




import tkinter as tk
from tkinter import filedialog, messagebox
import openpyxl
import re
import os # 新增os模块导入
from openpyxl import Workbook
from tkinter import ttk # 新增ttk导入
current_file_path = ""
time_based_projects = {'50米', '耐力跑'}
# 在文件开头添加新的导入
from tkinter import scrolledtext
# 在全局范围定义按钮对象
export_btn = None # 新增全局变量声明
open_btn = None
export_dist_btn = None
# 新增:创建主界面表格
# def create_views_table(root):
# frame = tk.Frame(root)
# frame.pack(pady=10)
#
# # 创建Treeview组件
# tree = ttk.Treeview(frame, height=10)
# tree["columns"] = ("序号", "班级", "实在人数", "检测人数", "优秀人数", "优秀率",
# "良好人数", "良好率", "合格人数", "合格率", "不合格人数", "不合格率", "总分合计")
#
# # 设置列属性
# tree.column("#0", width=0, stretch=tk.NO)
# columns = [
# ("序号", 50), ("班级", 80), ("实在人数", 80), ("检测人数", 80),
# ("优秀人数", 80), ("优秀率", 80), ("良好人数", 80), ("良好率", 80),
# ("合格人数", 80), ("合格率", 80), ("不合格人数", 80), ("不合格率", 80), ("总分合计", 100)
# ]
# for col, width in columns:
# tree.column(col, width=width, anchor='center')
# tree.heading(col, text=col)
#
# # 添加滚动条
# vsb = tk.Scrollbar(frame, orient="vertical", command=tree.yview)
# tree.configure(yscrollcommand=vsb.set)
#
# tree.grid(row=0, column=0, sticky='nsew')
# vsb.grid(row=0, column=1, sticky='ns')
# return tree
# 修改后的create_views_table函数
def create_views_table(parent):
frame = ttk.Frame(parent)
frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
# 创建带样式的Treeview
style = ttk.Style()
style.configure("Treeview.Heading", font=('微软雅黑', 10, 'bold'))
style.configure("Treeview", font=('微软雅黑', 9), rowheight=25)
columns = ("序号", "班级", "实在人数", "检测人数", "优秀人数", "优秀率",
"良好人数", "良好率", "合格人数", "合格率", "不合格人数", "不合格率", "总分合计")
tree = ttk.Treeview(frame, columns=columns, show="headings", selectmode="browse")
# 配置列
col_widths = [50, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 100]
for col, width in zip(columns, col_widths):
tree.heading(col, text=col)
tree.column(col, width=width, anchor='center')
# 添加滚动条
vsb = ttk.Scrollbar(frame, orient="vertical", command=tree.yview)
hsb = ttk.Scrollbar(frame, orient="horizontal", command=tree.xview)
tree.configure(yscrollcommand=vsb.set, xscrollcommand=hsb.set)
# 布局
tree.grid(row=0, column=0, sticky="nsew")
vsb.grid(row=0, column=1, sticky="ns")
hsb.grid(row=1, column=0, sticky="ew")
# 配置网格权重
frame.grid_rowconfigure(0, weight=1)
frame.grid_columnconfigure(0, weight=1)
return tree
# 新增:计算成绩分布
def calculate_distribution():
#添加弹出消息框,提醒用户确定手工处理过上面处理后的文件
messagebox.showinfo("提示", "请确认已手工处理,并检查了过上一步生成的文件!请查看操作说明中第二步★中的提示。")
global export_dist_btn
global distribution_data
file_path = filedialog.askopenfilename(filetypes=[("Excel文件", "*.xlsx")])
if not file_path:
return
try:
wb = openpyxl.load_workbook(file_path)
sheet = wb.worksheets[0]
except Exception as e:
messagebox.showerror("错误", f"文件打开失败:{str(e)}")
return
# 确定列索引
header = [cell.value for cell in sheet[1]]
try:
class_col = header.index("班级") + 1
total_score_col = header.index("合计") + 1 # 按列名定位合计列
score_cols = [i + 1 for i, h in enumerate(header) if "得分" in str(h)]
except ValueError:
messagebox.showerror("错误", "表格必须包含'班级'和'合计'列!")
return
# 统计班级数据
class_data = {}
# 先统计实在人数(班级列出现次数)
for row in sheet.iter_rows(min_row=2):
class_name = row[class_col - 1].value
if class_name:
if class_name not in class_data:
class_data[class_name] = {
'total': 0,
'valid': 0,
'scores': [],
'grades': {'优秀': 0, '良好': 0, '合格': 0, '不合格': 0}
}
class_data[class_name]['total'] += 1
# 再统计有效数据
for row in sheet.iter_rows(min_row=2):
class_name = row[class_col - 1].value
if not class_name:
continue
# 检测有效数据
valid = all(row[col - 1].value is not None for col in score_cols)
if valid:
class_data[class_name]['valid'] += 1
try:
total_score = float(row[total_score_col - 1].value)
except:
continue
# 统计等级(修正区间判断)
if total_score >= 90:
class_data[class_name]['grades']['优秀'] += 1
elif 80 <= total_score < 90: # 良好:80<=x<90
class_data[class_name]['grades']['良好'] += 1
elif 60 <= total_score < 80: # 合格:60<=x<80
class_data[class_name]['grades']['合格'] += 1
else: # 不合格:x<60
class_data[class_name]['grades']['不合格'] += 1
# 生成最终数据
distribution_data = []
for idx, (class_name, data) in enumerate(sorted(class_data.items()), 1):
valid_count = data['valid']
grades = data['grades']
distribution_data.append([
idx,
class_name,
data['total'], # 实在人数(班级出现次数)
valid_count,
grades['优秀'],
f"{grades['优秀'] / valid_count:.2%}" if valid_count else "0.00%",
grades['良好'],
f"{grades['良好'] / valid_count:.2%}" if valid_count else "0.00%",
grades['合格'],
f"{grades['合格'] / valid_count:.2%}" if valid_count else "0.00%",
grades['不合格'],
f"{grades['不合格'] / valid_count:.2%}" if valid_count else "0.00%",
sum(data['scores'])
])
# 更新Treeview
views.delete(*views.get_children())
for item in distribution_data:
views.insert("", "end", values=item)
export_dist_btn.config(state=tk.NORMAL)
# 新增:导出成绩分布
def export_distribution():
if not distribution_data:
messagebox.showwarning("警告", "没有可导出的数据!")
return
file_path = filedialog.asksaveasfilename(
defaultextension=".xlsx",
filetypes=[("Excel文件", "*.xlsx")]
)
if not file_path:
return
wb = Workbook()
ws = wb.active
ws.title = "成绩分布"
# 写入标题行
headers = ["序号", "班级", "实在人数", "检测人数", "优秀人数", "优秀率",
"良好人数", "良好率", "合格人数", "合格率", "不合格人数", "不合格率", "总分合计"]
ws.append(headers)
# 写入数据
for row in distribution_data:
ws.append(row)
# 保存文件
try:
wb.save(file_path)
messagebox.showinfo("成功", f"文件已保存到:{file_path}")
except Exception as e:
messagebox.showerror("错误", f"保存失败:{str(e)}")
def calculate_score(student_value, project_name, standard_scores):
"""根据评分标准计算得分(修正倒序项目处理)"""
try:
student_value = float(student_value)
print(f"开始计算项目 {project_name},原始值:{student_value}")
except:
return None
is_time_based = project_name in time_based_projects
# 修改排序方式:时间类项目按数值升序排列(数值越小越好)
sorted_scores = sorted(standard_scores, key=lambda x: x[1], reverse=not is_time_based)
if not sorted_scores:
return None
# 修正边界值判断逻辑
if is_time_based:
# 时间类:数值越小越好
if student_value <= sorted_scores[0][1]: # 优于最高标准
return sorted_scores[0][0]
if student_value >= sorted_scores[-1][1]: # 差于最低标准
return sorted_scores[-1][0]
else:
# 普通项目:数值越大越好
if student_value >= sorted_scores[0][1]: # 优于最高标准
return sorted_scores[0][0]
if student_value <= sorted_scores[-1][1]: # 差于最低标准
return sorted_scores[-1][0]
# 修正区间查找逻辑
lower_score, upper_score = None, None
for i in range(len(sorted_scores) - 1):
current = sorted_scores[i]
next_val = sorted_scores[i + 1]
if is_time_based:
# 时间类:检查是否在 current <= value <= next_val 区间
if current[1] <= student_value <= next_val[1]:
lower_score = current # 实际对应更高分数
upper_score = next_val # 实际对应更低分数
break
else:
# 普通项目:检查是否在 next_val <= value <= current 区间
if next_val[1] <= student_value <= current[1]:
lower_score = current
upper_score = next_val
break
if not lower_score or not upper_score:
return None
# 修正插值计算逻辑
if is_time_based:
# 时间类:数值越大分数越低
score_diff = lower_score[0] - upper_score[0]
val_diff = upper_score[1] - lower_score[1]
ratio = (student_value - lower_score[1]) / val_diff
final_score = lower_score[0] - ratio * score_diff
else:
# 普通项目:数值越大分数越高
score_diff = lower_score[0] - upper_score[0]
val_diff = lower_score[1] - upper_score[1]
ratio = (student_value - upper_score[1]) / val_diff
final_score = upper_score[0] + ratio * score_diff
print(f"计算明细:{lower_score} -> {upper_score} | 比率:{ratio:.2f} | 原始分:{final_score:.1f}")
return int(final_score)
def get_standard_scores(wb, sheet_name, grade):
"""获取评分标准数据"""
print(f"\n正在获取评分标准:{sheet_name} 年级:{grade}")
if sheet_name not in wb.sheetnames:
print(f"警告:找不到评分表 {sheet_name}")
return None
sheet = wb[sheet_name]
grade_col = None
# 查找年级列
header = next(sheet.iter_rows(min_row=1, max_row=1, values_only=True))
print("评分表标题行:", header)
for idx, col in enumerate(header):
if col == grade:
grade_col = idx
break
if grade_col is None:
print(f"在 {sheet_name} 中找不到年级列:{grade}")
return None
print(f"找到 {grade} 在第 {grade_col + 1} 列")
# 读取数据
scores = []
for row_idx, row in enumerate(sheet.iter_rows(min_row=2, values_only=True), start=2):
try:
score = float(row[0])
value = float(row[grade_col])
scores.append((score, value))
print(f"行 {row_idx}: 分数 {score} → 值 {value}")
except Exception as e:
print(f"行 {row_idx} 数据格式错误:{row}")
continue
print(f"共读取到 {len(scores)} 条有效评分标准")
return scores
def export_scores():
global current_file_path
if not current_file_path:
messagebox.showwarning("警告", "请先打开成绩文件!")
return
print("\n" + "=" * 50)
print("开始导出成绩计算...")
try:
print(f"正在加载文件:{current_file_path}")
wb = openpyxl.load_workbook(current_file_path)
except Exception as e:
messagebox.showerror("错误", f"文件打开失败:{str(e)}")
return
# 验证总表
total_sheets = [s for s in wb.sheetnames if re.match(r'^[一二三四五六]年级_总表$', s)]
if not total_sheets:
messagebox.showerror("错误", "未找到有效的总表!")
return
print(f"找到总表:{total_sheets[0]}")
total_sheet = wb[total_sheets[0]]
# 解析年级
grade_match = re.match(r'^(\D)年级_总表$', total_sheets[0])
if not grade_match:
messagebox.showerror("错误", "总表名称格式不正确!")
return
grade_cn = grade_match.group(1)
grade = f"{grade_cn}年级"
print(f"当前年级:{grade}")
# 项目配置
projects = [
{'name': '肺活量', 'val_col': 6, 'score_col': 7},
{'name': '50米', 'val_col': 8, 'score_col': 9},
{'name': '坐位体前屈', 'val_col': 10, 'score_col': 11},
{'name': '跳绳', 'val_col': 12, 'score_col': 13},
{'name': '仰卧起坐', 'val_col': 14, 'score_col': 15},
{'name': '耐力跑', 'val_col': 16, 'score_col': 17},
]
print("项目配置:")
for p in projects:
print(f"{p['name']}: 值列 {p['val_col'] + 1} → 分列 {p['score_col'] + 1}")
# 遍历数据行
print("\n开始处理学生数据:")
for row_idx, row in enumerate(total_sheet.iter_rows(min_row=2), start=2):
try:
name = row[2].value
gender = row[3].value
print(f"\n处理第 {row_idx} 行:{name} ({gender})")
if gender not in ['男', '女']:
print(f"性别异常:{gender},跳过此行")
continue
for project in projects:
val_cell = row[project['val_col']]
score_cell = row[project['score_col']]
if not val_cell.value:
print(f"{project['name']} 无数据,跳过")
continue
print(f"\n处理项目:{project['name']}")
print(f"原始值:{val_cell.value}(单元格 {val_cell.coordinate})")
sheet_name = f"{gender}生_{project['name']}"
standard = get_standard_scores(wb, sheet_name, grade)
if not standard:
print(f"缺少评分标准,跳过")
continue
final_score = calculate_score(val_cell.value, project['name'], standard)
if final_score is not None:
print(f"写入分数:{final_score} → {score_cell.coordinate}")
score_cell.value = final_score
else:
print("计算失败,保持原值")
except Exception as e:
print(f"处理第 {row_idx} 行时发生错误:{str(e)}")
continue
# 保存到新文件
try:
new_file_path = os.path.splitext(current_file_path)[0] + "_处理后.xlsx"
print(f"\n正在保存到新文件:{new_file_path}")
wb.save(new_file_path)
messagebox.showinfo("完成", f"成绩计算完成!\n已保存到:{new_file_path}")
except Exception as e:
messagebox.showerror("错误", f"文件保存失败:{str(e)}")
def open_excel_file():
global export_btn # 明确声明使用全局变量
global current_file_path
file_path = filedialog.askopenfilename(
filetypes=[("Excel文件", "*.xlsx")],
title="选择成绩文件"
)
if not file_path:
return
current_file_path = file_path
try:
wb = openpyxl.load_workbook(file_path)
messagebox.showinfo("成功", "文件已加载,可以开始计算!")
export_btn.config(state=tk.NORMAL)
except Exception as e:
messagebox.showerror("错误", f"文件打开失败:{str(e)}")
#以下为检查代码
def check_excel_file():
global open_btn # 明确声明使用全局变量
file_path = filedialog.askopenfilename(
filetypes=[("Excel文件", "*.xlsx")],
title="选择成绩文件"
)
if not file_path:
return
try:
wb = openpyxl.load_workbook(file_path)
except Exception as e:
messagebox.showerror("错误", f"文件打开失败:{str(e)}")
return
# 检查总表
grade_chinese = ['一', '二', '三', '四', '五', '六']
total_sheets = [s for s in wb.sheetnames
if re.match(f'^[{"".join(grade_chinese)}]年级_总表$', s)]
print(f"总表:{total_sheets}")
if total_sheets:
if validate_number_format(wb[total_sheets[0]]):
open_btn.config(state=tk.NORMAL)
def validate_number_format(sheet):
error_rows = []
for row_idx, row in enumerate(sheet.iter_rows(min_row=2), start=2): # 从第2行开始
for cell in row[4:]: # 前3列为基本信息,从第4列开始验证
if cell.value is None:
continue
if not isinstance(cell.value, (int, float)):
error_rows.append(row_idx)
break
if error_rows:
message = f"总表中以下行包含非数字数据:\n{', '.join(map(str, error_rows))}"
messagebox.showwarning("格式错误", message)
return False
else:
messagebox.showinfo("成功", "数据格式正确!")
return True
# 在创建GUI部分添加说明面板
def create_gui():
global open_btn, export_btn ,export_dist_btn # 新增:声明使用全局变量
root = tk.Tk()
root.title("体育成绩管理系统 v2.0")
root.geometry("1200x800")
# 创建说明面板
instruction_frame = ttk.LabelFrame(root, text="操作说明", padding=10)
instruction_frame.pack(fill=tk.X, padx=10, pady=5)
# 创建带滚动条的说明文本
instr_text = scrolledtext.ScrolledText(
instruction_frame,
wrap=tk.WORD,
height=8,
font=('微软雅黑', 10),
foreground="#444"
)
instr_text.pack(fill=tk.BOTH, expand=True)
# 插入格式化说明内容
instructions = """【操作流程指南】
1. 数据预处理阶段:
> 多次点击“检查成绩文件”按钮,直到没有错误弹窗
※ 手工自动检查:性别列是否为空。数据格式是否正确
※ 必须处理完所有错误才能进行下一步
2. 成绩计算阶段:
① 点击“打开成绩文件”选择处理后的文件
② 点击“导出计算结果”生成带合计列的新文件
★ 重要操作:在生成的新文件中:
- 检查所有"得分"列必须为数字
- 合计列如果使用公式,请复制→粘贴为数值覆盖原列
- 保存文件后才能进行下一步
3. 统计分析阶段:
① 点击“计算成绩分布”选择上一步保存的文件
② 在下方表格中核对预览结果
③ 确认无误后点击“导出成绩分布”生成最终报告
【注意事项】
● 红色文字标注的步骤为关键操作点
● 每次保存文件后请确认关闭Excel程序
● 合计列必须为纯数值,不能包含公式"""
instr_text.insert(tk.INSERT, instructions)
instr_text.configure(state=tk.DISABLED) # 设为只读
# 高亮关键文本
instr_text.tag_configure("warning", foreground="red")
start = instructions.index("必须处理完所有错误")
end = start + len("必须处理完所有错误")
instr_text.tag_add("warning", f"1.{start}", f"1.{end}")
start = instructions.index("粘贴为数值覆盖原列")
end = start + len("粘贴为数值覆盖原列")
instr_text.tag_add("warning", f"8.{start}", f"8.{end}")
# 原有按钮布局(添加样式修饰)
btn_frame = ttk.Frame(root)
btn_frame.pack(pady=10, fill=tk.X)
style = ttk.Style()
style.configure("TButton", font=('微软雅黑', 10), padding=6)
style.map("TButton",
foreground=[('active', 'blue'), ('!active', 'black')],
background=[('active', '#e1e1e1'), ('!active', '#f0f0f0')]
)
check_btn = ttk.Button(
btn_frame,
text="检查成绩文件",
command=check_excel_file,
style="TButton"
)
check_btn.pack(side=tk.LEFT, padx=5)
open_btn = ttk.Button(
btn_frame,
text="打开成绩文件",
command=open_excel_file,
style="TButton",
state=tk.DISABLED
)
open_btn.pack(side=tk.LEFT, padx=5)
export_btn = ttk.Button(
btn_frame,
text="计算导出结果",
command=export_scores,
style="TButton",
state=tk.DISABLED
)
export_btn.pack(side=tk.LEFT, padx=5)
# 新增分析按钮(与其他按钮区分样式)
analysis_btn_frame = ttk.Frame(root)
analysis_btn_frame.pack(pady=5, fill=tk.X)
style.configure("Analysis.TButton", foreground="white", background="#4CAF50")
calc_btn = ttk.Button(
analysis_btn_frame,
text="计算成绩分布",
command=calculate_distribution,
style="Analysis.TButton"
)
calc_btn.pack(side=tk.LEFT, padx=5)
export_dist_btn = ttk.Button(
analysis_btn_frame,
text="导出成绩分布",
command=export_distribution,
style="Analysis.TButton",
state = tk.DISABLED
)
export_dist_btn.pack(side=tk.LEFT, padx=5)
# 创建数据表格(优化显示)
global views
views = create_views_table(root)
return root
# 修改主程序启动方式
if __name__ == "__main__":
root = create_gui()
root.mainloop()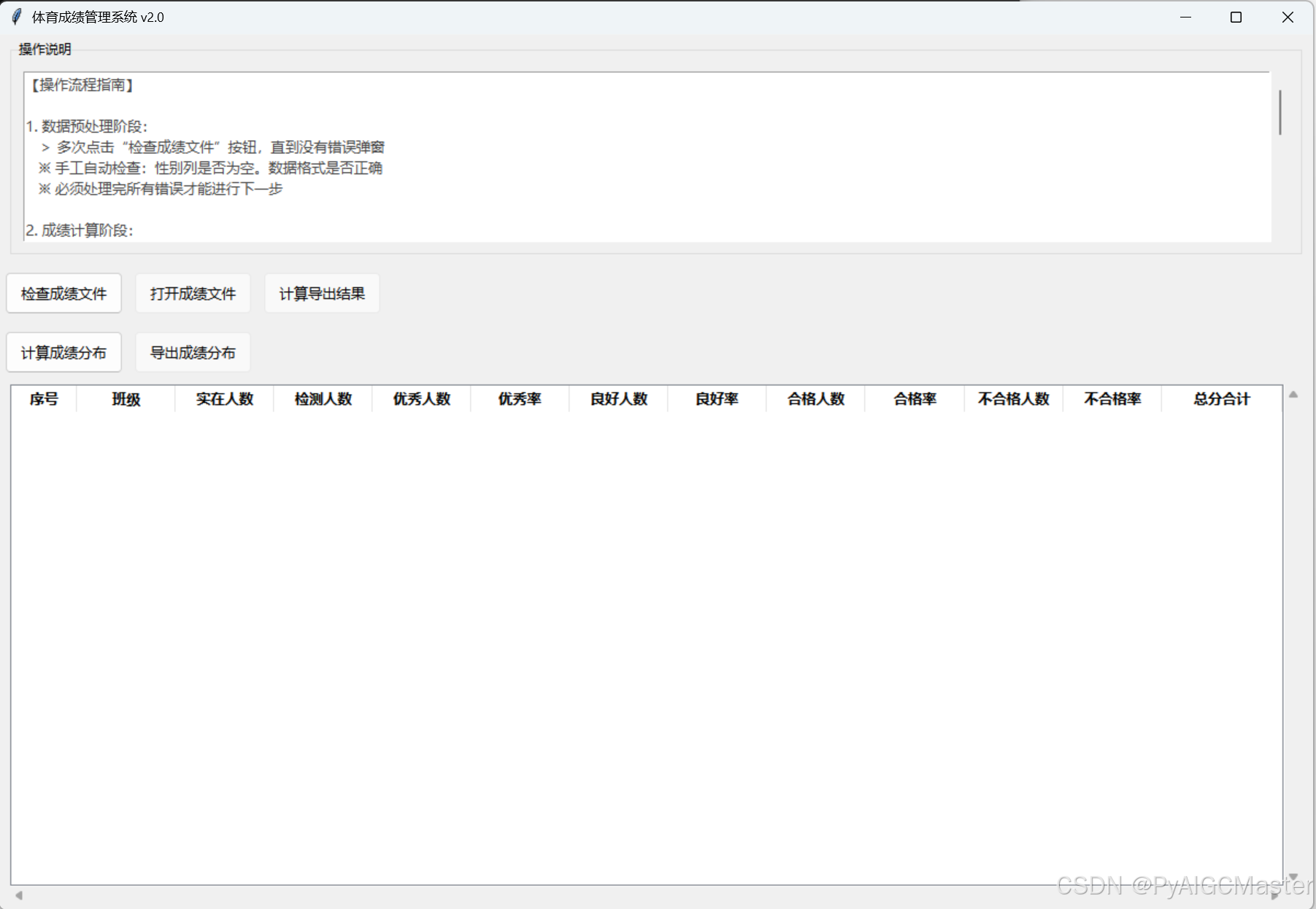
【操作流程指南】
1. 数据预处理阶段:
> 多次点击“检查成绩文件”按钮,直到没有错误弹窗
※ 手工自动检查:性别列是否为空。数据格式是否正确
※ 必须处理完所有错误才能进行下一步2. 成绩计算阶段:
① 点击“打开成绩文件”选择处理后的文件
② 点击“导出计算结果”生成带合计列的新文件
★ 重要操作:在生成的新文件中:
- 检查所有"得分"列必须为数字
- 合计列如果使用公式,请复制→粘贴为数值覆盖原列
- 保存文件后才能进行下一步3. 统计分析阶段:
① 点击“计算成绩分布”选择上一步保存的文件
② 在下方表格中核对预览结果
③ 确认无误后点击“导出成绩分布”生成最终报告【注意事项】
● 红色文字标注的步骤为关键操作点
● 每次保存文件后请确认关闭Excel程序
● 合计列必须为纯数值,不能包含公式




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











