







文章目录
分类思想
逻辑回归(Logistic Regression)虽然称为回归,但实际是一个常用的二分类算法,用来表示某件事发生的可能性。分类的思想:将每个样本进行“打分”,然后设置一个阈值(概率),大于该阈值为一个类别,反之另一类别。
逻辑回归模型公式
逻辑回归的z部分类似线性回归,z值是一个连续的值,取值范围为
z
∈
(
−
∞
,
+
∞
)
z\in(-\infin,+\infin)
z∈(−∞,+∞),将阈值设为0,当z≥0时,样本划为“正类”,当z<0时,样本划为“负类”,这种分类对整改是实数域敏感一致不便于分类。
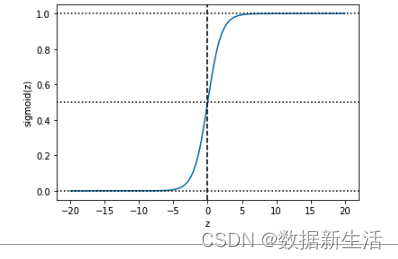
在z的基础上,套上sigmoid函数(引入非线性映射),将线性回归值域映射至(0,1),来表事件发生的概率。将预测值限制在(0,1),模型曲线在z=0时,十分敏感,在z>>>0 or z<<<0时都不敏感,有助于直观做出列别判断,>0为“正类”,反之为“负类”。
一
元
线
性
回
归
方
程
:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
.
多
元
线
性
回
归
方
程
:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
1
x
2
+
.
.
.
+
θ
n
x
n
=
∑
i
=
0
n
θ
i
x
i
=
θ
T
x
.
h
θ
′
(
x
)
=
s
i
g
m
o
i
d
(
z
)
=
1
1
+
e
−
θ
T
x
一元线性回归方程:h_\theta(x) = \theta_0+\theta_1x_1\\.\\ 多元线性回归方程:h_\theta(x) =\theta_0+ \theta_1x_1+\theta_1x_2+...+\theta_nx_n =\textstyle\sum_{i=0}^n\theta_ix_i=\theta^Tx \\. \\ h'_\theta(x)=sigmoid(z)=\frac{1}{1+e^{-\theta^Tx}}
一元线性回归方程:hθ(x)=θ0+θ1x1.多元线性回归方程:hθ(x)=θ0+θ1x1+θ1x2+...+θnxn=∑i=0nθixi=θTx.hθ′(x)=sigmoid(z)=1+e−θTx1
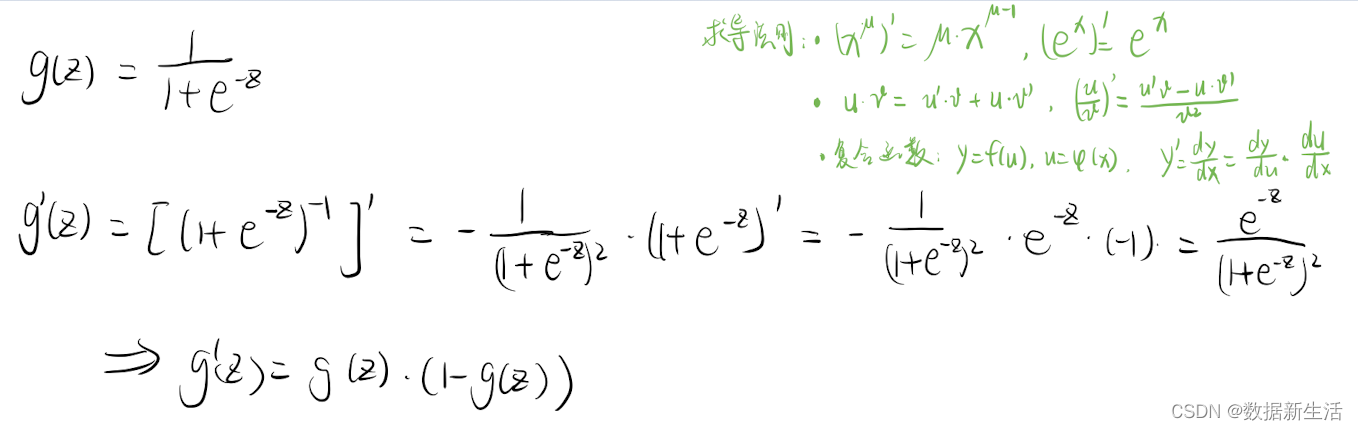
公式推导
似然函数=>求对数=>LR的损失函数=>梯度下降求解参数

- 参数更新公式:对损失函数进行求偏导得到

-
什么时候迭代停止

-
模型学习训练的本质
通过带有n个特征{ x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn}的观测样本的拟合参数{ θ 1 , θ 2 . . . θ n \theta_1,\theta_2...\theta_n θ1,θ2...θn},拟合出参数就得到了z曲线,也就得到了模型的决策边界来进行分类,参数的拟合就是模型训练学习的本质。
如果z是二元一次函数,则决策边界就是一条直线,将二维平面进行分类划分。训练集不可以定义决策边界,只是负责去拟合参数,尽可能地贴近真实。
sigmoid函数
g
(
z
)
=
s
i
g
m
o
i
d
(
z
)
=
1
1
+
e
−
z
,
z
∈
(
−
∞
,
+
∞
)
,
g
(
z
)
∈
(
0
,
1
)
g(z)=sigmoid(z)=\frac{1}{1+e^{-z}}, z\in(-\infin,+\infin), g(z)\in(0,1)
g(z)=sigmoid(z)=1+e−z1,z∈(−∞,+∞),g(z)∈(0,1)
sigmoid函数特点:g’=g(1-g)
 在这里插入图片描述
在这里插入图片描述
避免过拟合
降低模型复杂度
加入L1/L2正则项
对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)
- L1正则化指权值向量 θ \theta θ中各个元素的绝对值之后,通常表示为 + α ∥ θ ∥ 1 +\alpha\lVert\theta\rVert_1 +α∥θ∥1
- L2正则化指权值向量 θ \theta θ中各个元素的平方和然后再求平方根之后,通常表示为 + α ∥ θ ∥ 2 2 +\alpha\lVert\theta\rVert_2^{ 2} +α∥θ∥22
正则化的作用
- L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
可参考:
增加训练数据
使用逻辑回归模型进行多分类的几种方式
One vs One
多个类别中抽出2个类别,训练分类器,训练 C 2 k C^{k}_2 C2k个分类器,记录每个分类器的预测结果(投票),取票数多的作为最终类
One vs All
依次选择所有类别中的一个类别作为1,其余均作为0,来训练分类器,最终几个类别得到几个分类器。根据每个分类器对其对应的类别1的概率排序,得到概率最高的类别作为最终预测结果
具体可以参考Appendix
代码实现
逻辑回归的梯度下降求解
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from numpy import exp
from sklearn import datasets
import os
import math
dataX=datasets.load_iris()['data'][0:100]
dataY=datasets.load_iris()['target'][0:100]
# sigmoid函数
def sigmoid(X):
return 1.0/(1+exp(-X))
# 损失函数
def lossFunc(x,y,weights):
lossSum=0 # 损失函数
for i in range(len(y)):
#y估计值=theta0*x0+theta1*x1+theta2*x2,其中,weights=[theta0,theta1,theta2]
y_hat=sum(np.dot(x[i,:],weights))
#事件发生的概率
prob=sigmoid(y_hat)
#print(prob)
#损失函数
lossSum+=-y[i]*np.log(prob)-(1-y[i])*np.log(1-prob) # J(theta)
return lossSum/float(len(x))
def LR_Descending(x,y,maxstep,esp,alpha):
'''
@matstep: 最大迭代次数
@esp:阈值,当权重差小于阈值时,不再迭代
@alpha:学习率
'''
m,n=x.shape
lossList=[]
# 初始化权重
weights=np.ones((n, 1))
for i in range(maxstep):
loss = lossFunc(x, y, np.array(weights))
lossList.append(loss)
y_hat=sigmoid(np.mat(x)*weights) # 矩阵计算
err=y_hat-np.mat(y).T # n*1
weights_new=weights-alpha*np.mat(x).T*err # 参数更新公式, alpha*(feature,n)*(n,1)=(feature,1)
#print('weightsnew:%s'%weights_new)
#print('loss:%s'%+loss)
loss_after=lossFunc(x, y, np.array(weights_new))
#print('loss_after:%s'%loss_after)
if abs(loss_after-loss)<esp:
break
else:
weights=weights_new
return lossList,np.array(weights),y_hat
# 训练
lossList1,weight1,y_hat=LR_Descending(x=dataX,y=dataY,maxstep=1000,esp=0.0001,alpha=0.0001)
# 绘图
fig, ax1 = plt.subplots()
ax1.scatter(range(len(lossList1)),lossList1)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









