







最近在读文献的时候发现了一个新的强化学习Benchmark:MARLlib。论文名称为:MARLlib: Extending RLlib for Multi-agent Reinforcement Learning。下来对论文和代码库做一个简要的介绍:
MARLlib论文
作者在论文当中主要针对提出的MARLlib进行了介绍,并和其他现有的Benchmark做了比较,文章值的学习的地方是对现有的算法进行了详细的分析和分类,针对每一类算法的特点,对强化学习算法的使用提供了明确的方向,对每一类任务模式都贴上了相应的标签,并且支持10多种环境、18种算法、支持异步采样。
Task mode
代码库提供了多种任务模式,包括cooperative、collaborative、competitive、mixed多种任务模式,能够方便广大研究者对确切的环境模式进行选择。
Algorithm
文章对现有的算法进行了明确的分类,将现有的算法大致分为 Independent Learning 、Centralized Critic 、Value Decomposition 三种。
框架
算法
值的一提的是文章在论文当中清晰的将Independent Learning 、Centralized Critic 、Value Decomposition这三种算法框架进行绘图,有利于学者清楚的了解不同算法框架的架构,从而进行改进和学习。
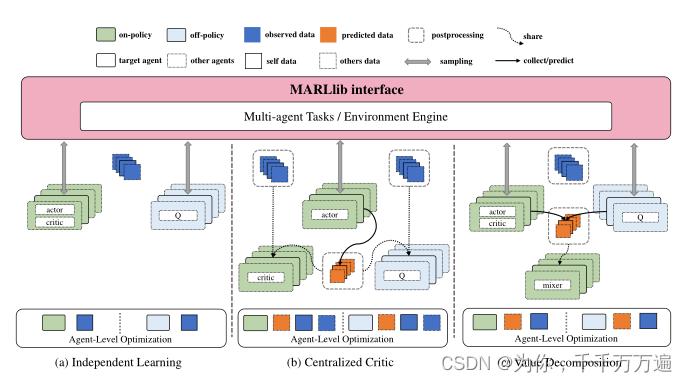
Benchmark比较
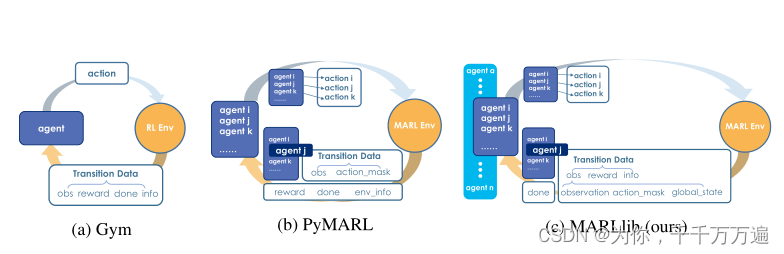
作者将Gym、pymarl、MARLlib的数据流模型进行了绘制,清楚的描述了不同的库和环境交互过程当中数据流的变化,具体如下所示:
代码框架
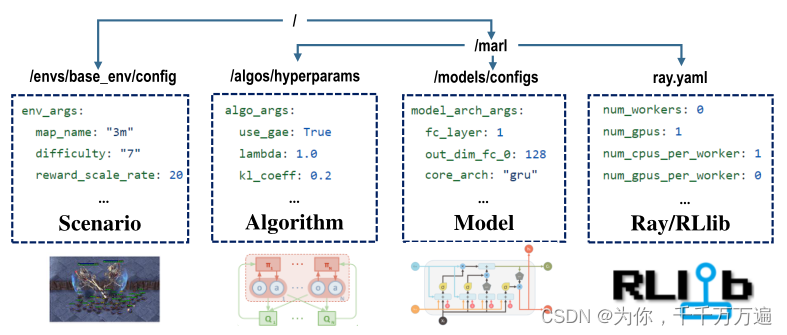
作者清晰的展示了自己代码的框架结构图,对于不同场景的切换、算法的调用、模型的更改以及GPU和CPU的调用进行了清晰的展示。
MARLlib代码及说明
MARLlib 的代码说明地址如下所示,https://marllib.readthedocs.io/en/latest/resources/awesome.html
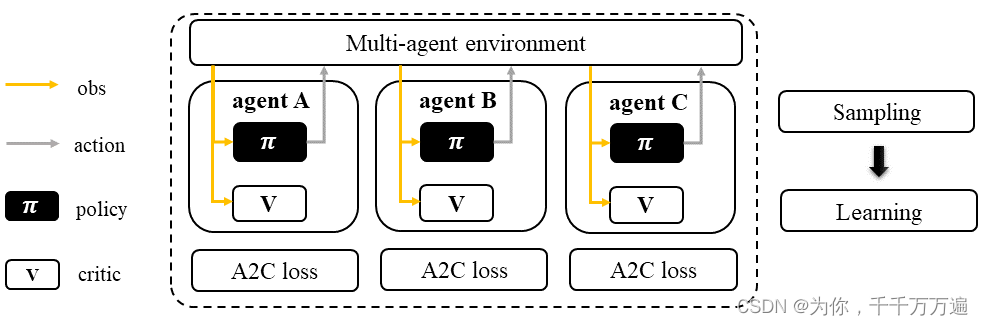
作者在该网站自己的讲述了各类环境的安装,算法的推导以及之间的关系,还有清晰的算法框架和分类,这些资源都有助于研究者进一步进行学习并开发。例如IA2C的算法。
对于MARLlib的介绍就到这里,希望呢能够帮到各位研究学者,如果有其他比较容易上手的Benchmark,欢迎大家在下方留言。

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









