









 博客介绍了数据库groupBy的两种分组算法,sort group需对数据全局排序后分组,hash group则直接计算分组列hash值分组。MapReduce编程中reduce端shuffle是sort group,传统数据库及hive在map端分组多采用hash group,还给出了Oracle数据库hash group的说明。
博客介绍了数据库groupBy的两种分组算法,sort group需对数据全局排序后分组,hash group则直接计算分组列hash值分组。MapReduce编程中reduce端shuffle是sort group,传统数据库及hive在map端分组多采用hash group,还给出了Oracle数据库hash group的说明。
说明:
数据库groupBy采用的分组算法有两种,sort group和hash group。前者需要对所有数据进行全局排序,然后在遍历每一条记录时,凡是与上一条记录不同的,就划分为一个新组。后者则是直接对分组列计算hash值,相同的值会被hash为一组。
MapReduce编程中reduce端shuffle就是典型的sort group。
但是,貌似现在传统型数据库的分组,以及hive在map端分组都采用的是hash group。
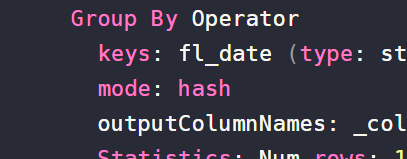
下面是找到的关于Oracle数据库hash group的一点说明。
**
Starting with 10g, Oracle introduced “Hash Group By” as the default grouping by mechanism.
Oracle employs a hash algorithm to calculate the hash value for each row based on the GROUP BY columns. This allows rows with identical column values (and hence identical hash values) to be “brought together” without performing a full sort. And then the aggregation is performed upon each group. The hash group by does not guarantee the order of the output, one should use “order by” clause to ensure the order.
——————我是一条代表翻译的分割线——————我是一条代表翻译的分割线——————我是一条代表翻译的分割线——————
从10g发布开始,Oracle进入了“hash分组”作为默认的分组机制。
Oracle使用hash算法,根据__分组__ 列的内容对每一个行计算hash值。分组列的值相等(自然hash值也相等)的行会被分到一起,而不需要进行全排序。然后在各个组上进行聚合。hash分组不会保证输出的顺序,为了确保排序顺序,请使用 order by 语句。
select time_id, sum(amount_sold) from sales group by time_id;**


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









