 跳表的特点
- 有序结构:天然支持范围查询
- 随机化算法:节点提升到高层的概率通常是 1/21/2
- 实现简单:比平衡树(如红黑树、AVL 树)更容易实现
- 性能稳定:平均时间复杂度接近平衡树,但常数因子更小
4. 应用场景
跳表在很多高性能系统中都有应用,尤其是需要 有序数据 + 快速查找 的场景:
| 应用场景 | 说明 |
|---|---|
| Redis 有序集合(Sorted Set) | Redis 使用跳表实现有序集合的范围查询和排名功能 |
| 数据库索引 | 一些数据库(如 LevelDB)在内部使用跳表作为索引结构 |
| 内存缓存系统 | 需要快速插入、删除、查找的有序数据结构 |
| 排名系统 | 游戏排行榜、积分排名等需要快速获取前 N 名或某个范围的用户 |
| 区间查询 | 例如查找某个时间范围内的日志记录 |
5. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 实现简单,比平衡树容易 | 需要额外空间存储多层索引 |
| 查找、插入、删除平均 O(logn) | 最坏情况可能退化为 O(n)(概率极低) |
| 支持范围查询 | 需要随机化算法保证性能稳定 |
✅ 一句话总结:
跳表通过多层索引加速有序链表的查找、插入和删除,性能接近平衡树,但实现更简单,广泛应用于 Redis、数据库索引和排名系统。
-
链表与数组的优缺点对比?
1. 基本概念
- 数组(Array):一块连续的内存空间,通过索引直接访问元素。
- 链表(Linked List):由一系列节点组成,每个节点包含数据和指向下一个节点的指针(单链表)或前后指针(双链表)。
2. 优缺点对比表
| 对比维度 | 数组(Array) | 链表(Linked List) |
|---|---|---|
| 内存分配 | 连续内存,分配时需确定大小 | 分散内存,动态分配,大小可变 |
| 访问速度 | O(1),可通过索引直接访问 | O(n),需从头遍历到目标位置 |
| 插入/删除(中间位置) | O(n),需移动大量元素 | O(1)(已知节点指针时),只需修改指针 |
| 插入/删除(尾部) | 尾插 O(1)(已知长度),尾删 O(1)(动态数组可能 O(n)) | 单链表尾插 O(n)(无尾指针),双链表尾插 O(1) |
| 空间利用率 | 无额外指针开销,空间利用率高 | 每个节点需额外存储指针,空间利用率低 |
| 缓存友好性 | 高(连续内存,CPU 缓存命中率高) | 低(节点分散,缓存命中率低) |
| 扩容成本 | 需要整体搬迁数据,成本高 | 无需扩容,动态增长 |
| 随机访问 | 支持 | 不支持 |
| 顺序遍历 | 高效 | 相对较慢 |
3. 适用场景
-
数组适合:
- 数据量已知且变化不大
- 需要频繁随机访问
- 对缓存性能要求高的场景(如数值计算、图像处理)
-
链表适合:
- 数据量变化频繁
- 需要频繁在中间插入/删除
- 内存分配不连续的场景
4. 总结
- 数组:访问快、缓存友好,但插入删除慢、扩容成本高
- 链表:插入删除快(已知位置),但访问慢、空间开销大
✅ 一句话记忆:
“查找用数组,插删用链表”(前提是链表操作位置已知,否则查找成本高)。
三、栈(Stack)与队列(Queue)
栈
-
栈的特点是什么?
1. 栈的定义
栈是一种 线性数据结构,遵循 后进先出(LIFO, Last In First Out) 的原则。
- 后进先出:最后压入栈的元素最先被弹出
- 常见操作:
- push:入栈(压入元素)
- pop:出栈(弹出元素)
- peek / top:查看栈顶元素但不移除
2. 栈的主要特点
- 访问受限
- 只能访问栈顶元素,不能直接访问中间或底部元素
- 操作简单
- 只涉及栈顶的插入和删除,逻辑清晰
- 顺序性
- 元素按压入顺序排列,出栈顺序与入栈顺序相反
- 实现方式多样
- 可以用 数组 或 链表 实现
- 时间复杂度稳定
- 入栈、出栈、取栈顶操作都是 O(1)
- 空间可动态变化
- 链表实现可动态扩展,数组实现可能需要扩容
3. 栈的常见应用场景
- 函数调用栈:记录函数调用顺序和返回地址
- 表达式求值:如中缀转后缀、括号匹配
- 撤销/回退功能:如编辑器的撤销操作
- 深度优先搜索(DFS):递归或显式栈实现
- 浏览器历史记录:后退功能
4. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 操作简单,效率高 | 访问范围受限,只能操作栈顶 |
| 时间复杂度稳定 O(1) | 不适合频繁访问中间元素 |
| 逻辑清晰,易于实现 | 容量固定时可能溢出(数组实现) |
✅ 一句话总结:
栈是一种后进先出的线性结构,只能在栈顶进行插入和删除,适合处理具有“逆序”特性的任务。
-
栈的应用场景有哪些?
1. 栈的核心特性回顾
- 后进先出(LIFO):最后入栈的元素最先出栈
- 只能在栈顶进行插入和删除
- 操作时间复杂度:入栈、出栈、取栈顶都是 �(1)O(1)
2. 栈的常见应用场景
2.1 函数调用与递归
- 原理:程序运行时使用调用栈保存函数的返回地址、局部变量等信息
- 例子:
- 递归函数调用(如阶乘、斐波那契数列)
- 操作系统的函数调用管理
2.2 表达式求值与括号匹配
- 原理:利用栈保存操作符或括号,按优先级或匹配规则处理
- 例子:
- 中缀表达式转后缀表达式(逆波兰表达式)
- 括号匹配检测(
( [ { } ] ))
2.3 撤销(Undo)与回退(Backtracking)
- 原理:将每一步操作压入栈,撤销时弹出最近的操作
- 例子:
- 文本编辑器的撤销功能
- Photoshop 的历史记录
- 浏览器的后退功能
2.4 深度优先搜索(DFS)
- 原理:DFS 可以用递归(隐式调用栈)或显式栈实现
- 例子:
- 图的遍历
- 迷宫求解
2.5 逆序输出
- 原理:利用栈的 LIFO 特性反转数据顺序
- 例子:
- 字符串反转
- 链表反转(借助栈)
2.6 浏览器历史记录
- 原理:
- 后退栈:保存访问过的页面
- 前进栈:保存从后退操作中弹出的页面
3. 总结表
| 应用场景 | 栈的作用 |
|---|---|
| 函数调用栈 | 保存返回地址和局部变量 |
| 表达式求值 | 存储操作符和操作数 |
| 括号匹配 | 检查括号是否成对出现 |
| 撤销/回退 | 保存历史操作记录 |
| DFS 搜索 | 存储待访问节点 |
| 数据逆序 | 利用 LIFO 特性反转数据 |
| 浏览器历史 | 管理前进/后退页面 |
✅ 一句话总结:
栈适合处理“后进先出”的问题,尤其是需要回溯、撤销、匹配、逆序的场景。
-
如何用数组实现栈?
用数组实现栈的核心是:
- 用一个数组存储栈中的元素
- 用一个变量
top记录栈顶位置 - 入栈(push):将元素放到
top+1位置,并更新top - 出栈(pop):返回
top位置的元素,并将top减 1 - 判空 / 判满:
- 栈空:
top == -1 - 栈满:
top == capacity - 1
- 栈空:
2. 关键点
- 数组大小固定(静态栈),如果需要动态扩容,可以在满栈时创建更大的数组并复制数据
- 时间复杂度:
- 入栈:O(1)
- 出栈:O(1)
- 取栈顶:O(1)
3. Java 实现示例
public class ArrayStack {
private int[] stack; // 存储栈元素的数组
private int top; // 栈顶指针
private int capacity; // 栈容量
// 构造函数
public ArrayStack(int capacity) {
this.capacity = capacity;
stack = new int[capacity];
top = -1; // 栈为空
}
// 入栈
public void push(int value) {
if (isFull()) {
throw new RuntimeException("栈已满,无法入栈");
}
stack[++top] = value;
}
// 出栈
public int pop() {
if (isEmpty()) {
throw new RuntimeException("栈为空,无法出栈");
}
return stack[top--];
}
// 查看栈顶元素
public int peek() {
if (isEmpty()) {
throw new RuntimeException("栈为空");
}
return stack[top];
}
// 判断栈是否为空
public boolean isEmpty() {
return top == -1;
}
// 判断栈是否已满
public boolean isFull() {
return top == capacity - 1;
}
}
4. 使用示例
public class Main {
public static void main(String[] args) {
ArrayStack stack = new ArrayStack(5);
stack.push(10);
stack.push(20);
stack.push(30);
System.out.println(stack.peek()); // 输出 30
System.out.println(stack.pop()); // 输出 30
System.out.println(stack.pop()); // 输出 20
System.out.println(stack.isEmpty()); // false
}
}
5. 总结
- 优点:实现简单,访问速度快(数组索引直接访问)
- 缺点:容量固定,可能浪费空间或溢出
- 适用场景:栈大小已知且变化不大
-
如何用链表实现栈?
1. 思路分析
用链表实现栈的核心是:
- 用链表的头节点作为栈顶(也可以用尾节点,但头节点更高效)
- 入栈(push):在链表头部插入新节点
- 出栈(pop):删除链表头部节点并返回其值
- 判空:链表为空即栈为空
2. 为什么用链表实现栈
- 优点:
- 不需要预先分配固定容量
- 入栈、出栈操作都是 O(1)
- 缺点:
- 每个节点需要额外存储指针,空间利用率低
- 内存分配频繁,可能影响性能
3. Java 实现示例
public class LinkedListStack {
// 定义链表节点
private static class Node {
int data;
Node next;
Node(int data) {
this.data = data;
}
}
private Node top; // 栈顶指针
// 入栈
public void push(int value) {
Node newNode = new Node(value);
newNode.next = top; // 新节点指向原栈顶
top = newNode; // 更新栈顶
}
// 出栈
public int pop() {
if (isEmpty()) {
throw new RuntimeException("栈为空,无法出栈");
}
int value = top.data;
top = top.next; // 栈顶指针下移
return value;
}
// 查看栈顶元素
public int peek() {
if (isEmpty()) {
throw new RuntimeException("栈为空");
}
return top.data;
}
// 判断栈是否为空
public boolean isEmpty() {
return top == null;
}
}
4. 使用示例
public class Main {
public static void main(String[] args) {
LinkedListStack stack = new LinkedListStack();
stack.push(10);
stack.push(20);
stack.push(30);
System.out.println(stack.peek()); // 输出 30
System.out.println(stack.pop()); // 输出 30
System.out.println(stack.pop()); // 输出 20
System.out.println(stack.isEmpty()); // false
}
}
5. 总结
- 链表实现栈:
- 入栈:在链表头插入节点
- 出栈:删除链表头节点
- 优点:容量动态变化,不会溢出
- 缺点:额外指针占用空间,内存分配频繁
-
如何用两个栈实现队列?
1. 思路分析
队列的特点是 先进先出(FIFO),而栈是 后进先出(LIFO)。
我们可以用两个栈来模拟队列的行为:
- 栈 A(inStack):负责入队操作
- 栈 B(outStack):负责出队操作
核心思想:
- 入队时,直接把元素压入 栈 A
- 出队时,如果 栈 B 为空,就把 栈 A 中的所有元素依次弹出并压入 栈 B(这样顺序就反转了,最早入队的元素在栈 B 顶部)
- 然后从 栈 B 弹出元素作为出队结果
2. 操作流程
入队(enqueue)
- 直接
push到 栈 A
出队(dequeue)
- 如果 栈 B 不为空,直接
pop栈 B - 如果 栈 B 为空:
- 将 栈 A 中所有元素
pop出并push到 栈 B - 再从 栈 B
pop出一个元素
- 将 栈 A 中所有元素
3. 时间复杂度
- 入队:O(1)
- 出队:平均 O(1)(摊还分析),最坏情况 O(n)(当栈 B 为空且需要搬运所有元素时)
4. Java 实现示例
import java.util.Stack;
public class QueueWithTwoStacks {
private Stack<Integer> inStack = new Stack<>();
private Stack<Integer> outStack = new Stack<>();
// 入队
public void enqueue(int value) {
inStack.push(value);
}
// 出队
public int dequeue() {
if (isEmpty()) {
throw new RuntimeException("队列为空,无法出队");
}
if (outStack.isEmpty()) {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
return outStack.pop();
}
// 查看队头元素
public int peek() {
if (isEmpty()) {
throw new RuntimeException("队列为空");
}
if (outStack.isEmpty()) {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
return outStack.peek();
}
// 判断队列是否为空
public boolean isEmpty() {
return inStack.isEmpty() && outStack.isEmpty();
}
}
5. 使用示例
public class Main {
public static void main(String[] args) {
QueueWithTwoStacks queue = new QueueWithTwoStacks();
queue.enqueue(10);
queue.enqueue(20);
queue.enqueue(30);
System.out.println(queue.dequeue()); // 输出 10
System.out.println(queue.peek()); // 输出 20
System.out.println(queue.dequeue()); // 输出 20
System.out.println(queue.isEmpty()); // false
}
}
6. 总结
- 栈 A:负责入队
- 栈 B:负责出队
- 关键操作:当栈 B 为空时,把栈 A 的所有元素搬到栈 B
- 优点:用栈实现队列,逻辑清晰,代码简单
- 缺点:出队在某些情况下需要一次性搬运大量数据
队列
-
队列的特点是什么?
1. 队列的定义
队列是一种 线性数据结构,遵循 先进先出(FIFO, First In First Out) 的原则。
- 先进先出:最先进入队列的元素最先被移出
- 常见操作:
- enqueue:入队(在队尾插入元素)
- dequeue:出队(从队头移除元素)
- peek / front:查看队头元素但不移除
2. 队列的主要特点
- 访问受限
- 只能在队尾插入元素,在队头删除元素
- 顺序性
- 元素按进入队列的顺序排列,出队顺序与入队顺序一致
- 实现方式多样
- 可以用 数组、链表、循环数组 实现
- 时间复杂度稳定
- 入队、出队、取队头操作都是 O(1)
- 容量可动态变化
- 链表实现可动态扩展,数组实现可能需要扩容
3. 队列的常见应用场景
- 任务调度:如操作系统的进程调度
- 消息队列:如 RabbitMQ、Kafka
- 数据缓冲:如 IO 缓冲区
- 广度优先搜索(BFS):图或树的层序遍历
- 打印任务管理:按提交顺序打印
4. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 操作简单,逻辑清晰 | 访问范围受限,只能操作队头和队尾 |
| 时间复杂度稳定 O(1) | 不适合频繁访问中间元素 |
| 适合顺序处理任务 | 容量固定时可能溢出(数组实现) |
✅ 一句话总结:
队列是一种先进先出的线性结构,只能在队尾插入、队头删除,适合顺序处理任务的场景。
-
普通队列与循环队列的区别?
1. 普通队列
特点
- 用数组或链表实现
- 队尾指针不断向后移动,出队后队头指针向前移动
- 如果用数组实现,出队后队头前面的空间不能再利用(除非移动数据)
缺点
- 数组实现时会浪费空间:即使队列中还有空位,只要队尾指针到达数组末尾,就不能再入队
- 需要数据搬移才能复用空间,搬移操作是 O(n)
2. 循环队列
特点
- 用数组实现,但将数组逻辑上看成一个 环形结构
- 队尾指针到达数组末尾后,可以回到数组开头继续使用空闲空间
- 队满条件:
(rear + 1) % capacity == front - 队空条件:
front == rear
优点
- 空间利用率高:不会浪费出队后的空位
- 入队、出队操作都是 O(1)
- 不需要数据搬移
3. 对比表
| 对比项 | 普通队列 | 循环队列 |
|---|---|---|
| 空间利用率 | 低(数组实现时可能浪费空间) | 高(可复用出队后的空位) |
| 实现复杂度 | 简单 | 略复杂(需要取模运算) |
| 入队效率 | O(1)(链表实现) / 可能 O(n)(数组搬移) | O(1) |
| 出队效率 | O(1) | O(1) |
| 是否需要数据搬移 | 数组实现时需要 | 不需要 |
| 适用场景 | 数据量小、实现简单的场景 | 高性能、空间有限的场景 |
✅ 一句话总结:
普通队列在数组实现时可能浪费空间,而循环队列通过环形结构复用空位,空间利用率更高,适合高性能场景。
-
如何用数组实现队列?
1. 思路分析
用数组实现队列的核心是:
- 用一个数组存储队列元素
- 用两个指针:
front:指向队头元素的位置rear:指向队尾元素的下一个位置(方便插入)
- 入队(enqueue):在
rear位置插入元素,然后rear++ - 出队(dequeue):返回
front位置的元素,然后front++ - 判空 / 判满:
- 队空:
front == rear - 队满(普通队列):
rear == capacity(数组末尾)
- 队空:
2. 普通队列的缺点
- 如果用数组实现普通队列,出队后前面的空间不能复用,可能造成浪费
- 解决方法:可以用 循环队列(
(rear + 1) % capacity)来复用空间
3. Java 普通队列实现示例
public class ArrayQueue {
private int[] queue; // 存储队列元素的数组
private int front; // 队头指针
private int rear; // 队尾指针
private int capacity; // 队列容量
// 构造函数
public ArrayQueue(int capacity) {
this.capacity = capacity;
queue = new int[capacity];
front = 0;
rear = 0;
}
// 入队
public void enqueue(int value) {
if (isFull()) {
throw new RuntimeException("队列已满,无法入队");
}
queue[rear++] = value;
}
// 出队
public int dequeue() {
if (isEmpty()) {
throw new RuntimeException("队列为空,无法出队");
}
return queue[front++];
}
// 查看队头元素
public int peek() {
if (isEmpty()) {
throw new RuntimeException("队列为空");
}
return queue[front];
}
// 判断队列是否为空
public boolean isEmpty() {
return front == rear;
}
// 判断队列是否已满
public boolean isFull() {
return rear == capacity;
}
}
4. 使用示例
public class Main {
public static void main(String[] args) {
ArrayQueue queue = new ArrayQueue(5);
queue.enqueue(10);
queue.enqueue(20);
queue.enqueue(30);
System.out.println(queue.dequeue()); // 输出 10
System.out.println(queue.peek()); // 输出 20
System.out.println(queue.dequeue()); // 输出 20
System.out.println(queue.isEmpty()); // false
}
}
5. 总结
- 普通队列用数组实现简单,但可能浪费空间
- 循环队列可以复用出队后的空位,空间利用率更高
- 入队、出队操作都是 O(1)
-
如何用链表实现队列?
1. 思路分析
用链表实现队列的核心是:
- 用链表存储队列元素
- 维护两个指针:
front:指向队头节点(出队位置)rear:指向队尾节点(入队位置)
- 入队(enqueue):在链表尾部插入新节点
- 出队(dequeue):删除链表头部节点并返回其值
- 判空:
front == null表示队列为空
2. 为什么用链表实现队列
- 优点:
- 不需要预先分配固定容量
- 入队、出队操作都是 �(1)O(1)
- 缺点:
- 每个节点需要额外存储指针,空间利用率低
- 内存分配频繁,可能影响性能
3. Java 实现示例
public class LinkedListQueue {
// 定义链表节点
private static class Node {
int data;
Node next;
Node(int data) {
this.data = data;
}
}
private Node front; // 队头指针
private Node rear; // 队尾指针
// 入队
public void enqueue(int value) {
Node newNode = new Node(value);
if (rear == null) { // 队列为空
front = rear = newNode;
} else {
rear.next = newNode; // 原队尾指向新节点
rear = newNode; // 更新队尾
}
}
// 出队
public int dequeue() {
if (isEmpty()) {
throw new RuntimeException("队列为空,无法出队");
}
int value = front.data;
front = front.next; // 队头指针下移
if (front == null) { // 队列变空
rear = null;
}
return value;
}
// 查看队头元素
public int peek() {
if (isEmpty()) {
throw new RuntimeException("队列为空");
}
return front.data;
}
// 判断队列是否为空
public boolean isEmpty() {
return front == null;
}
}
4. 使用示例
public class Main {
public static void main(String[] args) {
LinkedListQueue queue = new LinkedListQueue();
queue.enqueue(10);
queue.enqueue(20);
queue.enqueue(30);
System.out.println(queue.dequeue()); // 输出 10
System.out.println(queue.peek()); // 输出 20
System.out.println(queue.dequeue()); // 输出 20
System.out.println(queue.isEmpty()); // false
}
}
5. 总结
- 链表实现队列:
- 入队:在链表尾插入节点
- 出队:删除链表头节点
- 优点:容量动态变化,不会溢出
- 缺点:额外指针占用空间,内存分配频繁
-
双端队列(Deque)的原理与应用?
1. 原理
双端队列(Deque, Double-Ended Queue) 是一种 可以在队列两端进行插入和删除 的线性数据结构。
它结合了 队列 和 栈 的特性:
- 队列:可以从队头删除,从队尾插入
- 栈:可以从队尾删除,从队尾插入
- 双端队列:既可以从队头插入/删除,也可以从队尾插入/删除
常见操作
addFirst(e)/offerFirst(e):在队头插入元素addLast(e)/offerLast(e):在队尾插入元素removeFirst()/pollFirst():删除队头元素removeLast()/pollLast():删除队尾元素peekFirst():查看队头元素peekLast():查看队尾元素
2. 实现方式
- 数组实现(循环数组):通过取模运算实现队头、队尾的循环移动
- 链表实现(双向链表):队头和队尾都有指针,插入和删除都是 �(1)O(1)
3. 应用场景
- 滑动窗口问题
- 在算法中(如最大值/最小值滑动窗口),双端队列可以高效维护窗口内的元素顺序
- 任务调度
- 可以灵活地从两端添加或移除任务
- 回文检测
- 从两端取元素进行比较
- 浏览器历史记录
- 前进和后退操作可以用双端队列实现
- 缓存系统
- LRU(最近最少使用)缓存可以用双端队列管理数据
4. Java 示例
import java.util.Deque;
import java.util.LinkedList;
public class DequeExample {
public static void main(String[] args) {
Deque<Integer> deque = new LinkedList<>();
// 从队尾插入
deque.addLast(10);
deque.addLast(20);
// 从队头插入
deque.addFirst(5);
System.out.println(deque); // [5, 10, 20]
// 从队头删除
deque.removeFirst(); // 删除 5
System.out.println(deque); // [10, 20]
// 从队尾删除
deque.removeLast(); // 删除 20
System.out.println(deque); // [10]
}
}
5. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 插入、删除灵活,可在两端操作 | 实现比普通队列复杂 |
| 适合双向访问的场景 | 数组实现需要额外处理循环逻辑 |
| 可替代栈和队列 | 链表实现占用额外指针空间 |
✅ 一句话总结:
双端队列是一种可以在队头和队尾都进行插入和删除的结构,灵活性高,适合滑动窗口、任务调度等双向访问场景。
-
优先队列的原理与应用?
1. 原理
优先队列 是一种 按照元素优先级顺序出队 的队列结构,不是按照先进先出(FIFO)。
- 每个元素都有一个 优先级(Priority)
- 出队时,总是先取出 优先级最高(或最低,取决于实现方式)的元素
- 常用实现方式:
- 堆(Heap):最常见,通常用 二叉堆 实现,入队和出队的时间复杂度都是 O(logn)
- 有序链表:入队 O(n),出队 O(1)
- 无序链表:入队 O(1),出队 O(n)
2. 核心操作
- 插入(enqueue):将元素放入队列,并根据优先级调整位置
- 删除(dequeue):取出优先级最高的元素
- 查看队头(peek):查看当前优先级最高的元素,但不删除
3. 应用场景
- 任务调度
- 操作系统根据任务优先级分配 CPU 时间片
- Dijkstra 最短路径算法
- 使用优先队列快速找到当前距离最小的节点
- A* 搜索算法
- 根据估价函数优先访问最有可能到达目标的节点
- 事件驱动模拟
- 按事件发生时间顺序处理事件
- 带权作业调度
- 按权重(优先级)安排作业执行顺序
4. Java 示例(基于堆实现)
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 默认是小顶堆(优先级小的先出队)
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.offer(30);
pq.offer(10);
pq.offer(20);
System.out.println(pq.poll()); // 输出 10(最小值)
System.out.println(pq.poll()); // 输出 20
System.out.println(pq.poll()); // 输出 30
}
}
5. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 按优先级自动排序,出队效率高 | 无法像普通队列那样保证 FIFO |
| 堆实现入队/出队效率 O(logn) | 需要额外的比较逻辑 |
| 适合动态变化的优先级任务 | 不适合频繁修改优先级的场景(需要重建堆) |
✅ 一句话总结:
优先队列是一种按照优先级出队的队列,常用堆实现,适合任务调度、路径搜索等需要动态选择最高优先级元素的场景。
-
单调队列的原理与应用?
1. 原理
单调队列 是一种 队列内元素保持单调递增或单调递减 的特殊队列结构。
它的核心思想是:
- 在队列中只保留对结果有用的元素
- 每次入队时,从队尾移除不符合单调性的元素
- 出队时,正常从队头移除元素(通常是窗口滑动时移除过期元素)
两种类型
- 单调递增队列:队列中的元素从队头到队尾递增
- 队头是最小值
- 单调递减队列:队列中的元素从队头到队尾递减
- 队头是最大值
2. 核心操作
- 入队(push):
- 在队尾插入新元素前,移除队尾所有比新元素更“劣”的元素(不符合单调性)
- 出队(pop):
- 如果队头元素已经不在当前窗口范围内,就移除它
- 取值(front):
- 队头元素就是当前窗口的最值(最大或最小)
3. 应用场景
- 滑动窗口最大值 / 最小值
- 例如:给定一个数组和窗口大小 �k,快速求每个窗口的最大值
- 股票价格分析
- 快速获取一段时间内的最高/最低价格
- 动态区间最值查询
- 在数据流中实时维护区间最值
- 最短路径优化
- 某些图算法中用单调队列优化 BFS
4. 示例:滑动窗口最大值(Java)
import java.util.*;
public class MonotonicQueue {
Deque<Integer> deque = new LinkedList<>();
// 入队(保持单调递减)
public void push(int value) {
while (!deque.isEmpty() && deque.getLast() < value) {
deque.removeLast();
}
deque.addLast(value);
}
// 出队(如果队头是要移除的元素)
public void pop(int value) {
if (!deque.isEmpty() && deque.getFirst() == value) {
deque.removeFirst();
}
}
// 获取当前最大值
public int max() {
return deque.getFirst();
}
public static void main(String[] args) {
MonotonicQueue mq = new MonotonicQueue();
int[] nums = {1, 3, -1, -3, 5, 3, 6, 7};
int k = 3;
List<Integer> res = new ArrayList<>();
for (int i = 0; i < nums.length; i++) {
mq.push(nums[i]);
if (i >= k - 1) {
res.add(mq.max());
mq.pop(nums[i - k + 1]);
}
}
System.out.println(res); // 输出 [3, 3, 5, 5, 6, 7]
}
}
5. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 在滑动窗口场景中可 O(1) 获取最值 | 仅适用于单调性需求的场景 |
| 入队、出队均为 O(1) 均摊 | 实现逻辑比普通队列复杂 |
| 节省计算时间,避免重复比较 | 不适合需要随机访问的场景 |
✅ 一句话总结:
单调队列是一种保持队列元素单调性的结构,常用于滑动窗口最值问题,能在 �(1)O(1) 时间获取当前窗口的最大或最小值。
四、哈希表(Hash Table)
-
哈希表的原理是什么?
1. 原理概述
哈希表 是一种基于 哈希函数(Hash Function) 的数据结构,主要用于 快速存储和查找键值对(Key-Value)。
它的核心思想是:
- 通过哈希函数将键映射到数组的索引位置
- 在该位置存储对应的值
- 查找时,直接通过哈希函数计算索引,O(1) 时间即可找到数据
2. 核心组成
-
哈希函数
- 输入:键(Key)
- 输出:数组索引(Index)
- 要求:计算速度快、分布均匀、尽量减少冲突
- 示例:
index = key.hashCode() % capacity
-
数组(存储桶)
- 存储键值对的容器
- 每个位置可能存储一个或多个元素(冲突时)
-
冲突处理
哈希函数可能会将不同的键映射到同一个索引,这就是 哈希冲突。常见解决方法:- 链地址法(Separate Chaining):每个桶用链表或其他结构存储多个元素
- 开放地址法(Open Addressing):冲突时寻找下一个空位置(如线性探测、二次探测)
3. 操作流程
插入(Put)
- 计算键的哈希值
- 将哈希值映射到数组索引
- 如果该位置为空,直接插入
- 如果该位置已有元素(冲突),使用冲突处理策略插入
查找(Get)
- 计算键的哈希值
- 找到对应索引位置
- 如果有多个元素,遍历查找匹配的键
删除(Remove)
- 计算键的哈希值
- 找到对应索引位置
- 删除匹配的键值对,并调整结构(防止查找失败)
4. Java 示例(链地址法)
import java.util.*;
public class SimpleHashTable<K, V> {
private static class Entry<K, V> {
K key;
V value;
Entry<K, V> next;
Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
private Entry<K, V>[] table;
private int capacity;
public SimpleHashTable(int capacity) {
this.capacity = capacity;
table = new Entry[capacity];
}
private int hash(K key) {
return Math.abs(key.hashCode()) % capacity;
}
public void put(K key, V value) {
int index = hash(key);
Entry<K, V> newEntry = new Entry<>(key, value);
if (table[index] == null) {
table[index] = newEntry;
} else {
Entry<K, V> current = table[index];
while (current.next != null) {
if (current.key.equals(key)) {
current.value = value;
return;
}
current = current.next;
}
current.next = newEntry;
}
}
public V get(K key) {
int index = hash(key);
Entry<K, V> current = table[index];
while (current != null) {
if (current.key.equals(key)) {
return current.value;
}
current = current.next;
}
return null;
}
}
5. 优缺点对比
| 优点 | 缺点 |
|---|---|
| 查找、插入、删除平均时间复杂度 O(1) | 哈希冲突可能导致性能下降 |
| 适合快速定位数据 | 哈希函数设计不当会影响效率 |
| 实现简单,扩展性强 | 需要额外空间存储桶和链表 |
✅ 一句话总结:
哈希表通过哈希函数将键映射到数组索引,实现快速查找、插入和删除,平均时间复杂度为 O(1),但需要合理处理哈希冲突。
-
哈希函数的设计原则?
1. 哈希函数的作用
哈希函数的任务是:
将任意大小的输入(键)映射为固定范围的整数索引,用于在哈希表中定位数据。
一个好的哈希函数能让哈希表的查找、插入、删除保持接近 O(1) 的效率。
2. 设计原则
(1) 计算速度快
- 哈希函数会在每次插入、查找时调用,所以必须高效。
- 不能使用复杂的运算(如大量循环、递归),应尽量用简单的算术运算和位运算。
(2) 分布均匀
- 哈希值应尽量均匀分布在整个索引范围内,避免大量元素集中在某几个桶中。
- 均匀分布可以减少哈希冲突,提高性能。
(3) 确定性
- 对同一个输入,哈希函数必须始终返回相同的哈希值。
- 不能有随机性,否则查找会失败。
(4) 最小化冲突
- 不同的键尽量产生不同的哈希值。
- 虽然冲突不可避免,但应尽量减少。
(5) 考虑输入特性
- 针对不同类型的键(字符串、整数、对象),选择合适的哈希策略。
- 例如:
- 整数:可以直接取模
- 字符串:可以使用多项式哈希(Polynomial Hash)
(6) 适应表容量变化
- 哈希函数应能适应哈希表容量的变化(扩容时重新计算索引)。
- 常用做法:
index = hashCode % capacity
3. 常见哈希函数示例
整数键
int hash(int key, int capacity) {
return Math.abs(key) % capacity;
}
字符串键(多项式哈希)
int hash(String key, int capacity) {
int hash = 0;
int p = 31; // 质数
for (int i = 0; i < key.length(); i++) {
hash = (hash * p + key.charAt(i)) % capacity;
}
return hash;
}
4. 设计哈希函数时的注意事项
- 避免简单取模:如果键的分布有规律,简单取模可能导致冲突集中。
- 使用质数容量:哈希表容量最好是质数,减少模式冲突。
- 混合位运算:适当使用位移、异或等运算,让哈希值更分散。
- 防止溢出:在计算过程中注意整数溢出问题。
5. 总结表
| 设计原则 | 说明 |
|---|---|
| 计算速度快 | 哈希函数应尽量简单高效 |
| 分布均匀 | 哈希值应均匀覆盖索引范围 |
| 确定性 | 相同输入必须得到相同输出 |
| 最小化冲突 | 不同输入尽量产生不同哈希值 |
| 考虑输入特性 | 针对不同数据类型选择合适算法 |
| 适应容量变化 | 扩容时能重新计算索引 |
✅ 一句话总结:
一个好的哈希函数应计算快速、分布均匀、确定性强,并尽量减少冲突,同时适应不同数据类型和容量变化。
-
哈希冲突的解决方法有哪些?
1. 什么是哈希冲突
哈希冲突 指的是 不同的键(Key)经过哈希函数计算后得到相同的索引值,导致它们需要存储在同一个位置。
由于哈希表的索引范围有限,冲突是不可避免的,所以必须设计合理的解决策略。
2. 常见解决方法
(1) 链地址法(Separate Chaining)
- 原理:每个桶(索引位置)存储一个链表(或其他结构),冲突的元素依次插入链表中。
- 优点:
- 实现简单
- 扩容时只需重新分配桶
- 缺点:
- 链表过长会影响性能
- 需要额外的指针空间
- 示意:
index 0 → [Key1, Value1] → [Key2, Value2] index 1 → [Key3, Value3]
(2) 开放地址法(Open Addressing)
- 原理:冲突时,在数组中寻找下一个空位置存储元素。
- 常见探测方式:
- 线性探测(Linear Probing)
- 按顺序查找下一个空位置
- 公式:
index = (hash + i) % capacity
- 二次探测(Quadratic Probing)
- 按平方间隔查找空位置
- 公式:
index = (hash + i^2) % capacity
- 双重哈希(Double Hashing)
- 使用第二个哈希函数计算步长
- 公式:
index = (hash1 + i * hash2(key)) % capacity
- 线性探测(Linear Probing)
- 优点:
- 不需要额外链表结构
- 缺点:
- 删除元素需要特殊标记(避免查找失败)
- 容量利用率受限
(3) 再哈希法(Rehashing)
- 原理:冲突时,使用另一个哈希函数重新计算索引。
- 优点:
- 分布更均匀
- 缺点:
- 需要多个哈希函数
- 计算开销增加
(4) 建立公共溢出区
- 原理:为所有桶建立一个公共的溢出存储区,冲突的元素统一放入溢出区。
- 优点:
- 管理简单
- 缺点:
- 溢出区可能变成线性查找,性能下降
3. 方法对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 链地址法 | 实现简单,扩容方便 | 链表过长影响性能 | 常用,Java HashMap 默认使用 |
| 开放地址法 | 无额外结构 | 删除复杂,负载因子低 | 内存紧张时 |
| 再哈希法 | 分布均匀 | 计算开销大 | 高冲突率场景 |
| 公共溢出区 | 管理简单 | 溢出区性能差 | 数据量小且冲突少 |
✅ 一句话总结:
哈希冲突不可避免,常用解决方法有链地址法、开放地址法、再哈希法和公共溢出区,其中链地址法最常用,开放地址法适合内存紧张的场景。
-
哈希表的时间复杂度分析?
1. 基本操作
哈希表主要支持以下三种核心操作:
- 插入(Insert / Put)
- 查找(Search / Get)
- 删除(Delete / Remove)
2. 时间复杂度分析
(1) 平均情况
在 哈希函数分布均匀 且 冲突较少 的情况下:
- 插入:O(1)
- 查找:O(1)
- 删除:O(1)
原因:
- 通过哈希函数直接计算索引,定位到桶的位置
- 冲突少时,桶内元素数量接近常数级,遍历耗时可忽略
(2) 最坏情况
在 哈希冲突严重 的情况下:
- 链地址法:桶内链表可能退化成长度为 n 的链表,时间复杂度变为 O(n)
- 开放地址法:可能需要探测整个表才能找到空位或目标元素,时间复杂度也可能退化到 O(n)
(3) 空间复杂度
- 哈希表需要额外的存储桶(数组)和冲突处理结构(链表或探测标记)
- 空间复杂度通常为 O(n),但会比存储数据本身多一些额外开销
3. 负载因子(Load Factor)对性能的影响
负载因子 定义为:
=元素个数桶的数量α=桶的数量元素个数
- 当 α 较小(如 < 0.75)时,冲突少,性能接近 O(1)
- 当 α 较大时,冲突增多,性能下降
- 解决方法:扩容(Rehashing),增加桶数量并重新分配元素
4. 时间复杂度对比表
| 操作 | 平均时间复杂度 | 最坏时间复杂度 | 说明 |
|---|---|---|---|
| 插入 | O(1) | O(n) | 冲突严重时退化 |
| 查找 | O(1) | O(n) | 链表/探测全表 |
| 删除 | O(1) | O(n) | 同查找 |
| 扩容 | O(n) | O(n) | 需要重新哈希所有元素 |
5. 总结
- 平均性能:哈希表的插入、查找、删除都是 O(1)
- 最坏性能:冲突严重时退化到 O(n)
- 关键影响因素:
- 哈希函数的均匀性
- 冲突处理策略
- 负载因子控制
✅ 一句话总结:
哈希表在平均情况下能实现 O(1) 的插入、查找和删除,但在冲突严重时可能退化到 O(n),因此需要合理设计哈希函数并控制负载因子。
-
如何实现 LRU 缓存?
1. LRU 缓存的原理
LRU 缓存 是一种常用的缓存淘汰策略:
- 当缓存满了,需要删除最近最少使用的元素(即最长时间没有被访问的元素)。
- 这样可以保证缓存中保留的是最近访问频率较高的数据,提高命中率。
2. 核心需求
- 快速查找(通过键获取值) → 需要 哈希表
- 快速更新访问顺序 → 需要 双向链表
- 快速删除最旧元素 → 双向链表的尾部删除
3. 数据结构设计
- 哈希表(HashMap):存储键到链表节点的映射,查找时间 O(1)
- 双向链表(Doubly Linked List):
- 头部:最近访问的元素
- 尾部:最久未访问的元素
- 插入、删除节点时间 O(1)
4. 操作流程
(1) 访问元素(get)
- 如果元素存在:
- 从链表中移除该节点
- 将该节点移动到链表头部(表示最近访问)
- 如果不存在:
- 返回
null或-1
- 返回
(2) 插入元素(put)
- 如果元素已存在:
- 更新值
- 移动到链表头部
- 如果元素不存在:
- 创建新节点,插入到链表头部
- 更新哈希表映射
- 如果缓存已满:
- 删除链表尾部节点
- 从哈希表中移除对应键
5. Java 实现示例
import java.util.*;
class LRUCache {
private class Node {
int key, value;
Node prev, next;
Node(int k, int v) { key = k; value = v; }
}
private final int capacity;
private Map<Integer, Node> map;
private Node head, tail;
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>();
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
}
public int get(int key) {
if (!map.containsKey(key)) return -1;
Node node = map.get(key);
remove(node);
insertToHead(node);
return node.value;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.value = value;
remove(node);
insertToHead(node);
} else {
if (map.size() == capacity) {
Node lru = tail.prev;
remove(lru);
map.remove(lru.key);
}
Node newNode = new Node(key, value);
map.put(key, newNode);
insertToHead(newNode);
}
}
private void remove(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void insertToHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
}
6. 时间复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| get | O(1) | 哈希表查找 + 链表移动 |
| put | O(1) | 哈希表更新 + 链表插入/删除 |
7. 总结
- LRU 缓存 结合了 哈希表 和 双向链表,保证了查找、插入、删除都是 O(1)。
- 核心思想:哈希表负责快速定位,双向链表负责维护访问顺序。
✅ 一句话总结:
LRU 缓存通过哈希表和双向链表实现,在 O(1) 时间内完成查找、插入和淘汰最近最少使用的元素。
-
布隆过滤器(Bloom Filter)的原理与应用?
1. 什么是布隆过滤器
布隆过滤器 是一种 空间效率极高 的概率型数据结构,用于 判断一个元素是否在集合中。
它的特点是:
- 可能会误判存在(False Positive),但绝不会漏判不存在(False Negative)。
- 适合在 海量数据 场景下快速判断元素是否存在。
2. 核心原理
布隆过滤器由:
- 一个固定长度的位数组(Bit Array)
- 初始时所有位都为
0
- 初始时所有位都为
- 多个不同的哈希函数(Hash Functions)
- 每个哈希函数将元素映射到位数组的某个位置
(1) 插入元素
- 对元素使用多个哈希函数,得到多个索引位置
- 将这些位置的位设为
1
(2) 查询元素
- 对元素使用相同的多个哈希函数,得到多个索引位置
- 如果这些位置的位都为
1→ 可能存在 - 如果有任何一个位置为
0→ 一定不存在
3. 为什么会有误判
- 不同元素可能通过哈希函数映射到相同的位置
- 位数组的某些位置可能被多个元素设置为
1 - 查询时,如果这些位置恰好都是
1,就会误判为存在
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 空间占用极小 | 有一定误判率 |
| 查询速度快(O(k),k为哈希函数个数) | 不支持删除(标准布隆过滤器) |
| 适合海量数据场景 | 需要合理选择哈希函数和位数组大小 |
5. 应用场景
- 网页爬虫去重
- 判断 URL 是否已经爬取过
- 数据库缓存预查询
- 判断数据是否可能存在于数据库中,减少不必要的查询
- 垃圾邮件过滤
- 判断邮件地址是否在黑名单中
- 区块链与分布式系统
- 节点快速判断交易或数据是否存在
6. Java 简单实现示例
import java.util.BitSet;
import java.util.List;
public class BloomFilter {
private BitSet bitSet;
private int size;
private List<HashFunction> hashFunctions;
public BloomFilter(int size, List<HashFunction> hashFunctions) {
this.size = size;
this.bitSet = new BitSet(size);
this.hashFunctions = hashFunctions;
}
public void add(String value) {
for (HashFunction f : hashFunctions) {
int index = f.hash(value) % size;
bitSet.set(index, true);
}
}
public boolean mightContain(String value) {
for (HashFunction f : hashFunctions) {
int index = f.hash(value) % size;
if (!bitSet.get(index)) {
return false;
}
}
return true;
}
public interface HashFunction {
int hash(String value);
}
}
7. 误判率公式
假设:
- 位数组长度为 m
- 插入元素个数为 n
- 哈希函数个数为 k
误判率 p 近似为:
p≈(1−e−mkn)k
通过调整 m 和 k,可以控制误判率。
✅ 一句话总结:
布隆过滤器是一种用位数组和多个哈希函数实现的高效集合判断结构,能在极小空间内快速判断元素是否存在,但可能会有误判。
-
哈希表与数组、链表的区别?
1. 数据结构简介
- 数组:连续内存存储,支持通过索引快速访问元素
- 链表:节点分散存储,通过指针连接,插入/删除灵活
- 哈希表:通过哈希函数将键映射到索引位置,结合数组和冲突处理结构实现快速查找
2. 核心区别
| 特性 | 数组 | 链表 | 哈希表 |
|---|---|---|---|
| 存储方式 | 连续内存 | 分散节点,指针连接 | 数组 + 哈希函数 + 冲突处理结构 |
| 访问速度 | O(1)(按索引) | O(n)(需遍历) | O(1)(平均情况,按键) |
| 插入速度 | O(n)(需移动元素) | O(1)(已知位置) | O(1)(平均情况) |
| 删除速度 | O(n)(需移动元素) | O(1)(已知位置) | O(1)(平均情况) |
| 空间利用 | 高效 | 额外指针开销 | 需要额外桶空间 |
| 是否有序 | 有序(按索引) | 有序(按链表顺序) | 无序(按哈希分布) |
| 查找方式 | 按索引或遍历 | 遍历 | 按键哈希定位 |
| 适用场景 | 索引访问频繁 | 插入/删除频繁 | 快速查找、键值映射 |
3. 详细分析
(1) 数组
- 优点:按索引访问速度快(O(1)),内存连续,缓存友好
- 缺点:插入/删除需要移动大量元素,扩容成本高
- 适用场景:元素数量固定、索引访问频繁的场景
(2) 链表
- 优点:插入/删除速度快(O(1),已知位置),不需要连续内存
- 缺点:查找速度慢(O(n)),额外指针占用空间
- 适用场景:频繁插入/删除,且不需要快速查找的场景
(3) 哈希表
- 优点:查找、插入、删除平均 O(1),适合键值映射
- 缺点:需要设计哈希函数,可能有冲突,最坏情况退化到 O(n)
- 适用场景:快速查找、键值映射、大量数据存储
4. 总结
- 数组:适合索引访问频繁的场景
- 链表:适合插入/删除频繁的场景
- 哈希表:适合快速查找和键值映射的场景
✅ 一句话总结:
数组快在索引访问,链表快在插入删除,哈希表快在键值查找。
五、树(Tree)
基础
-
树的基本概念(高度、深度、度)?
1. 树的定义
树 是一种 非线性数据结构,由 节点(Node) 和 边(Edge) 组成,具有层次关系。
- 根节点(Root):树的最顶层节点
- 子节点(Child):某节点直接连接的下层节点
- 父节点(Parent):某节点直接连接的上层节点
- 叶子节点(Leaf):没有子节点的节点
2. 基本概念
(1) 节点的度(Degree)
- 定义:一个节点拥有的子节点个数
- 树的度:树中所有节点的度的最大值
- 例子:如果某节点有 3 个子节点,则该节点的度为 3
(2) 节点的深度(Depth)
- 定义:从根节点到该节点所经过的边的数量
- 根节点的深度为 0
- 例子:
根节点(深度0) ├─ 子节点A(深度1) │ └─ 子节点B(深度2)
(3) 节点的高度(Height)
- 定义:从该节点到叶子节点的最长路径上的边的数量
- 叶子节点的高度为 0
- 树的高度:根节点的高度
- 例子:
根节点(高度2) ├─ 子节点A(高度1) │ └─ 子节点B(高度0)
3. 高度与深度的区别
- 深度:从根往下数(根节点深度为 0)
- 高度:从叶子往上数(叶子节点高度为 0)
4. 直观示例
假设有一棵树:
A
/ \
B C
/ \
D E
- 节点度:
- A 的度 = 2
- B 的度 = 2
- C 的度 = 0
- D 的度 = 0
- E 的度 = 0
- 树的度 = 2
- 节点深度:
- A 深度 = 0
- B 深度 = 1
- C 深度 = 1
- D 深度 = 2
- E 深度 = 2
- 节点高度:
- D 高度 = 0
- E 高度 = 0
- B 高度 = 1
- C 高度 = 0
- A 高度 = 2
✅ 一句话总结:
度是节点的子节点数,深度是从根到节点的距离,高度是从节点到叶子的距离。
-
二叉树的遍历方式有哪些?
1. 二叉树遍历的分类
二叉树遍历分为两大类:
- 深度优先遍历(DFS)
- 前序遍历(Preorder)
- 中序遍历(Inorder)
- 后序遍历(Postorder)
- 广度优先遍历(BFS)
- 层序遍历(Level Order)
2. 深度优先遍历(DFS)
(1) 前序遍历(Preorder)
- 访问顺序:根 → 左子树 → 右子树
- 特点:先处理根节点,再处理子树
- 应用:复制二叉树、表达式树的前缀表达式
(2) 中序遍历(Inorder)
- 访问顺序:左子树 → 根 → 右子树
- 特点:在二叉搜索树(BST)中,中序遍历结果是有序序列
- 应用:获取 BST 的有序数据
(3) 后序遍历(Postorder)
- 访问顺序:左子树 → 右子树 → 根
- 特点:先处理子树,再处理根节点
- 应用:删除二叉树、表达式树的后缀表达式
3. 广度优先遍历(BFS)
层序遍历(Level Order)
- 访问顺序:按层从上到下、从左到右依次访问
- 实现方式:通常用队列(Queue)实现
- 应用:按层输出树结构、计算最短路径
4. 示例
假设二叉树如下:
A / \ B C / \ D E
- 前序遍历:A → B → D → E → C
- 中序遍历:D → B → E → A → C
- 后序遍历:D → E → B → C → A
- 层序遍历:A → B → C → D → E
5. 对比表
| 遍历方式 | 顺序 | 特点 | 常用场景 |
|---|---|---|---|
| 前序遍历 | 根 → 左 → 右 | 根节点优先 | 复制树、前缀表达式 |
| 中序遍历 | 左 → 根 → 右 | BST 有序输出 | 获取有序数据 |
| 后序遍历 | 左 → 右 → 根 | 子树优先 | 删除树、后缀表达式 |
| 层序遍历 | 按层访问 | 广度优先 | 层次输出、最短路径 |
✅ 一句话总结:
DFS 有前序、中序、后序三种方式,BFS 是层序遍历;选择哪种遍历取决于你的应用场景。
-
如何实现前序、中序、后序、层序遍历?
1. 前序遍历(Preorder Traversal)
访问顺序:根 → 左 → 右
递归实现
void preorder(TreeNode root) {
if (root == null) return;
System.out.print(root.val + " ");
preorder(root.left);
preorder(root.right);
}
迭代实现(用栈)
void preorderIterative(TreeNode root) {
if (root == null) return;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
System.out.print(node.val + " ");
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
}
2. 中序遍历(Inorder Traversal)
访问顺序:左 → 根 → 右
递归实现
void inorder(TreeNode root) {
if (root == null) return;
inorder(root.left);
System.out.print(root.val + " ");
inorder(root.right);
}
迭代实现(用栈)
void inorderIterative(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
System.out.print(curr.val + " ");
curr = curr.right;
}
}
3. 后序遍历(Postorder Traversal)
访问顺序:左 → 右 → 根
递归实现
void postorder(TreeNode root) {
if (root == null) return;
postorder(root.left);
postorder(root.right);
System.out.print(root.val + " ");
}
迭代实现(用两个栈)
void postorderIterative(TreeNode root) {
if (root == null) return;
Stack<TreeNode> stack1 = new Stack<>();
Stack<TreeNode> stack2 = new Stack<>();
stack1.push(root);
while (!stack1.isEmpty()) {
TreeNode node = stack1.pop();
stack2.push(node);
if (node.left != null) stack1.push(node.left);
if (node.right != null) stack1.push(node.right);
}
while (!stack2.isEmpty()) {
System.out.print(stack2.pop().val + " ");
}
}
4. 层序遍历(Level Order Traversal)
访问顺序:按层从上到下、从左到右
实现(用队列)
void levelOrder(TreeNode root) {
if (root == null) return;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
System.out.print(node.val + " ");
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
}
5. 对比表
| 遍历方式 | 顺序 | 常用数据结构 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 前序遍历 | 根 → 左 → 右 | 栈(迭代) | O(n) | O(h)(递归) |
| 中序遍历 | 左 → 根 → 右 | 栈(迭代) | O(n) | O(h) |
| 后序遍历 | 左 → 右 → 根 | 栈(迭代) | O(n) | O(h) |
| 层序遍历 | 按层访问 | 队列 | O(n) | O(w)(最大层宽) |
✅ 一句话总结:
前序、中序、后序遍历可以用递归或栈实现,层序遍历用队列实现,时间复杂度都是 O(n)。
-
满二叉树、完全二叉树的区别?
1. 满二叉树(Full Binary Tree)
定义:
- 除了叶子节点外,每个节点都有两个子节点
- 所有叶子节点都在同一层
- 形状非常规整
特点:
- 节点数公式:如果高度为 ℎh(根节点高度为 0),节点总数为
n=2^(h+1)−1
- 每一层的节点数都是满的
示例:
A / \ B C / \ / \ D E F G
- 高度 ℎ=2h=2
- 节点数 n=22+1−1=7
2. 完全二叉树(Complete Binary Tree)
定义:
- 除了最后一层外,每一层都是满的
- 最后一层的节点从左到右连续排列,不能有空缺
特点:
- 不要求所有叶子节点在同一层
- 最后一层可以不满,但必须左对齐
示例:
A / \ B C / \ / D E F
- 最后一层节点 D、E、F 从左到右连续排列,没有空位
3. 区别对比
| 特性 | 满二叉树 | 完全二叉树 |
|---|---|---|
| 节点分布 | 所有非叶子节点都有两个子节点,叶子节点在同一层 | 除最后一层外都满,最后一层左对齐 |
| 形状 | 非常规整 | 较规整,但最后一层可能不满 |
| 节点数公式 | n=2h+1−1 | 无固定公式 |
| 叶子节点位置 | 全在同一层 | 最后一层左对齐 |
| 例子 | 完全对称的二叉树 | 堆结构常用的树 |
4. 关系
- 满二叉树一定是完全二叉树
- 完全二叉树不一定是满二叉树
✅ 一句话总结:
满二叉树是所有层都满且叶子在同一层,完全二叉树是除了最后一层外都满,最后一层左对齐。
二叉搜索树(BST)
-
BST 的特点是什么?
-
BST 的查找、插入、删除的时间复杂度?
-
如何判断一棵树是否是 BST?
-
如何找到 BST 的第 K 小元素?
-
BST 的平衡性问题?
平衡树
-
AVL 树的原理与特点?
1. AVL 树的定义
AVL 树 是一种 自平衡二叉搜索树(Self-Balancing BST),由 G.M. Adelson-Velsky 和 E.M. Landis 在 1962 年提出。
它的核心思想是:在插入或删除节点后,通过旋转保持树的平衡。
2. 平衡条件
- 对于树中的任意节点,左子树高度与右子树高度的差(平衡因子)的绝对值 ≤ 1
- 平衡因子(Balance Factor):
BF=左子树高度−右子树高度
- 平衡因子可能的取值:-1、0、1
3. 失衡与旋转
当插入或删除节点导致某个节点的平衡因子不在 [-1, 1] 范围内时,需要进行**旋转(Rotation)**来恢复平衡。
四种旋转方式
- LL型(右旋):插入在失衡节点的左子树的左子树
- RR型(左旋):插入在失衡节点的右子树的右子树
- LR型(先左旋再右旋):插入在失衡节点的左子树的右子树
- RL型(先右旋再左旋):插入在失衡节点的右子树的左子树
4. AVL 树的特点
| 特性 | 说明 |
|---|---|
| 平衡性强 | 高度差限制在 1,查找效率稳定 |
| 查找效率高 | 时间复杂度 O(logn) |
| 插入/删除需要旋转 | 可能需要一次或两次旋转来保持平衡 |
| 空间开销 | 需要存储每个节点的高度信息 |
| 适用场景 | 查找频繁且插入/删除相对较少的场景 |
5. 优缺点
- 优点:
- 查找效率稳定在 O(logn)
- 适合查找密集型任务
- 缺点:
- 插入、删除操作复杂,需要维护平衡
- 旋转操作增加了时间开销
6. 应用场景
- 数据库索引(部分场景)
- 内存中需要高效查找的结构
- 需要保证查找性能稳定的系统
✅ 一句话总结:
AVL 树通过限制高度差在 1 来保持平衡,查找效率稳定,但插入和删除需要旋转维护结构。
-
红黑树的原理与特点?
1. 红黑树的定义
红黑树是一种二叉搜索树(BST),但它在每个节点上增加了一个颜色属性(红或黑),并通过一系列规则来保持树的近似平衡,从而保证查找、插入、删除的时间复杂度为 O(logn)。
2. 红黑树的性质
红黑树必须满足以下 5 条性质:
- 节点是红色或黑色
- 根节点是黑色
- 所有叶子节点(NIL节点)是黑色
- 红色节点的子节点必须是黑色(即不能有两个连续的红色节点)
- 从任一节点到其所有叶子节点的路径上,黑色节点数量相同(黑高一致)
3. 平衡原理
红黑树通过颜色标记和旋转来保持平衡:
- 当插入或删除节点破坏了红黑树的性质时,通过颜色变换和**旋转(左旋、右旋)**来恢复平衡
- 相比 AVL 树,红黑树的平衡条件更宽松,因此旋转次数更少
4. 旋转操作
红黑树的旋转与 AVL 树类似:
- 左旋(Left Rotation):将右子节点提升为父节点
- 右旋(Right Rotation):将左子节点提升为父节点
- 插入和删除时可能需要颜色调整 + 旋转组合
5. 红黑树的特点
| 特性 | 说明 |
|---|---|
| 近似平衡 | 高度最多是 2log(n+1) |
| 查找效率高 | 时间复杂度 O(logn) |
| 插入/删除效率高 | 平衡调整次数少于 AVL 树 |
| 颜色属性 | 通过红黑规则维持平衡 |
| 适用场景 | 插入、删除频繁的场景(如集合、映射结构) |
6. 优缺点
- 优点:
- 插入、删除效率高,旋转次数少
- 保证查找性能稳定
- 缺点:
- 查找性能略逊于 AVL 树(因为平衡性稍弱)
- 实现复杂度高
7. 应用场景
- Java 的 TreeMap、TreeSet
- C++ STL 的 map、set
- Linux 内核调度器
- 数据库索引结构(部分场景)
✅ 一句话总结:
红黑树是一种通过颜色规则和旋转保持近似平衡的二叉搜索树,插入和删除效率高,适合频繁更新的场景。
-
红黑树的旋转操作?
1. 为什么需要旋转?
红黑树在插入或删除节点时,可能会破坏它的 5 条性质(尤其是不能有两个连续的红色节点、黑高一致)。
为了恢复平衡,需要通过 旋转(Rotation) 改变节点的结构,同时配合 颜色调整。
2. 旋转的类型
红黑树的旋转分为两种基本操作:
- 左旋(Left Rotation)
- 右旋(Right Rotation)
3. 左旋(Left Rotation)
目的:将某个节点的右子节点提升为父节点,原父节点变为其左子节点。
步骤:
- 设当前节点为
x,它的右子节点为y - 将
y的左子树变为x的右子树 - 将
y提升为x的父节点 - 将
x变为y的左子节点
示意图:
x y / \ / \ a y → x c / \ / \ b c a b
4. 右旋(Right Rotation)
目的:将某个节点的左子节点提升为父节点,原父节点变为其右子节点。
步骤:
- 设当前节点为
y,它的左子节点为x - 将
x的右子树变为y的左子树 - 将
x提升为y的父节点 - 将
y变为x的右子节点
示意图:
y x / \ / \ x c → a y / \ / \ a b b
5. 插入与删除中的旋转
- 插入修复:
- 可能需要 一次旋转(LL 或 RR)
- 或 两次旋转(LR 或 RL)
- 删除修复:
- 可能需要多次旋转和颜色调整,直到恢复平衡
6. 对比表
| 操作类型 | 触发条件 | 作用 | 常见场景 |
|---|---|---|---|
| 左旋 | 右子树过高 | 将右子节点提升为父节点 | 插入右侧失衡 |
| 右旋 | 左子树过高 | 将左子节点提升为父节点 | 插入左侧失衡 |
✅ 一句话总结:
红黑树的旋转是通过调整父子关系来改变树的结构,从而恢复平衡,通常配合颜色调整一起使用。
-
B 树与 B+ 树的区别?
1. B 树(B-Tree)
定义:
B 树是一种多路平衡查找树,常用于数据库和文件系统的索引结构。
它的特点是:
- 每个节点可以有多个**关键字(keys)**和多个子节点
- 所有关键字分布在所有节点(包括内部节点和叶子节点)
- 叶子节点高度相同(平衡)
- 节点内的关键字按升序排列,子树的关键字范围受父节点关键字限制
查找过程:
- 从根节点开始,逐层向下查找,可能在内部节点就找到目标关键字
2. B+ 树(B+ Tree)
定义:
B+ 树是 B 树的变种,优化了范围查询和磁盘读写效率。
它的特点是:
- 所有关键字都存储在叶子节点,内部节点只存储索引(不存储实际数据)
- 叶子节点之间通过链表连接,方便范围查询
- 叶子节点高度相同(平衡)
- 内部节点的关键字仅用于导航,不直接存储数据
查找过程:
- 必须到叶子节点才能找到目标关键字
3. 区别对比
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 数据分布在所有节点(内部节点和叶子节点) | 数据全部存储在叶子节点 |
| 内部节点作用 | 既存储索引又存储数据 | 只存储索引 |
| 范围查询效率 | 需要中序遍历整棵树 | 叶子节点链表可直接顺序访问,效率高 |
| 磁盘读写 | 可能访问多个节点 | 叶子节点连续存储,磁盘访问更友好 |
| 查找路径 | 可能在内部节点结束 | 必须到叶子节点结束 |
| 空间利用率 | 较高 | 较低(因为内部节点不存数据) |
| 应用场景 | 数据库索引、文件系统 | 数据库索引(尤其是范围查询多的场景) |
4. 关系
- B+ 树是 B 树的改进版
- 在数据库索引中,B+ 树更常用,因为它对范围查询和磁盘访问更友好
✅ 一句话总结:
B 树数据分布在所有节点,B+ 树数据全部在叶子节点且叶子节点有链表连接,范围查询效率更高。
-
B+ 树在数据库索引中的应用?
1. 为什么数据库索引常用 B+ 树?
B+ 树相比 B 树在数据库场景中有几个关键优势:
- 范围查询效率高:叶子节点通过链表连接,可以顺序遍历
- 磁盘访问友好:叶子节点连续存储,减少磁盘随机读
- 稳定的查找路径:所有数据都在叶子节点,查找路径长度一致
- 分支因子大:一个节点可存储大量索引值,树的高度低,减少磁盘 I/O 次数
2. 在数据库中的应用场景
(1) 主键索引(聚簇索引)
- 在 MySQL InnoDB 中,主键索引就是一个 B+ 树
- 叶子节点存储整行数据
- 内部节点存储主键值作为索引
特点:
- 按主键查找效率高
- 范围查询(
BETWEEN、>、<)非常快
(2) 二级索引(非聚簇索引)
- 叶子节点存储主键值而不是整行数据
- 查询时需要回表(通过主键再去主键索引查找整行数据)
特点:
- 节省空间
- 适合非主键字段的查询
(3) 范围查询
- 由于叶子节点有链表连接,范围查询只需找到起始位置,然后顺序扫描叶子节点即可
- 比 B 树中序遍历效率高很多
(4) 排序查询
- B+ 树的叶子节点天然有序,支持
ORDER BY优化 - 可以直接按索引顺序返回结果,无需额外排序
3. 优势总结
| 优势 | 说明 |
|---|---|
| 低树高 | 分支因子大,减少磁盘 I/O |
| 范围查询快 | 叶子节点链表顺序访问 |
| 查找路径一致 | 所有数据在叶子节点,查找步骤固定 |
| 磁盘友好 | 节点连续存储,减少随机读 |
| 支持排序 | 叶子节点天然有序 |
4. 应用举例
- MySQL InnoDB:主键索引和二级索引均使用 B+ 树
- PostgreSQL:默认索引类型是 B+ 树
- Oracle:B+ 树索引是最常用的索引结构
✅ 一句话总结:
B+ 树在数据库索引中通过叶子节点链表和低树高结构,实现了高效的查找、范围查询和排序,是关系型数据库的核心索引结构。
六、图(Graph)
-
图的存储方式(邻接矩阵、邻接表)?
-
有向图与无向图的区别?
-
带权图与无权图的区别?
-
深度优先搜索(DFS)的原理与实现?
-
广度优先搜索(BFS)的原理与实现?
-
拓扑排序的原理与实现?
-
最短路径算法(Dijkstra、Bellman-Ford、Floyd-Warshall)?
-
最小生成树算法(Prim、Kruskal)?
-
图的连通性判断?
-
图的环检测方法?
七、堆(Heap)
-
堆的特点是什么?
1. 堆的定义
堆是一种完全二叉树(Complete Binary Tree),并且满足堆性质(Heap Property):
- 大顶堆(Max Heap):任意节点的值 ≥ 其子节点的值
- 小顶堆(Min Heap):任意节点的值 ≤ 其子节点的值
2. 堆的特点
| 特性 | 说明 |
|---|---|
| 结构性 | 堆是完全二叉树,节点从上到下、从左到右依次填充 |
| 堆性质 | 大顶堆:父节点值 ≥ 子节点值;小顶堆:父节点值 ≤ 子节点值 |
| 存储方式 | 常用数组存储,父子节点位置可通过索引计算 |
| 插入效率 | 插入新元素后,通过**上浮(Heapify Up)**调整,时间复杂度 O(logn) |
| 删除效率 | 删除堆顶元素后,通过**下沉(Heapify Down)**调整,时间复杂度 O(logn) |
| 查找效率 | 堆顶元素查找为 O(1),其他元素查找为 O(n) |
| 排序应用 | 可用于堆排序,时间复杂度 O(nlogn) |
| 优先队列 | 堆是实现优先队列的常用结构 |
3. 堆的常见类型
- 二叉堆(Binary Heap):最常见,基于完全二叉树
- 斐波那契堆(Fibonacci Heap):适合频繁合并堆的场景
- 左偏堆(Leftist Heap):适合合并操作
- 索引堆(Indexed Heap):支持快速更新元素位置
4. 应用场景
- 优先队列(任务调度、事件驱动系统)
- 堆排序
- 图算法(Dijkstra 最短路径、Prim 最小生成树)
- 实时数据流(求 Top-K 元素)
✅ 一句话总结:
堆是一种满足堆性质的完全二叉树,能在 O(1) 时间获取堆顶元素,并在 O(logn) 时间完成插入和删除,常用于优先队列和排序。
-
最大堆与最小堆的区别?
1. 定义
- 最大堆:任意节点的值 ≥ 其子节点的值,堆顶是最大值
- 最小堆:任意节点的值 ≤ 其子节点的值,堆顶是最小值
2. 区别对比
| 对比项 | 最大堆(Max Heap) | 最小堆(Min Heap) |
|---|---|---|
| 堆顶元素 | 最大值 | 最小值 |
| 堆性质 | 父节点值 ≥ 子节点值 | 父节点值 ≤ 子节点值 |
| 用途 | 适合取最大值的场景,如求 Top-K 最大元素 | 适合取最小值的场景,如求 Top-K 最小元素 |
| 插入调整 | 新元素上浮时,与父节点比较,若大于父节点则交换 | 新元素上浮时,与父节点比较,若小于父节点则交换 |
| 删除调整 | 删除堆顶后,将最后一个元素放到堆顶并下沉,保持最大堆性质 | 删除堆顶后,将最后一个元素放到堆顶并下沉,保持最小堆性质 |
| 排序方向 | 用于堆排序时,得到的是升序结果 | 用于堆排序时,得到的是降序结果 |
3. 应用场景
- 最大堆:
- 实时获取最大值(如优先级最高的任务)
- Top-K 最大值问题
- 堆排序(升序)
- 最小堆:
- 实时获取最小值(如最短任务优先)
- Top-K 最小值问题
- 堆排序(降序)
✅ 一句话总结:
最大堆堆顶是最大值,最小堆堆顶是最小值,二者的主要区别在于堆性质和适用场景。
-
堆的插入与删除操作?
1. 堆的插入操作(Insert)
目标:在堆中加入一个新元素,并保持堆性质(最大堆或最小堆)。
步骤:
- 将新元素放到堆的末尾(数组最后一个位置)
- 上浮(Heapify Up / Sift Up):
- 与父节点比较:
- 最大堆:如果新元素 > 父节点,交换
- 最小堆:如果新元素 < 父节点,交换
- 重复直到满足堆性质或到达根节点
- 与父节点比较:
时间复杂度:
- 最坏情况需要上浮到根节点,复杂度 O(logn)
- 平均复杂度也是 O(logn)
2. 堆的删除操作(Delete)
通常删除的是堆顶元素(最大堆的最大值或最小堆的最小值)。
步骤:
- 取出堆顶元素(返回给调用方)
- 将堆的最后一个元素放到堆顶
- 下沉(Heapify Down / Sift Down):
- 与左右子节点比较:
- 最大堆:如果当前节点 < 最大的子节点,交换
- 最小堆:如果当前节点 > 最小的子节点,交换
- 重复直到满足堆性质或到达叶子节点
- 与左右子节点比较:
时间复杂度:
- 最坏情况需要下沉到叶子节点,复杂度 O(logn)
- 平均复杂度也是 O(logn)
3. 对比表
| 操作 | 步骤核心 | 时间复杂度 | 常用场景 |
|---|---|---|---|
| 插入 | 末尾插入 + 上浮 | O(logn) | 新增任务、数据流实时更新 |
| 删除 | 堆顶删除 + 下沉 | O(logn) | 取最大值/最小值、任务调度 |
4. 应用场景
- 优先队列:插入新任务、删除最高优先级任务
- 实时数据流:维护 Top-K 元素
- 排序:堆排序依赖插入和删除操作
✅ 一句话总结:
堆的插入通过“末尾插入+上浮”保持堆性质,删除通过“堆顶替换+下沉”保持堆性质,二者时间复杂度均为 O(logn)。
-
堆排序的原理与实现?
1. 堆排序的原理
堆排序是一种基于堆(Heap)数据结构的选择排序,利用堆的性质快速找到最大值或最小值。
- 升序排序:使用最大堆(Max Heap)
- 降序排序:使用最小堆(Min Heap)
核心思想:
- 建堆:将无序数组构造成一个堆(最大堆或最小堆)
- 交换堆顶与末尾元素:堆顶是当前最大(或最小)值
- 缩小堆的范围:将末尾元素固定,剩余部分重新调整为堆
- 重复步骤 2 和 3,直到排序完成
2. 实现步骤(以升序为例,使用最大堆)
步骤 1:建最大堆
- 从最后一个非叶子节点开始,依次向上进行**下沉(Heapify Down)**操作
- 时间复杂度:O(n)(建堆是线性时间)
步骤 2:排序过程
- 将堆顶(最大值)与末尾元素交换
- 缩小堆的有效范围(末尾元素已排好序)
- 对新的堆顶进行下沉操作,恢复最大堆性质
- 重复直到堆的大小为 1
3. 时间复杂度分析
| 阶段 | 操作 | 时间复杂度 |
|---|---|---|
| 建堆 | 从底向上调整 | O(n) |
| 排序 | 每次删除堆顶并调整 | O(logn),共 n−1 次 |
| 总复杂度 | O(nlogn) |
空间复杂度:O(1)(原地排序)
稳定性:堆排序是不稳定排序(相同元素可能交换顺序)
4. 伪代码(升序)
heapSort(arr):
buildMaxHeap(arr)
for i = len(arr)-1 down to 1:
swap(arr[0], arr[i])
heapify(arr, 0, i) // 调整堆,范围是 0 到 i-1
buildMaxHeap(arr):
for i = floor(len(arr)/2)-1 down to 0:
heapify(arr, i, len(arr))
heapify(arr, i, heapSize):
left = 2*i + 1
right = 2*i + 2
largest = i
if left < heapSize and arr[left] > arr[largest]:
largest = left
if right < heapSize and arr[right] > arr[largest]:
largest = right
if largest != i:
swap(arr[i], arr[largest])
heapify(arr, largest, heapSize)
5. 特点总结
- 优点:
- 时间复杂度稳定在 O(nlogn)
- 原地排序,空间复杂度 O(1)
- 缺点:
- 不稳定排序
- 对缓存不友好(访问模式跳跃)
✅ 一句话总结:
堆排序通过“建堆 + 交换堆顶与末尾 + 调整堆”实现排序,时间复杂度 O(nlogn),空间复杂度 O(1),但不稳定。
-
如何用堆实现 Top K 问题?
1. Top K 问题定义
- Top K 最大值:从 n 个元素中找出最大的 K 个
- Top K 最小值:从 n 个元素中找出最小的 K 个
2. 用堆解决的核心思路
- Top K 最大值 → 用 最小堆(Min Heap)
- Top K 最小值 → 用 最大堆(Max Heap)
原因:
- 维护一个大小为 K 的堆
- 堆顶是当前集合中最小(或最大)的元素
- 当新元素比堆顶更符合条件时,替换堆顶并调整堆
3. Top K 最大值的实现步骤(用最小堆)
- 初始化最小堆,将前 K 个元素放入堆中
- 从第 K+1 个元素开始遍历:
- 如果当前元素 > 堆顶(最小值),则替换堆顶并调整堆
- 否则跳过
- 遍历结束后,堆中就是最大的 K 个元素
时间复杂度:
- 建堆:O(K)
- 遍历剩余n−K 个元素,每次调整堆:O(logK)
- 总复杂度:O(nlogK)(适合 K≪n 的情况)
4. Top K 最小值的实现步骤(用最大堆)
- 思路与上面相同,只是堆类型换成最大堆,堆顶是当前集合中最大值
- 当新元素 < 堆顶 时,替换堆顶并调整
5. 对比表
| 需求 | 堆类型 | 堆顶含义 | 替换条件 |
|---|---|---|---|
| Top K 最大值 | 最小堆 | 当前 K 个数中最小的 | 新元素 > 堆顶 |
| Top K 最小值 | 最大堆 | 当前 K 个数中最大的 | 新元素 < 堆顶 |
6. 伪代码(Top K 最大值)
function topKMax(arr, K):
heap = 最小堆()
for i in range(0, K):
heap.push(arr[i])
for i in range(K, len(arr)):
if arr[i] > heap.top():
heap.pop()
heap.push(arr[i])
return heap
7. 应用场景
- 实时数据流中获取前 K 大/小值
- 搜索引擎返回相关性最高的 K 条结果
- 大数据分析中的排名问题
✅ 一句话总结:
用堆解决 Top K 问题的关键是维护一个大小为 K 的堆,Top K 最大值用最小堆,Top K 最小值用最大堆,时间复杂度 O(nlogK),适合 K 远小于 n 的场景。
-
如何用堆实现中位数查找?
1. 问题背景
- 中位数:将数据按大小排序后,处于中间位置的值
- 静态数据:直接排序后取中位数即可,时间复杂度 O(nlogn)
- 动态数据流:数据不断到来,需要快速更新中位数 → 用堆可以做到 O(logn) 插入 + O(1) 查询
2. 核心思路
使用 两个堆:
- 最大堆(Max Heap):存储较小的一半数据,堆顶是这部分的最大值
- 最小堆(Min Heap):存储较大的一半数据,堆顶是这部分的最小值
保持平衡:
- 两个堆的元素数量差不超过 1
- 最大堆的所有元素 ≤ 最小堆的所有元素
3. 插入新元素的步骤
- 如果最大堆为空或新元素 ≤ 最大堆堆顶 → 插入最大堆
否则 → 插入最小堆 - 调整平衡:
- 如果最大堆元素数 > 最小堆元素数 + 1 → 将最大堆堆顶移到最小堆
- 如果最小堆元素数 > 最大堆元素数 + 1 → 将最小堆堆顶移到最大堆
4. 获取中位数
- 如果两个堆大小相等 → 中位数 = (最大堆堆顶 + 最小堆堆顶) / 2
- 如果不相等 → 中位数 = 元素更多的那个堆的堆顶
5. 时间复杂度
- 插入:O(logn)(堆调整)
- 查询中位数:O(1)(直接取堆顶)
6. 伪代码
function addNumber(num):
if maxHeap.empty() or num <= maxHeap.top():
maxHeap.push(num)
else:
minHeap.push(num)
// 平衡两个堆
if maxHeap.size() > minHeap.size() + 1:
minHeap.push(maxHeap.pop())
elif minHeap.size() > maxHeap.size() + 1:
maxHeap.push(minHeap.pop())
function findMedian():
if maxHeap.size() == minHeap.size():
return (maxHeap.top() + minHeap.top()) / 2
elif maxHeap.size() > minHeap.size():
return maxHeap.top()
else:
return minHeap.top()
7. 应用场景
- 实时数据流分析(如股票价格、传感器数据)
- 在线算法(数据不断到来时实时计算中位数)
- 大数据处理(无需全量排序即可获取中位数)
✅ 一句话总结:
用堆实现中位数查找的关键是用最大堆存较小的一半数据、最小堆存较大的一半数据,并保持两个堆平衡,这样插入是 O(logn),查询是 O(1)。
八、跳表(Skip List)
-
跳表的原理是什么?
-
跳表的时间复杂度分析?
-
跳表的插入与删除操作?
-
跳表与平衡树的对比?
-
跳表在 Redis 中的应用?
✅ 总结
这份清单基本覆盖了 数据结构篇的所有常见面试题,从数组、链表、栈队列、哈希表到树、图、堆、跳表都有涉及。
建议你复习时:
-
先掌握数组、链表、栈队列、哈希表 → 高频且基础。
-
再学习树、图、堆 → 面试加分项。
-
最后补充跳表与高级数据结构 → 提升竞争力。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









