







 PSPNet是针对场景解析和语义分割的深度学习模型,利用金字塔池化模块获取全局上下文信息,解决了背景关系不匹配、目标种类混淆和目标忽略等问题。模型设计包括金字塔池化、ResNet的残差学习和深度监督损失函数。在ImageNet、PASCAL VOC 2012和Cityscapes数据集上表现出色。
PSPNet是针对场景解析和语义分割的深度学习模型,利用金字塔池化模块获取全局上下文信息,解决了背景关系不匹配、目标种类混淆和目标忽略等问题。模型设计包括金字塔池化、ResNet的残差学习和深度监督损失函数。在ImageNet、PASCAL VOC 2012和Cityscapes数据集上表现出色。
PSPNet-Pyramid scene parsing Network
目录
PSPNet-Pyramid scene parsing Network
5.1 ImageNet Scene Parsing Challenge 2016
1 概述
场景分割是计算机视觉里的基本任务,其目标是对图像中的每一个像素进行类别的划分,潜在应用于在自动驾驶、机器人感知等领域。我们提出的PSPNet目标分割方法,其主要优点在于:
- 基于FCN(全卷积网络)目标分割框架的基础上嵌入了复杂的背景特征。
- 基于深监督损失函数对ResNet(残差网络)提出了一种有效的最优化策略。
- 建立了一个state-of-the-art(最先进)场景解析与语义分割系统,并且包含了很多实用的实现策略。
其他相关的工作主要分为两个路线:
- 其中一条路线是进行多尺度的特征提取,因为在较深的网络当中更高层的特征包含了更多的语义信息,但是包含较少的空间位置信息。
- 另外一条路线是基于结构预测,比如说通过采用CRF(条件随机场)作为后续步骤来提取分割结果。
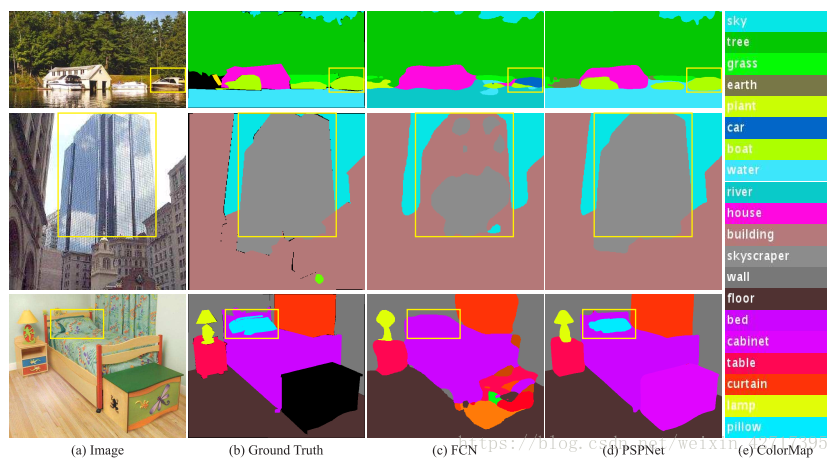
图1-1 分割结果对比
在传统FCN网络中观察到了如下现象:
- 背景关系的不匹配:从第一行的结果可以看到,FCN将在河面上的船识别为了车,缺少对背景信息的理解导致了误分类。
- 目标种类范畴的混淆:在第二行的结果中可以看到,FCN将大楼同时预测为building和skycraper。
- 目标的忽略:从第三行的结果可以看到,FCN缺少了对所有背景的理解,从而没有将床上的枕头分割出来。
总的来说,缺少对背景关系和全局信息的理解一定程度上会致使一些错误,一种全局场景级别的深度网络可以改善场景分割的表现。
2 模型设计
我们提出了金字塔池化模块,并以此来构建最终的特征层。其模型设计如图2-1所示,从中可以看到中间的金字塔池化模块分四个尺度对特征层进行池化。经过最粗略的池化,最终可以得到大小为一个bin的特征输出。其它三种池化把特征层池化成了不同的级别,分别以不同的尺寸来代表特征层,其大小分别为1*1、2*2、3*3、6*6个bin。
为了保持全局特征的权重,使用了大小为1*1的卷积核,把表示背景的特征图维度降为原来的1/N,其中N为金字塔的池化级别,本次设计中N=4。然后我们分别把低维的特征图上采样为同样大小的特征图。最终,不同大小的特征图组合成为了金字塔池化全局特征。
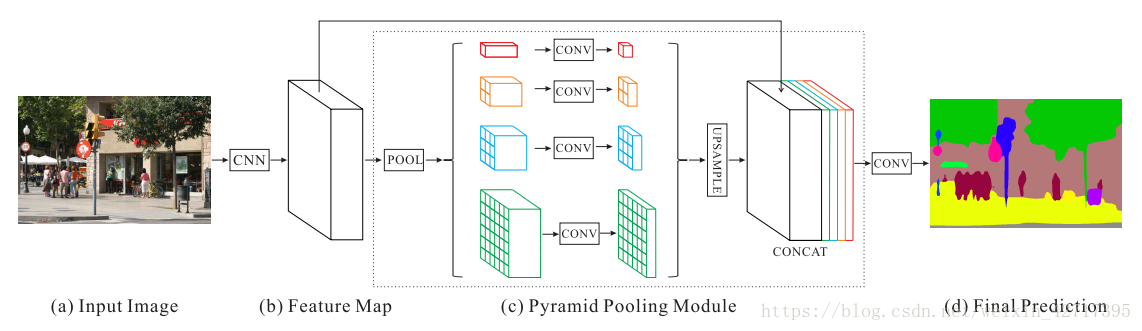
图2-1 PSPnet模型设计示意图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









