







 本文介绍使用sklearn中的CountVectorizer进行文本特征提取的方法。通过具体案例演示如何配置参数并应用到训练集与测试集,最后利用逻辑回归模型进行预测。
本文介绍使用sklearn中的CountVectorizer进行文本特征提取的方法。通过具体案例演示如何配置参数并应用到训练集与测试集,最后利用逻辑回归模型进行预测。
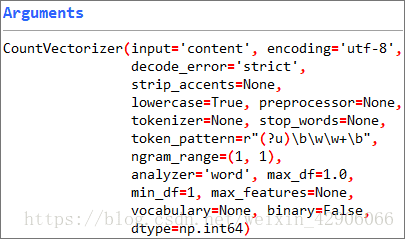
sklearn中一般使用CountVectorizer和TfidfVectorizer这两个类来提取文本特征
CountVectorizer() [词频统计把文本特征处理成数字向量]
vectorizer = CountVectorizer(ngram_range=(1,2), min_df=3, max_df=0.9, max_features=100000)
参数说明:
ngram_range=(1,2) :词组切分的长度范围
min_df=3 :表示词出现的次数,作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence小于max_df,这个词不会被当作关键词
max_df=0.9 :表示词出现的次数与语料库文档数的百分比,作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词
max_features=100000 :默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
(所有参数见:http://www.itkeyword.com/doc/4813494854317445586/TfidfVectorizer-sklearn-CountVectorizer)
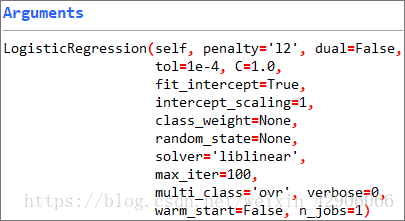
(参数说明见:https://blog.youkuaiyun.com/kingzone_2008/article/details/81067036
代码如下:
# 导入sklearn相关包
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer # 导入文本特征提取
print("start...........")
time_start = time.time()
# 数据预处理
df_train = pd.read_csv(r'D:\dataset\ml_data\v0.0\train_set.csv')
df_test = pd.read_csv(r'D:\dataset\ml_data\v0.0\test_set.csv')
df_train.drop(columns=['article','id'], inplace=True) # inplace=True,结果不显示,默认为False,axis=0默认纵轴
df_test.drop(columns=['article'], inplace=True)
# 特征工程
CountVectorizer()
vectorizer = CountVectorizer(ngram_range=(1,2), min_df=3, max_df=0.9, max_features=100000)
vectorizer.fit(df_train['word_seg'])
# 使用词频统计的方式训练集和测试集的文本转化为特征向量(数字向量)
x_train = vectorizer.transform(df_train['word_seg'])
x_test = vectorizer.transform(df_test['word_seg'])
y_train = df_train['class']-1 # 减一指类别从0开始,个人代码习惯
# 使用传统监督学习算法之线性逻辑回归模型对数据集进行训练和预测
lg = LogisticRegression(C=4, dual=True)
"""
C=4: 正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
dual=True:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False
"""
lg.fit(x_train, y_train)
y_test = lg.predict(x_test) # 对测试集进行预测,并将预测的结果保存在变量y_test
# 将预测集的预测结果保存在本地
df_test['class'] = y_test.tolist()
df_test['class'] = df_test['class'] + 1
df_result = df_test.loc[:,['id','class']]
df_result.to_csv(r'D:\dataset\ml_data\v0.0\lg_result.csv', index=False) # index=False不保存索引
time_end = time.time()
print(time_end - time_start)
print("end...........")

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









